






 本文详细探讨了MapReduce框架的第一代局限性,如扩展性不足、资源利用率低下及不支持多种计算框架等问题,并介绍了JobTracker的功能及其在资源管理和作业控制方面的不足。进一步分析了YARN作为统一资源管理和调度平台的优势,以及MapReduce作业提交、初始化流程和关键组件间的交互。
本文详细探讨了MapReduce框架的第一代局限性,如扩展性不足、资源利用率低下及不支持多种计算框架等问题,并介绍了JobTracker的功能及其在资源管理和作业控制方面的不足。进一步分析了YARN作为统一资源管理和调度平台的优势,以及MapReduce作业提交、初始化流程和关键组件间的交互。

mapreduce框架学习
第一代mapreduce局限性
扩展性差:
JobTracker同时具备了资源管理和作业控制两个功能,制约了hadoop集群扩展性
资源利用率低,mr1采用了基于槽位的资源分配模型,槽位slot是一种细粒度的资源划分单位,一个任务task不会用完槽位对应的资源,其他任务也无法使用这些空闲资源。,hadoop将槽位分为map slit和 reduce slot,不允许他们之间共享资源。
不支持多种计算框架,包括内存计算框架,流式框架,迭代计算框架
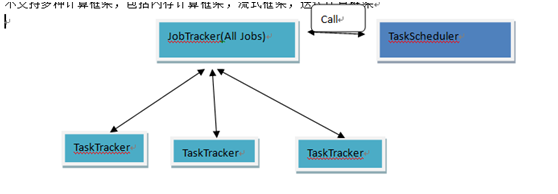
JobTracker不够灵活,
负责资源管理和作业控制:
统一资源管理和调度的平台典型代表shi yarn (yet another Resource Negotiator)
RM和AM,
yarn实际上采用的是拉式通信模型。
对于maptask 它的生命周期为scheduled->assigned->completed
对于redice task,它的生命周期为pending->scheduled-assigned->completed,
Yarn上运行mapreduce需要解决两个关键问题,如何确定reduce task 启动时机以及如何完成shuffle功能。
mapreduce通信协议类关系图
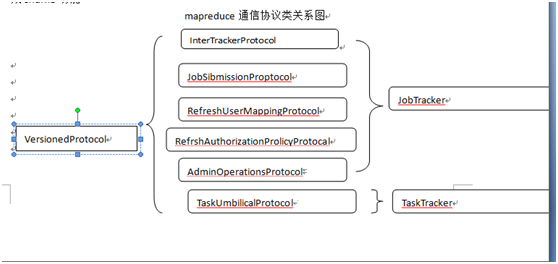
JobSubmissionProtocol是Cient与HJobTracker之间的通信协议,通过该协议查看作业运行状态。
/**
* jobName 作业id,client可以为作业获得唯一的id
* jobsubmitdir为作业文件所在的目录,hdfs上的一个目录,ts是该作业分哦诶到的秘钥或者是安全令牌
*
* @author user
*
*/
public interface JobClient {
// 作业提交
public JobStatus submitJob(JobID jobName, String jobSubmitDir, Credentials ts) throws IOException;
// 作业控制
// 修改作业优先级setJobPriority函数;杀死一个作业killJob,杀死一个任务killTask
// 查看系统状态和作业运行状态
// 当前集群状态slot总数,所有正在运行的task数目
public ClusterStatus getClusterStatus(boolean detailed) throws IOException;
// 获得某个作业的运行状态
public JobStatus getJobStatus(JobID jobid) throws IOException;
//获得所有作业运行状态
public JobStatus[] getAllJobs() throws IOException;
}
InterTarckerProtocol通信协议
是taskTracker和JobTracker之间的通信协议,向jobTracker汇报所在节点的资源使用情况和任务的运行情况,接收并执行jobTracker发送的命令。
heartbeat周期性地被调用,形成了jobTracker和TaskTracker之间的心跳
//输入TaskTrackerStatus封装所在节点资源使用情况和任务的运行情况
//输出HeartbeatResponse包含一个TaskTrakcerAtion类型的数组,包含了jobtracker向taskTracker传达的各种命令
HeartbeatResponse heartbeat(TaskTrackerStatus status, boolean restarted, boolean initialContact,boolean acceptNewTasks, boolean acceptNewTasks, short responseId) throws IOException;
TaskUmbilicalProtocol 通信协议
Task和taskTracker之间的通信协议,通过该协议汇报自己的运行状态或者出错信息。
//周期性调用方法
boolean statusUpdate(TaskAttemptID taskId, TaskStatus taskStatus, JvmContext jbmContext) throws Exception;
boolean ping(TaskAttemptID taskId, JvmContext jbmContext) throws IOException;
//按需调用方法
//task初始化,收到启动命令,LaunchTaskAction,子程序去调用getTask()方法领取对应的task.
//task运行中 reportDiagnosticInfo、fsError/fatalError分别汇报出现的Exception/FSEror/Throwble异常和错误,对于ReduceTask提供shuffleError汇报shuffle阶段出现的 错误
//reprotNextRecordRange getMapCompletionEvent从TaskTracker获得一已经完成的map task列表
//task运行完成 commitPending,canCommit ,done
hadoop白名单和黑名单, bin/hadoop mradmin –refreshNodes
作业提交和初始化
步骤:
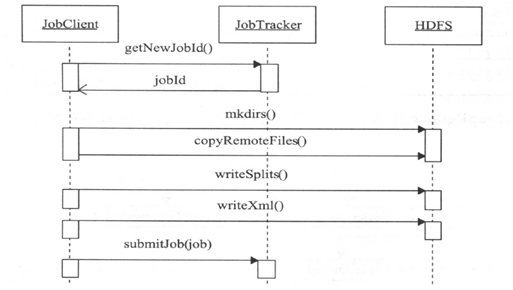
1 用户提交作业
2 将作业配置信息,将运行需要的文件上传到jobTracker文件系统中
3JobClient调用RPC接口向JobTracker提交作业
4收到作业后后告知TakScheduler,对作业进行初始化、
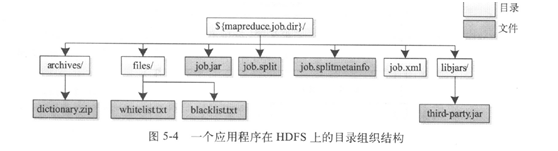
DisbutedCache负责在hdfs文件系统中文件的上传和下载。
jobClient中文件的split:
InputSplit org.apache.hadoop.maperduce.split
JobSplit ,JobSplitWriter
SplitMetaInfoReader
作业提交到JobTracker
JobClient调用rpc方法submitJob将祖业提交到JobTracker端,JobTracker的submitJon中,会有以下操作:
1为每个作业创建jobInProgress对象
2 检查用户是否有指定队列的作业提交权限
3 作业配置的内存使用量是否合理 map task,reduce task使用的内存配置
4.通知TaskScheduler初始化作业,按一定的策略去初始化作业
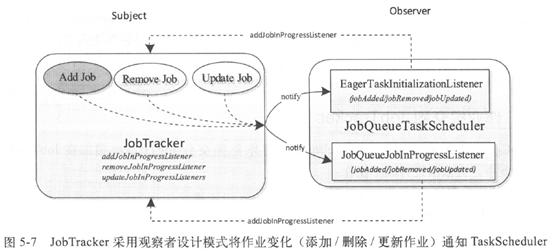
// 为每个作业创建jobInProgress对象,在作业运行时一直存在,跟踪正在运行作业的运行状态和进度
private ConcurrentHashMap<String, Object> jobs;
private Schedulable taskScheduler;
private synchronized JobStatus addJob(JobID jobId, JobInProgress job) throws Exception {
synchronized (jobs) {
synchronized (taskScheduler) {
jobs.put(job.getProfile().getJobID(), job);
for(JobInProgressListener listener:jobInProgressListeners){
listener.jobAdded(job);
}
}
}
}
public synchronized void start() throws IOException{
super.start();
//do otherthing
}
public static JobTracker startTracker(JobConf conf,String identifier) throws Exception{
//do something
result=new JobTracker(conf,indetifier);
result.taskScheduler.setTaskTackerManager(result);
//do something
}
作业初始化过程详解
taskScheduler调度器远程调用JobTracker中的initJob()对新作业进行初始化,主要工作是构造mao task和reduce task 并对他们进行初始化。
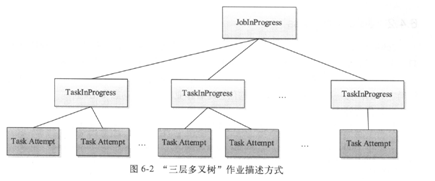
TaskInProgress对象
setupTask
map task
reduce task: map task 达到一定的数目才开始reduce task
cleanup task 删除运行过程中的一些临时目录(比如说_temporay目录),一旦该任务运行成功后,作业由Running变为succeeded状态
每一个作业运行时都会占用一个slot
Hadoop DistributedCache分发文档到taskTracker节点org.apache.hadoop.filecache
void addCacheArchive(URI uri, Configuration conf);
void setCacheArchives(URI[] archives, Configuration conf);
void addCacheFile(URI uri, Configuration conf);
void setCacheFile(URI[] files, Configuration conf);
其中的一些方法
小结:作业的提交和初始化,涉及到三个重要的组件,JobClinet,jobTracker,TaskScheduler
JobTracker内部实现
JobInProgress TaskInProgress,完成后表示整个作业就完成了。
JObTarcker启动过程:
ACLsManager类,权限管理类 队列权限 和作业权限
其中的各种线程
expireTracjersThread 清理
retireJonsThread
expireLaunchingTaskThread
completedJonsStireThread
JobTracker为关键事件记录日志,包括作业提交,作业创建,作业开始运行,作业运行完成,作业运行失败,作业被杀死,通过日志恢复这些作业的运行状态。
JoobTracker和TaskTracker之间是拉模型,
心跳:判断taskTracker是否活着
及时让JObTracker获得各个节点上的资源使用情况和任务运行状态
为TaskTracjer分配任务
jobTracker会赋予每个作业一个唯一的ID,id由三部分组成:作业前缀字符串,JobTracker启动时间和作业提交顺序,各部分通过+_+连接起来组成一个完整的作业ID :job ,201208071506,009(jobTracker运行以来的第9个作业)。
jobinprogress 作业静态信息,已经确定好的属性信息,
作业动态信息
taskinprogress
taskAttempt
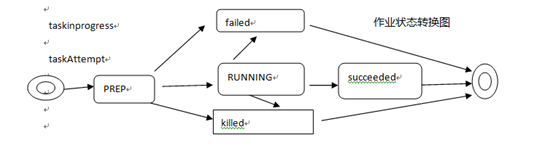
jobTracker容错机制
Task运行过程分析
IFile存储格式:支持行压缩的存储格式
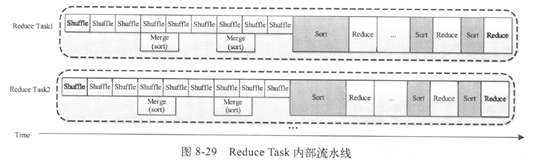
排序:map task 和reduce task都会有排序
map task 中会将结果暂时放到缓存区中,是环形的,当缓存区使用率达到一定的阈值后,再对缓存区的数据进行一次排序,将有序的数据以IFile文件的形式写到磁盘,完成后,会将所有文件进行一次合并,成为一个有序的大文件。
Reduce task 从远程每个maptask拷贝相应的数据,先放到内存,达到阈值后再合并生成更大的文件,如果内存中文件大小和数目超过一定的阈值,就会将数据写到磁盘,当所有数据拷贝完成后,对所有数据进行一次合并。
计数器
java和hadoop中计数器的实现
基于枚举类型和计数器类型的计数器api
public abstract void incrCounter(Enum<?> key,long amount);
public abstract void incrCounter(String group,String counter,long amount);
HadoopPipes::TaskContext::Counter*mapCounter;//定义
mapCOunter=context.getCounter(“counterGroup”,”mapCounter”)//注册
cotnext.incrementCounter(mapCounter,1);//使用
MapTask
单向缓存区,双向缓存区,环形缓存区
key是排序的关键字,通常需要交给RawConparator排序,要求排序关键字在内存咋红必须连续存储
通过内存复制解决不连续的问题,复制到前端,复制到后端,可能key或者value太大,以至于整个缓存区都不能容纳它,抛出异常,并将该记录单独输出到一个文件中
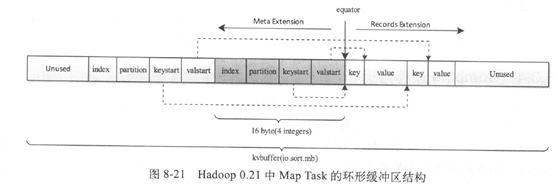
Spill溢写过程
是有SpillThread线程完成。是kvbuffer的消费者
spillLock.lock();
while(true){
spollDone.signal();
while(kvstart=kvend){
spillReady.await();
}
spillLock.unlock();
sortAndSpill();
spillLock.lock();
if(bufend<bufindex&&bufindex<bufstart){
bufvoid=kvbuffer.length;
}
vstart=kvend;
bufstart=bufend;
}
spiilLock.unlock();
当所有数据完成拷贝后,再对所有数据进行一次排序,并将key相同的记录分组依次交给reduce()程序处理。
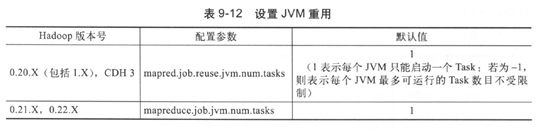
Hadoop性能调优
从几个角度来看:
管理员角度:
硬件
linux操作系统参数调优
JVM参数调优


从用户角度进行调优
合理使用DIstributedCache
当应用程序需要使用外部文件时,得到外部文件的方法有两种,一种是与jar包一起放到客户端,当作业提交时传到hdfs的某个目录下,然后通过DistributedCache分发到各个节点上,另一个方法是将外部文件直接放到hdfs上,第二种方法更高效。
跳过坏记录
提高作业优先级
HADOOP安全机制
sasl

















 2512
2512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









