






 本文介绍了Erlang中的dict模块,一种基于散列的高效数据存储方式。通过实例演示了dict的基本操作,包括创建、存储、查询等,并对比了数组与链表的特点。
本文介绍了Erlang中的dict模块,一种基于散列的高效数据存储方式。通过实例演示了dict的基本操作,包括创建、存储、查询等,并对比了数组与链表的特点。
介绍Erlang的dict模块( dictionary),dict就是一个通过散列(hash)来存放数据的组织方式,同时dict模块还提供了完整的操作接口,类似的模块还有orddict模块。具体讲如何使用dict模块的各种常用方法之前,先来看一些基础的概念。
大家写程序如果有一段时间了,发现程序中数组和链表是使用频率很高的两种数据结构,到底如何选择全看实际应用,这里只给出数组和链表的一些基本特性的简要说明:数组进行元素查找操作很快,但是增加删除元素较慢;链表增加删减元素很快,但是查找较慢,具体的原因根据它们的存贮结构就可以看出来了。下面引用一张来自《java数据结构和算法》中图,可以给大家在选择数据结构时一个很好的参考和指南:
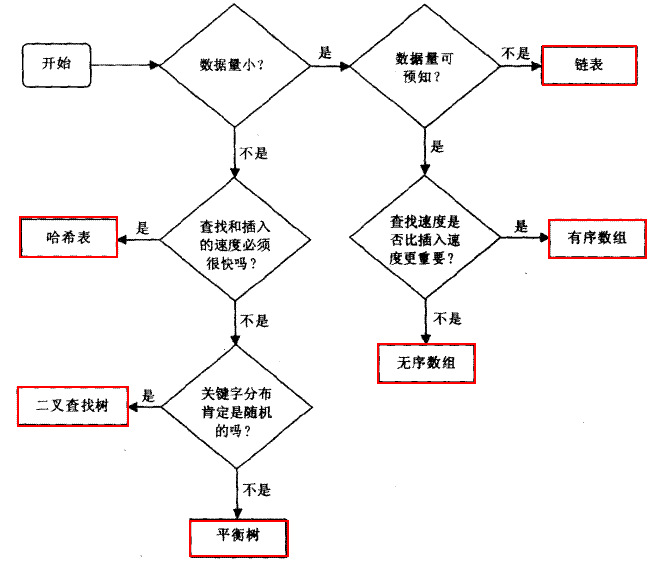
散列结构同时兼备数组的快速查询和链表的快速增减的,erlang的dict模块就提供了这种散列机制,这里需要注意的是,Erlang的 dictionary和进程字典(process dic)一样,只在节点内的一个进程内使用的,而ets可以在多个进程中共享使用(当然你也可以把ets设定为不可以让其他进程使用),下面开始看dict模块具体使用。
建立一个字典,并存储一对key-value,燃火根据key查询值:
- 6> D = dict:new().
- {dict,0,16,16,8,80,48,
- {[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]},
- {{[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]}}}
- 7> D1 = dict:store(lang,zh_cn, D).
- {dict,1,16,16,8,80,48,
- {[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]},
- {{[],[],[],[],[],[],[],
- [[lang|zh_cn]],
- [],[],[],[],[],[],[],[]}}}
- 8> dict:fetch(lang,D1).
- zh_cn
现在字典D1中就已经存放了一对key-value:lang->zh_cn,这里有个重要的特性需要指出就是字典可以作为参数在函数间传递。Dict模块的使用过程中,字典都是作为参数传递给函数,然乎返回一个新的字典,这其实就是Erlang 作为一种FP语言的一种特性---为了安全,保证变量不变。
接下来我们向字典中存贮一些更复杂的内容,比如存放一个列表:
- 17> D2 = dict:store(langs,[en,de],D1).
- {dict,2,16,16,8,80,48,
- {[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]},
- {{[],[],[],
- [[langs,en,de]],
- [],[],[],
- [[lang|zh_cn]],
- [],[],[],[],[],[],[],[]}}}
- 18> D3 = dict:append(langs,jp,D2).
- {dict,2,16,16,8,80,48,
- {[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]},
- {{[],[],[],
- [[langs,en,de,jp]],
- [],[],[],
- [[lang|zh_cn]],
- [],[],[],[],[],[],[],[]}}}
- 19> D4 = dict:append_list(langs, [han,bz,af], D3).
- {dict,2,16,16,8,80,48,
- {[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]},
- {{[],[],[],
- [[langs,en,de,jp,han,bz,af]],
- [],[],[],
- [[lang|zh_cn]],
- [],[],[],[],[],[],[],[]}}}
- 20> dict:fetch(langs,D4).
- [en,de,jp,han,bz,af]
- 21> dict:fetch(lang,D4).
- zh_cn
- 22> dict:find(langs,D4).
- {ok,[en,de,jp,han,bz,af]}
这里我们以langs这把key存贮一个由语言缩写构成的列表,并在接下来多添加了一种语言,然后又一次性添加了多种语言,最后进行查询测试。这些都很简单,但是有一点需要注意的是,从字典中查询key的值时,请使用find方法,查找成功返回{ok, values}这个tuple,失败返回 error,而fetch查找失败直接就报错了,如:
- 24> dict:fetch(langss,D4).
- ** exception error: bad argument
- in function dict:fetch/2
- called as dict:fetch(langss,
- {dict,2,16,16,8,80,48,
- {[],[],[],[],[],[],[],[],[],[],[],[],[],[],
- [],[]},
- {{[],[],[],
- [[langs,en,de,jp,han,bz,af]],
- [],[],[],
- [[lang|zh_cn]],
- [],[],[],[],[],[],[],[]}}})
- 25> dict:find(langss,D4).
- error
统计字典里面存贮了多少key:
- 35> dict:fetch_keys(D4).
- [langs,lang]
- 36> dict:size(D4).
- 2
通过一个tuple-lists结构快速构建一个字典:
- 27> KV = [{name,["zhang"]},{fav, "lol"},{location,"gz"}].
- [{name,["zhang"]}},{fav,"lol"},{location,"gz"}]
- 29> D = dict:from_list(KV).
- {dict,3,16,16,8,80,48,
- {[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]},
- {{[],[],[],[],[],
- [[name,108,117,111]],
- [[fav,108,111,108]],
- [],[],[],[],[],[],[],
- [[location,103,122]],
- []}}}
这样就初始化并且存放了值到一个字典,key-value结构和我们的KV结构一致,这里将name的值设定为一个列表,方便我们后期可以通过append和append_list来扩展。
最后还有几个有用的函数,fold,filter,map,update,用法和作用和以前介绍列表操作里面的一致。
好些文章和书籍都不推荐使用进程字典,理由是破坏了erlang的FP原则,还有些朋友曾经和我说用了进程字典后,严重影响代码的可读性。我本人觉得该用还是得用,用的时候自己注意就好,毕竟这是Erlang里面速度最快的大数据结构了吧。如果对风格和安全要求很严格的话,又想兼顾散列这种优秀性能的话,那就使用dict模块吧。
转载于:https://blog.51cto.com/10lover10/1085470

















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









