



 本文详细描述了一个客户端无法连接Infor ERP Syteline系统的故障案例,通过排查发现该问题源于电脑同时存在两个网络连接,其中一个为非法的无线连接。移除非法连接后,客户端能够正常访问系统。
本文详细描述了一个客户端无法连接Infor ERP Syteline系统的故障案例,通过排查发现该问题源于电脑同时存在两个网络连接,其中一个为非法的无线连接。移除非法连接后,客户端能够正常访问系统。
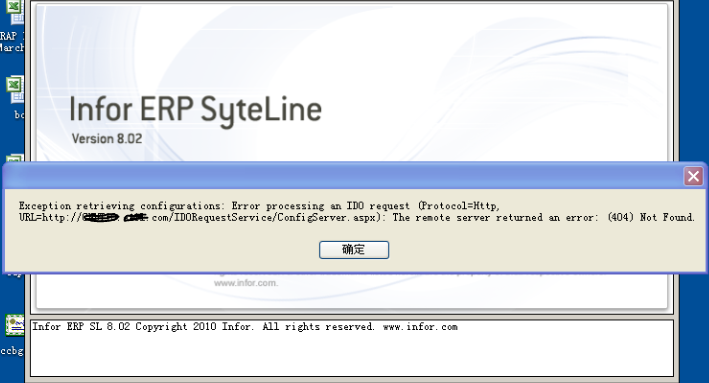
有一台客户端,不能连上Infor ERP Syteline,出现如下错误提示。但其它电脑没有相同问题,因此判定问题出于此台客户端电脑上。
Error when executing SL 8.01 Click Once Client - Exception retrieving configurations: Error processing an IDO request (Protocol=Http, URL=http://webservername/Inetpub/wwwroot/IDORequestService/ConfigServer.aspx): The remote server returned an error: (404) Not Found
检查结果,此台电脑可以访问域网络资源,如文件服务器,但一些资源无法访问,如邮件等。
Win键 + R 打开 cmd ,输入ipconfig /all 结果发现同时有两个网络连接,一个是公司的网段IP,另一个是异样的网段IP,原来用户使用了可上网的无线连接器。移除这个无线连接器,一切回归正常。


















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









