






| 一、前言 |
在"初探nodeJS"随笔中,我们对于node有了一个大致地了解,并在最后也通过一个示例,了解了如何快速地开启一个简单的服务器。
今儿,再次看了该篇随笔,发现该随笔理论知识稍多,适合初级入门node,固萌生一个想法--想在该篇随笔中,通过一步步编写一个稍大一点的node示例,让我们在整体上更加全面地了解node。
so,该篇随笔是建立在"初探nodeJS"之上的,固取名为"进阶之初探nodeJS"。
好了,侃了这多,那么我们即将实现一个什么样的示例呢?
示例说明,如下:
用户通过url之127.0.0.1/login进入登入页面,待用户输入账户名后(密码选项输不输都无所谓,只是为了页面合理),点击提交,进入home页面。
node服务端,怎么处理的呢?通过URL判断,当为/login时,服务端读取login.html的内容,并将其传递到前端显示;当为/home时,服务端读取home.html的内容,并将login.html中提交的账号名与home.html中的模板替换,最后将结果传递到前端显示。
大体流程,如下:
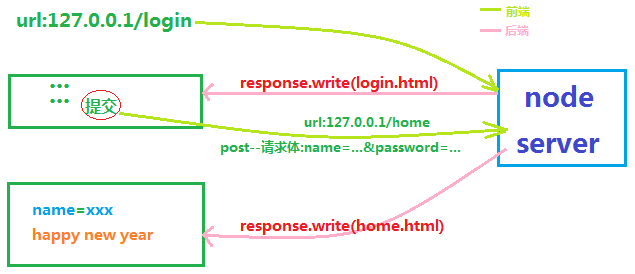
示例最终实现效果,如下:
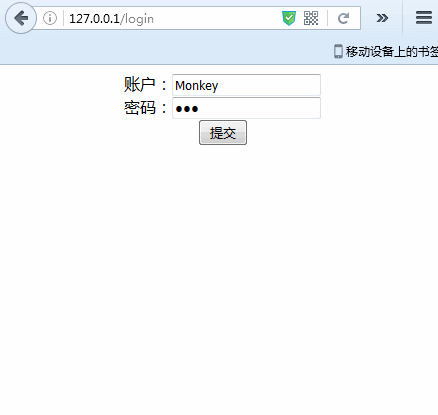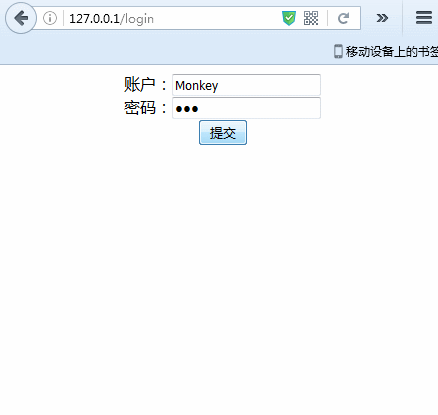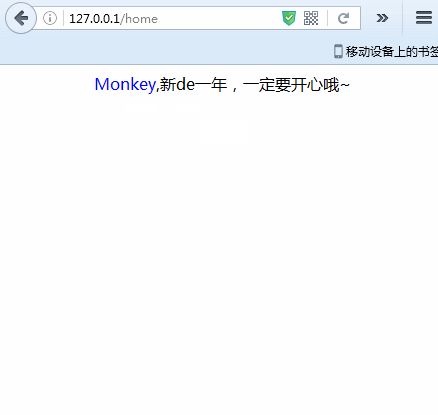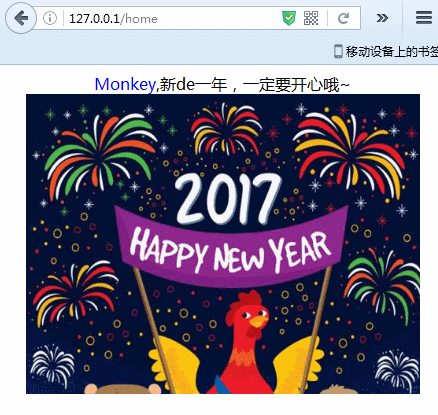
好了,了解示例需求,下面我们就一起来一步一步实现上述Demo吧。
| 二、前端文件准备 |
要实现上述效果,我们首先简单地准备两个页面login.html、home.html以及一张贺岁图片,显而易见,供接下来node读取它们并将它们呈现到浏览器中,使用。
在上述说明中,已讲过node服务器是通过路由来判断,加载哪张页面,固我们将login.html中form的action写作'./home',以达到我们的目的,请求方式嘛,使用的当然是post咯。
且,因为我们要将在login.html中填写的账户名动态地与home.html结合,固home.html中的“称呼”位置,不能写死,因此我们利用{name}来占位,随后利用node动态替换。
好了,简易编写的login.html、home.html以及贺岁图,如下:
 login.html
home.html
login.html
home.html
newYear.png

| 三、编写node服务 |
上述中,我们所需要的前端文件已经准备完毕,接下来就是通过node来编写服务,将它们串联起来咯。
首先,我们搭建一个主文件,取名为main.js吧,作用不言而喻,主入口嘛,如果我们在代码编写完毕后,想要启动服务,就node main.js就OK咯。
如下:

'use strict';
var http = require('http');
var server = http.createServer();
server.on('request',function(req, res){
//排除favicon.ico请求
if(req.url != '/favicon.ico'){
//TODO
}else{
res.end();
};
}).listen('80');
console.log('Server running!');
接着,我们就一起来逐步完善这个主文件。
在“前言”中我们提过,当一个请求来到服务中,我们采取获取URL的路径,来判断接下来的操作,已到达降低耦合性的目的。
所以,在主程序中,我们得利用url这个模块,来获得url中的相关路径,并通过正则来得到第一个路径名,通过接下来的路由模块,处理。
如下:
'use strict';
var http = require('http');
var url = require('url');
var server = http.createServer();
server.on('request',function(req, res){
if(req.url != '/favicon.ico'){
//获取路径
let pathname = url.parse(req.url).pathname;
pathname = pathname.match(/\w+/)[0];
//router具体,待写...
router[pathname](req, res);
}else{
res.end();
};
}).listen('80');
console.log('Server running!');
好了,接下来,我们就一起来编写router这个模块吧。
在我们示例中,router无外乎就是处理login、home以及图片请求getPic,所以,我们将router模块基本骨架,暂定如下:
'use strict';
var router = {
login: function(req, res){
//TODO
},
home: function(req, res){
//TODO
},
getPic: function(req, res){
//TODO
}
};
module.exports = router;
且,我们发现login、home以及getPic这三个操作,有很多共通之处,如都会读取服务端本地文件,以及将读取的文件,写入响应体中,固我们将这些操作提取出来,作为operation模块。
在operation模块中,我们需要使用到node内置'fs'这个模块来读取文件,'fs'模块我们将会用到如下方法:
1、fs.readFileSync--同步读取文件
2、fs.readFile--异步读取文件
3、fs.writeFileSync--同步写入文件
4、fs.writeFile--异步写入文件
需要注意的是,读取图片也就使用的fs.readFileSync/fs.readFile,不过就是第二个参数还需加上'binary',二进制嘛。
operation模块
另外,我们在login.html中提交表单时,使用到了post请求,那么在node服务中应该怎么接收传来的实体呢?
node是采用的监听'data'来接收post方法实体信息,通过'end'来监听接收信息完毕事件。
而,node接收get请求参数就没这么复杂,直接获取url后的查询字符串即可。
好了,我们将获取post、get请求参数,也写为一个模块,取名为getQuery,如下:
getQuery模块
最后,就是在router模块中,引入operation、getQuery模块,完善login、home以及getPic方法咯。
在这里需要注意的是getPic方法,因为是处理的图片,所以响应头得写成'image/jpeg',如下:
res.writeHead(200, {'Content-Type':'image/jpeg'});


















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









