






 本文详细解析了HashMap的内部结构,包括其为何选择2的N次方作为容量,以及如何通过链表和红黑树优化查找性能。探讨了HashMap的扩容机制和负载因子的作用。
本文详细解析了HashMap的内部结构,包括其为何选择2的N次方作为容量,以及如何通过链表和红黑树优化查找性能。探讨了HashMap的扩容机制和负载因子的作用。

HashMap
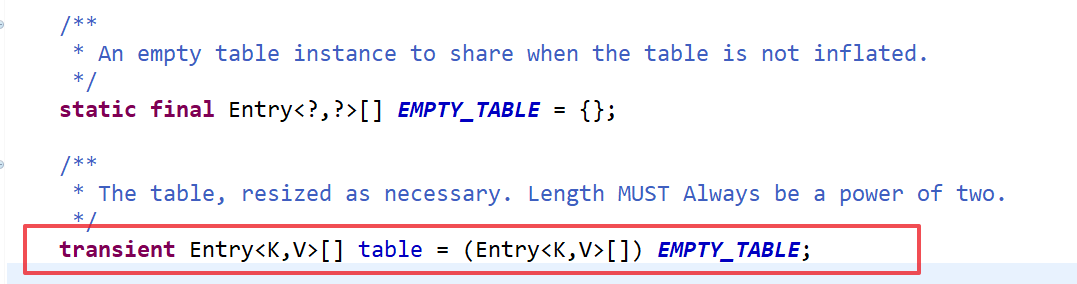
HashMap.Entry

查看Entry的属性和构造方法,可见Entry是一个链表结构。
HashMap
HashMap的容量始终是2的N次方

HashMap默认的容量和最大容量都是2的N次方。扩容的时候也是每次扩容2倍。
为什么是2的N次方:
这个跟HashMap的查找元素有关。HashMap结构是一个存储着链表的数组。HashMap使用key的hash值与数组长度取余数的方式计算key的index. 在数组长度为2的N次方的时候,取余运算可以转换为位运算,为了提高性能,HashMap中数组的容量都是2的N次方。
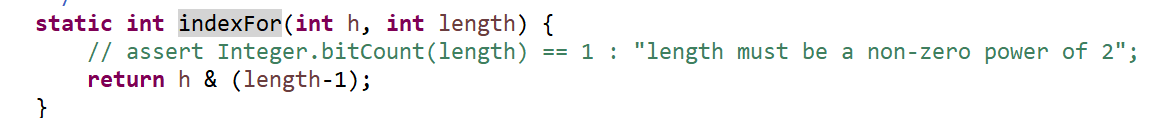
HashMap的内部结构
HashMap的内部结构是一个存储着链表的数组。
HashMap如何实现快速查找? 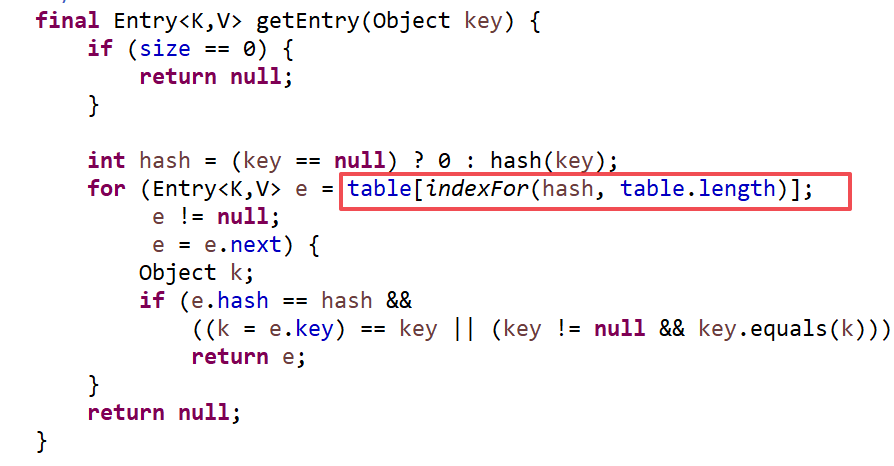

HashMap内部对key的Hash值和数组的长度取余运算(保证得到的index小于数组的长度),得到key在数组中的索引值,从而快速定位key.
如果不同key取余数后得到的index相同怎么办?
查看put方法:
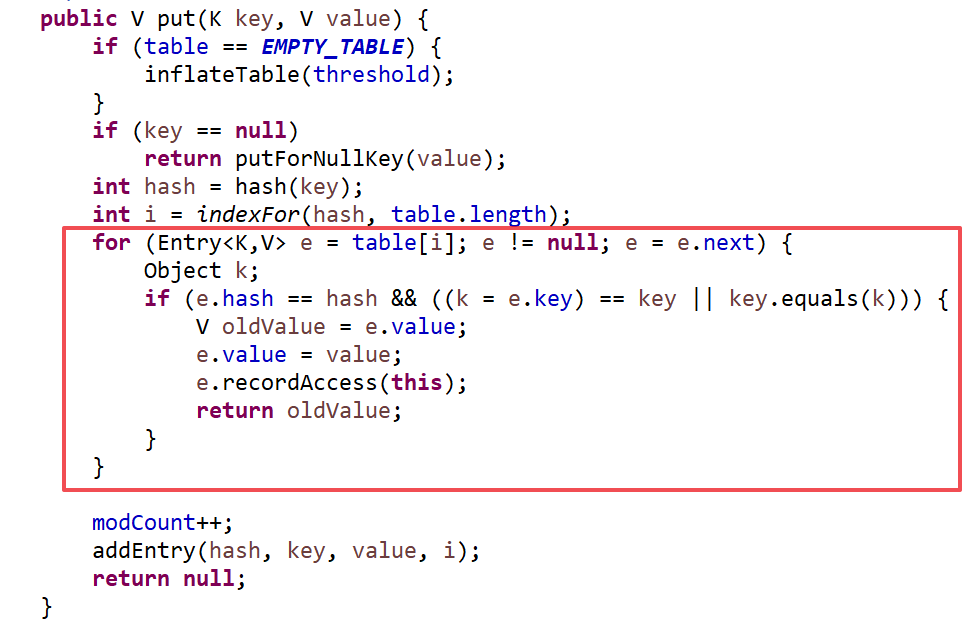
在put的时候,如果找到的index位置已经有元素了,就遍历这个位置的链表,直到找到这个当前这个key,并替换value. 如果找到不到这个key,就进入addEntry方法:
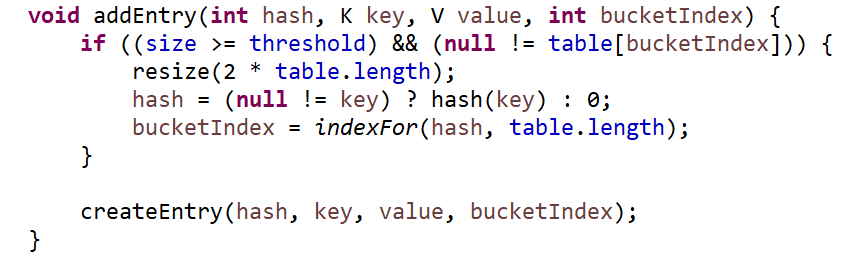
如果size>=threshold并且index这个位置有元素的话,就把数组扩容两倍。size就Entry的个数。threhold是数组长度*loadFactor(默认是0.75)。
接下来进入CreateEntry方法: 
将当前的entry放到index的位置,然后next属性指向原先这个位置的entry.(如果没有就是null).
总结:
HashMap内部元素存储方式如下: 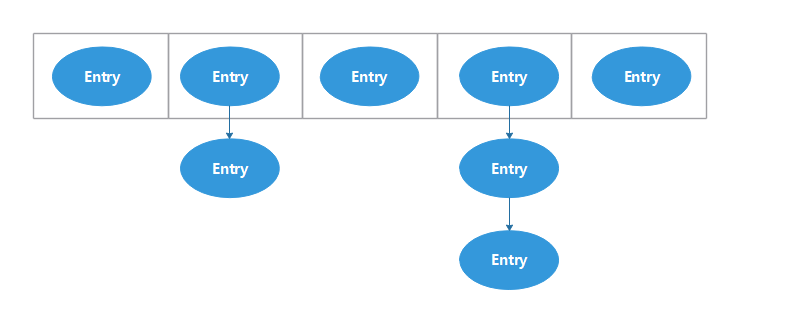
1.在数组中每个位置放的是一个链表,每个位置可能有一个或者多个entry,新put进入的entry在链表的头部;
2.数组的元素为2的n次方的好处是:方便使用位运算对key的hash值取余;
3.loadFactor这个变量用来权衡HashMap的空间大小和查询性能。如果loadFactor值比较大,那么size要更大的时候才会扩容,这样节省了内存,但查询的时候更可能定位到index后还需要遍历链表,因为节省了内存,但降低了查询性能; 反之,加大了查询性能,但更消耗空间。
HashMap所使用的Hash算法

暂时看不懂。。。
反正肯定是为了hash值求余后分布得比较均匀,最大化利用数组的空间。
java8的HashMap实现
jdk1.8中,对HashMap做了进一步优化,引入了红黑树。默认当链表长度超过8时,链表就转换为红黑树。可以利用红黑树快速增删改查的特点,提高HashMap的性能。 当红黑树节点个数小于8时,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡性,比起链表,性能上就没有什么优势了。

















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









