



一、Try catch
catch (Exception ex) { result.ReturnCode = ReturnCodeType.Error; result.Message = "生成失敗!"; Helper.WriteErrorLog(LogSourceType.OfflineSite, $"ForMultiOrder", $"生成多訂單异常,message:{ex.Message}\r\n StackTrace:{ex.StackTrace}"); }
Exception中 ex.message 和ex.StackTrace没有ex.ToString()的信息更准确
二、正则表达式(C#)
虽然网站项目一般都是用JS做验证,何必还要在服务器端做验证呢?
因为客户端验证是很容易被跳过的,服务器的第二次验证可以保证我们的数据极大的完整性和可靠性。
常用的正则表达式
//密码格式:数字+字母,长度超过8位。。【忽略大小写】 public static bool MatchPwd(string strPwd) { string patternPwd = @"^[\da-zA-Z]{8,}$"; return Regex.IsMatch(strPwd, patternPwd, RegexOptions.IgnoreCase); } //手机号码:手机号验证的正则表达式 public static bool MatchPhone(string strPhone) { string patternPhone = "^((13[0-9])|(15[^4])|(18[0-9])|(17[0-8])|(147,145))\\d{8}$"; return Regex.IsMatch(strPhone, patternPhone, RegexOptions.IgnoreCase); } //电子邮箱: public static bool MatchEmail(string strEmail) { string patternEmail = @"^([a-zA-Z0-9_\.\-])+\@(([a-zA-Z0-9\-])+\.)+([a-zA-Z0-9]{2,5})+$"; return Regex.IsMatch(strEmail, patternEmail, RegexOptions.IgnoreCase); } //身份证格式: public static bool MatchCardID(string strCardID) { string patternCardID = @"(^\d{15}$)|(^\d{17}(\d|X)$)"; return Regex.IsMatch(strCardID, patternCardID, RegexOptions.IgnoreCase); }
三、数字转为百分数 保留小数点后两位
- C#代码, Int/double 至少一个不是int型
ToString("0.00%"); 或者ToString("p2");
- JS代码
((a/b)*100).toFixed(2) + '%'
四、JSON序列化后含$id
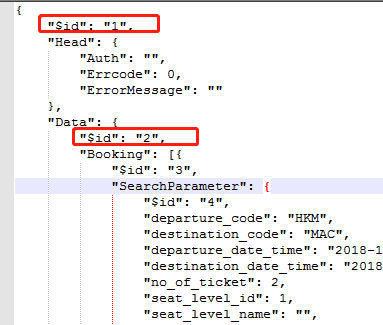
这是因为 类有[DataContract(IsReference = true)] 标识导致。。
五、?、??、?: 、?. 、各种问号的用法和说明
- 可空类型修饰符(?):
引用类型可以使用空引用表示一个不存在的值,而值类型通常不能表示为空。 例如:string str=null; 是正确的,int i=null; 编译器就会报错。
为了使值类型也可为空,就可以使用可空类型,即用可空类型修饰符"?"来表示,表现形式为"T?" 例如:int? 表示可空的整形,DateTime? 表示可为空的时间。
T? 其实是System.Nullable(泛型结构)的缩写形式,也就意味着当你用到T?时编译器编译 时会把T?编译成System.Nullable的形式。 例如:int?,编译后便是System.Nullable的形式。
2.三元(运算符)表达式(?:) :
例如:x?y:z 表示如果表达式x为true,则返回y;如果x为false,则返回z,是省略if{}else{}的简单形式。
3. 空合并运算符(??) :
用于定义可空类型和引用类型的默认值。如果此运算符的左操作数不为null,则此运算符将返回左操作数,否则返回右操作数。
例如:a??b 当a为null时则返回b,a不为null时则返回a本身。
空合并运算符为右结合运算符,即操作时从右向左进行组合的。如,“a??b??c”的形式按“a??(b??c)”计算。
4、?.
不为null时执行后面的操作。如: string name=str.Name?.ToString();
六、Where T:class 泛型类型约束
对于一个定义泛型类型为参数的函数,如果调用时传入的对象为T对象或者为T的子类,在函数体内部如果需要使用T的属性的方法时,我们可以给这个泛型增加约束;


//父类子类的定义 public class ProductEntryInfo { [Description("商品编号")] public int ProductSysNo { get; set; } //more } public class ProductEntryInfoEx : ProductEntryInfo { [Description("成份")] public string Component { get; set; } //more } //方法: private static string CreateFile<T>(List<T> list) where T:ProductEntryInfo { int productSysNo =list[0].ProductSysNo } //调用: List<ProductEntryInfo> peList = new List<ProductEntryInfo>(); string fileName = CreateFile( peList); List<ProductEntryInfoEx> checkListAll = new List<ProductEntryInfoEx>(); string fileNameEx = CreateFile(checkListAll);
这样就可以实现上边的CreateFile方法了
这样类型参数约束,.NET支持的类型参数约束有以下五种:
where T : struct T必须是一个结构类型
where T : class T必须是一个类(class)类型
where T : new() T必须要有一个无参构造函数
where T : NameOfBaseClass | T必须继承名为NameOfBaseClass的类
where T : NameOfInterface | T必须实现名为NameOfInterface的接口
分别提供不同类型的泛型约束。
可以提供类似以下约束
class MyClass<T, U>
where T : class
where U : struct
{ }
七、自动属性
属性的目的:封装字段,控制 1.读写权限 及 2.字段的访问规则(如:年龄范围)。但平时,主要是用来封装 读写权限。
- 传统:
int id; //字段
public int Id //属性
{
get { return id; }
set { id = value; }
}
- 自动属性 语法:只需要定义 无实现的属性语法 即可,不需要定义字段。
public int Id { get; set; }
public int Age { get; set; }
public string Name { get; set; }
自动属性主要用在对 字段的 读写权限的封装,帮助减少程序员代码,让代码更好看;但实质上在编译时,还是会自动生成一个对应的字段的。
所以,从这个意义上说,自动属性就相当于是微软提供的一个“语法糖”了。
- 思考:
用自动属性程序员写的代码少了,机器做的事情就多了,那我们到底要不要使用它?
如果 是针对 读写权限的封装,就推荐使用,因为它是在编译的时候产生了负担,并不是在运行的时候。(不会影响客户运行程序时的效率!)
但是编译生成的代码也有一个显而易见的缺点,语法太完整,编译后的程序集会比较大。
八、单元格分隔符(excel、csv)、科学计数法
Excel中以\t做为列分隔符,换行符作为行分隔符
使用c#导出excel的时候,当数字太长时,如身份证号,导出后的excel就会显示为科学计数法。如“511122154712121000”会显示成“5.111E+1”。
解决方法是在文本前添加一个单引号。如“'511122154712121000”。导出后显示就正常了。
CSV文件默认以英文逗号做为列分隔符,换行符作为行分隔符
将数据写入到CSV文件中--出现“科学计数法”
解决:在数据后面加上"\t"就可以。形成\t
九、科学计数字符串转为数字
/// <summary> /// 科学计数转为数字。。2.854715E-07 /// </summary> /// <param name="strData"></param> /// <returns></returns> private static Decimal ChangeDataToD(string strData) { Decimal dData = 0.0M; if (strData.Contains("E")) { dData = Convert.ToDecimal(Decimal.Parse(strData.ToString(), System.Globalization.NumberStyles.Float)); } else { dData = Decimal.Parse(strData); } return dData; }
十、判断字符串中汉字
方法1、用ASCII码判断
//在 ASCII码表中,英文的范围是0-127,而汉字则是大于127,具体代码如下:
string text = "是不是汉字,ABC,柯乐义"; for (int i = 0; i < text.Length; i++) { if ((int)text[i] > 127) { Console.WriteLine("是汉字"); } else { Console.WriteLine("不是汉字"); } }
方法2、用汉字的 UNICODE 编码范围判断
//汉字的 UNICODE 编码范围是4e00-9fbb,具体代码如下:
string text = "是不是汉字,ABC,keleyi.com"; char[] c = text.ToCharArray(); for (int i = 0; i < c.Length; i++) { if (c[i] >= 0x4e00 && c[i] <= 0x9fbb) { Console.WriteLine("是汉字"); } else { Console.WriteLine("不是汉字"); } }
方法3、用正则表达式判断
//用正则表达式判断也是用汉字的 UNICODE 编码范围,具体代码如下:
string text = "是不是汉字,ABC,keleyi.com"; for (int i = 0; i < text.Length; i++) { if (Regex.IsMatch(text[i].ToString(), @"[\u4e00-\u9fbb]+{1}")) { Console.WriteLine("是汉字"); } else { Console.WriteLine("不是汉字"); } }


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









