






 本文介绍了一种使用Python爬取豆瓣电影排行榜的方法。通过requests库获取网页内容,并利用lxml库进行XPath解析,最终实现了对电影名称及评分的有效抓取。
本文介绍了一种使用Python爬取豆瓣电影排行榜的方法。通过requests库获取网页内容,并利用lxml库进行XPath解析,最终实现了对电影名称及评分的有效抓取。

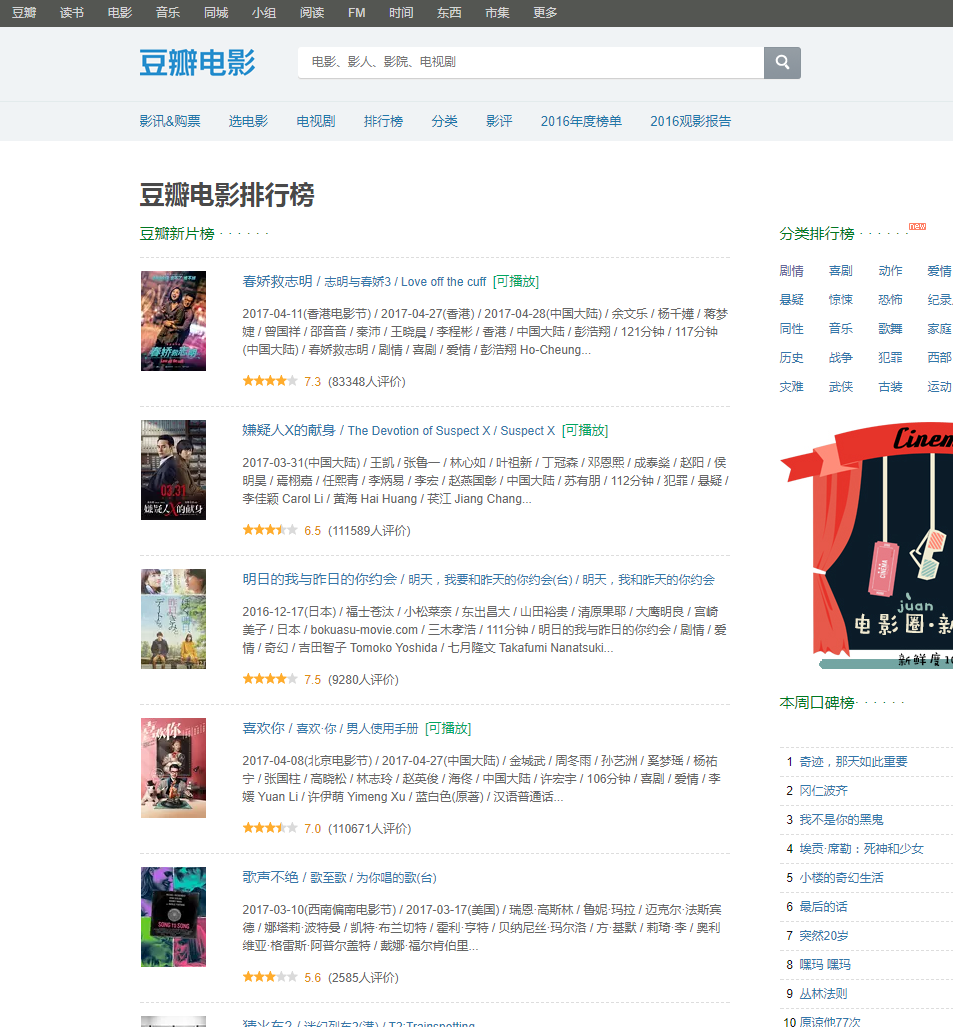
原网页
Python代码
# -*-coding:utf-8-*- #
# 爬取“豆瓣电影排行榜”
import requests # 没有的话去settings-project intercepter里下载
import json
from lxml import html # 采用lxml,即xpath方法
print '**************豆瓣新片排行榜*************'
# 请求网站,获得page
page = requests.get('https://movie.douban.com/chart')
# 对获取到的page格式化操作,方便后面用XPath来解析
tree = html.fromstring(page.text)
# XPath解析,获得需要的电影名称和评分
names = tree.xpath('//a[@class="nbg"]/@title')
points = tree.xpath('//span[@class="rating_nums"]/text()')
movies = []
# 名称转码
for index, elem in enumerate(names):
movie_name = elem.encode('utf-8')
movie = {'id': index, 'name': movie_name}
# print json.dumps(movie, ensure_ascii=False)
movies.append(movie)
# 评分转码
for index, elem in enumerate(points):
movie_point = float(elem)
movies[index]['point'] = movie_point
# print movie_point
# 打印
for movie in movies:
print json.dumps(movie, ensure_ascii=False)
结果
**************豆瓣新片排行榜*************
{"point": "7.3", "id": 0, "name": "春娇救志明"}
{"point": "6.5", "id": 1, "name": "嫌疑人X的献身"}
{"point": "7.5", "id": 2, "name": "明日的我与昨日的你约会"}
{"point": "7.0", "id": 3, "name": "喜欢你"}
{"point": "5.6", "id": 4, "name": "歌声不绝"}
{"point": "8.1", "id": 5, "name": "猜火车2"}
{"point": "6.5", "id": 6, "name": "异星觉醒"}
{"point": "6.0", "id": 7, "name": "贝尔科实验"}
{"point": "6.5", "id": 8, "name": "生化危机:复仇"}
{"point": "7.6", "id": 9, "name": "奇迹,那天如此重要"}参考:https://www.zhihu.com/question/20899988

















 3789
3789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









