




类加载
类加载过程:加载-验证-准备-解析-初始化双亲委派过程
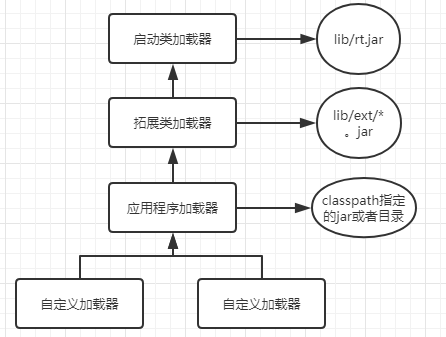
双亲委派模式的工作原理的是:
如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式
好处:
类加载具有层级关系,避免重复加载,当父类已经加载了该类时,就没有必要子ClassLoader再加载一次;而且可以防止api核心库rt.jar被随意篡改BIO/NIO/AIO 区别
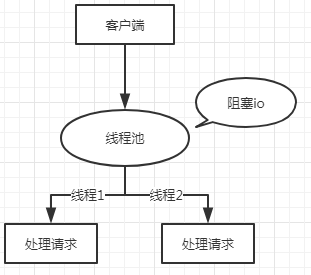
BIO(blocking input output):同步阻塞io
NIO(new input output/non blocking input outpue):非阻塞io,采用reactor模式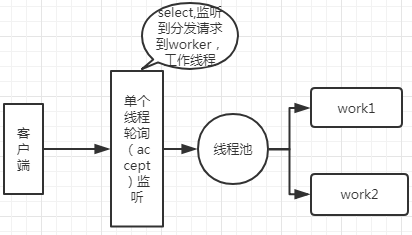
AIO:异步非阻塞io,设置监听器主动去监听请求,触发worker主动处理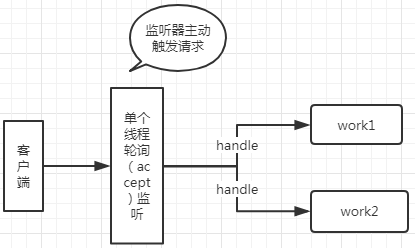
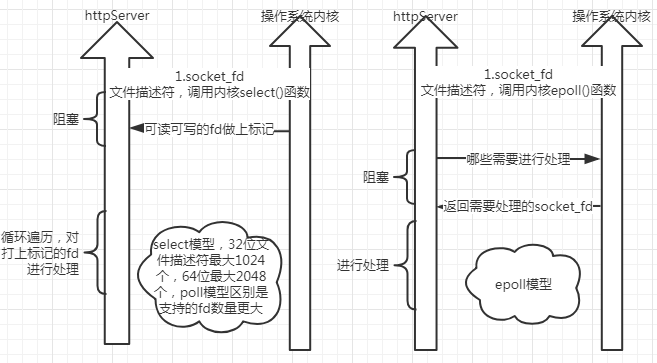
select/poll/epoll模型
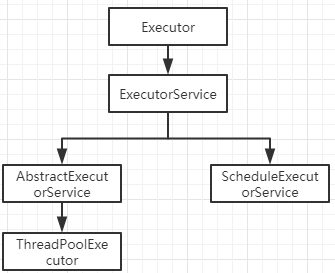
线程池
多线程实现方式:
1.继承Thread 2.实现runnable接口 3.实现callable接口和futureTask 4.线程池
线程池:
1.固定线程池newFixedThreadPool 核心线程数 = 最大线程数
2.单个线程池、newSingleThreadExecutor 核心线程数 = 最大线程数 =0
3.无限大线程池newCachedThreadPool 核心线程数0 最大线程数Integer.MAX_VALUE keepAliveTime 60L 秒
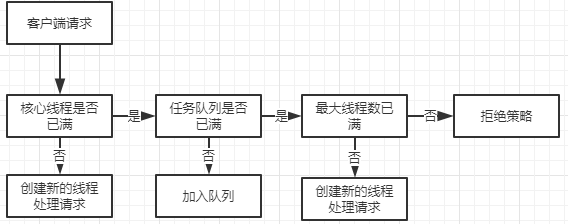
队列已满并且超过最大线程数,会触发rejectExecutorHandle拒绝策略
4.定时任务ScheduledThreadPoolExecutor, 核心线程数设置 最大线程数Integer.MAX_VALUE
关键核心参数:
corePoolSize:核心线程数,当前线程数小于核心线程数,有新的任务进来会创建新的线程
maximumPoolSize: 最大线程数,当前线程数小于最大线程数,当前核心线程数已满并且队列已满,有新的任务进来会创建新的线程
keepAliveTime:线程空闲时间,核心线程池以外的线程最大空闲时间
workQueue 用于存放任务,添加任务的时候,如果当前线程数超过了 corePoolSize,那么往该队列中插入任务,线程池中的线程会负责到队列中拉取任务。
threadFactory:线程工厂
allowCoreThreadTimeOut:允许核心线程超时
rejectedExecutionHandler:任务拒绝处理器
好处:
降低线程的创建销毁消耗,提高线程的管理性,当任务到达时,任务可以不需要等到线程创建就能立即执行,提高响应速度
提交任务:
exector:用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功
submit:用于提交需要返回值的任务.线程池会返回一个future类型对象,通过此对象可以判断任务是否执行成功
线程数的配置:
IO密集型 : cup数目 *2
Cpu密集型: cpu数目
拒绝策略执行:
workers 的数量达到了 corePoolSize,任务入队成功,以此同时线程池被关闭了,而且关闭线程池并没有将这个任务出队,那么执行拒绝策略。
workers 的数量大于等于 corePoolSize,准备入队,可是队列满了,任务入队失败,那么准备开启新的线程,可是线程数已经达到 maximumPoolSize,那么执行拒绝策略。4种缓冲队列BlockingQueue:
workQueue = new ArrayBlockingQueue<>(5);//基于数组的先进先出队列,有界
workQueue = new LinkedBlockingQueue<>();//基于链表的先进先出队列,无界
workQueue = new SynchronousQueue<>();//无缓冲的等待队列,无界
workQueue = new PriorityBlockingQueue<>();//一个支持线程优先级排序的无界队列,默认自然序进行排序,也可以自定义实现compareTo()方法来指定元素排序规则,不能保证同优先级元素的顺序。
四种拒绝策略:
RejectedExecutionHandler rejected = null;
rejected = new ThreadPoolExecutor.AbortPolicy();//默认,队列满了丢任务抛出异常
rejected = new ThreadPoolExecutor.DiscardPolicy();//队列满了丢任务不异常
rejected = new ThreadPoolExecutor.DiscardOldestPolicy();//将最早进入队列的任务删,之后再尝试加入队列
rejected = new ThreadPoolExecutor.CallerRunsPolicy();//如果添加到线程池失败,那么主线程会自己去执行该任务
避免死锁的几种方法
1.设置加锁顺序
A-B-C 加锁顺序,必须等到A和B获取锁后,才能轮到C获取
2.设置加锁时限
获取锁的时候设置一个超时时间,超时不需要再获取锁,放弃操作
3.死锁检测
避免一个线程同时获取多个锁
避免一个线程在锁内同时占用多个资源,保证每个锁只占用一个资源
尝试使用定时锁,使用lock.trylock(timeout)来代替内部锁机制
对于数据库锁,加锁和解锁必须在一个数据库连接中,否则会出现解锁失败 new Thread(new Runnable() {
@Override
public void run() {
synchronized (object1){
Thread.sleep(3000);
System.out.println("线程1未完成,等待线程2");
synchronized (object2){
System.out.println("线程1完成");
}
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
synchronized (object2){
Thread.sleep(3000);
System.out.println("线程2未完成,等待线程1");
synchronized (object1){
System.out.println("线程2完成");
}
}
}
}).start();synchronized和reentrantLock区别:
2者均是可重入锁
1.synchronized是非公平锁 ;reentrantLock 可公平可非公平
2.synchronized基于jvm ;reentrantLock基于jdk
3.在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
4.synchronized未获取到锁会一直等待;
reentrantLock 可以被中断:
a)lock(), 如果获取了锁立即返回,如果别的线程持有锁,当前线程则一直处于休眠状态,直到获取锁
b)tryLock(), 如果获取了锁立即返回true,如果别的线程正持有锁,立即返回false;
c)tryLock (long timeout, TimeUnit unit), 如果获取了锁定立即返回true,如果别的线程正持有锁,会等待参数给定的时间,在等待的过程中,如果获取了锁定,就返回true,如果等待超时,返回false;
d)lockInterruptibly:如果获取了锁定立即返回,如果没有获取锁定,当前线程处于休眠状态,直到或者锁定,或者当前线程被别的线程中断
LRU算法:最少使用算法,redis底层实现类似于lru算法
什么情况下分表?什么情况下分库?
1.垂直分表:字段太多,字段长度太大,不经常用的字段,拆字段;垂直分库:根据不同业务进行库的拆分,一个微服务对应一个数据库
2.水平分库分表:数量量大,进行水平数据的分库分表
优点:服务,业务解耦,业务清晰;提高系统稳定性和可用性,提升io
缺点:多表联合查询join,group by,排序;字段冗余;分布式事务处理复杂;全局主键避重问题(雪花算法)
Volatile
1.保证可见性,避免指令重排,一种比sychronized更轻量的同步机制,volatile并不是保证原子性
2.可见性是通过load和store指令完成,也就是对volatile变量进行写操作的时候,会在写操作加store指令,将数据刷新到主内存
执行读操作时,会在读操作加load指令,从主内存读取数据
volatile不能保证原子性:
因为从主存的拿的值然后再修改后写回主存的过程可能有其他线程已经作过这个操作了,所以导致数据会不对ThreadLocal
ThreadLocal提供了get与set等访问接口或方法,这些方法为每个使用该变量的线程都存有一份独立的副本,因为get总是返回当前执行线程在调用set时设置的最新值。
ThreadLocal<T>视为包含了Map<Thread,T>对象,其中保存了特定于该线程的值,但ThreadLocal的实现并非如此。这些特定于现场的值保存在Thread对象中,当线程终止后,这些值会作为垃圾回收。三次握手和四次挥手,5层协议, 在浏览器中输入url地址 ->> 显示主页的过程
三种常见异常:
NullPointerException - 空指针引用异常 ClassCastException - 类型强制转换异常。
IllegalArgumentException - 传递非法参数异常 ArithmeticException - 算术运算异常
IndexOutOfBoundsException - 下标越界异常 NumberFormatException - 数字格式异常
SecurityException - 安全异常 IOException--输入输出异常
NoSuchMethodException--方法未找到异常 FileNotFoundException--文件未找到异常
ArrayIndexOutOfBoundsException --数组下标越界异常 SQLException OutOfMemoryErrorSpring事务,数据库事务,隔离级别,传播性
1.事务的特性(ACID)
A:原子性;在一个事务中,要么全部成功,要么全部失败
C:一致性;在一个事务中,执行之前和执行之后数据保持一致
I:隔离性;事务直接相互隔离,互不影响
D:持久性;事务提交后,对数据库的操作不可更改,不能进行回滚
2.事务的隔离级别
读未提交:会造成脏读,不可重复读,幻读;可以读取都其他事务未提交的数据,主要针对查询操作
读已提交:会造成不可重复读,幻读;读取其他事务已经提交的数据,前后读取的数据内容不同,主要针对更新操作
可重复读:会造成幻读;解决不可重复读应该是采用行锁的形式(现实生活中,for update或者version cas)前后读取的数据条数不同,主要针对插入删除操作
串行化:无问题,采用锁表的形式,效率低
3.spring 传播行为
(1)Require:支持当前事务,如果没有事务,就建一个新的,这是最常见的
(2)Supports:支持当前事务,如果当前没有事务,就以非事务方式执行
(3)Mandatory:支持当前事务,如果当前没有事务,就抛出异常
(4)RequiresNew:新建事务,如果当前存在事务,把当前事务挂起
(5)NotSupported:以非事务方式执行操作,如果当前存在事务,就把事务挂起
(6)Never:以非事务方式执行,如果当前存在事务,则抛出异常
(7)Nested:新建事务,如果当前存在事务,把当前事务挂起。与RequireNew的区别是与父事务相关,且有一个savepointhashMap原理:
hashmap 容量为什么一定要是2的次幂:主要是为了分布均衡,增加碰撞的几率
如果length为2的次幂 则length-1 转化为二进制必定是11111……的形式,在于h的二进制与操作效率会非常的快,
而且空间不浪费;如果length不是2的次幂,比如length为15,则length-1为14,对应的二进制为1110,在于h与操作,
最后一位都为0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!这样就会造成空间的浪费
| 使用new关键字 | } → 调用了构造函数 |
| 使用Class类的newInstance方法 | } → 调用了构造函数 |
| 使用Constructor类的newInstance方法 | } → 调用了构造函数 |
| 使用clone方法 | } → 没有调用构造函数 |
| 使用反序列化 | } → 没有调用构造函数 |
ArrayList基于数组实现,LinkedList是基于双链表实现的;ArrayList多用于随机访问,查询,LinkedList多用于更新和删除Minor GC触发条件:当Eden区满时,触发Minor GC
Full GC触发条件:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法区空间不足
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
数据交换格式:json,xml,yaml

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









