



 本文通过爬取《武林外传》豆瓣评论并利用SnowNLP进行情感分析,结果显示观众对此剧持有积极态度。同时,通过对评论进行词云分析,进一步揭示观众对该剧的喜爱之情。
本文通过爬取《武林外传》豆瓣评论并利用SnowNLP进行情感分析,结果显示观众对此剧持有积极态度。同时,通过对评论进行词云分析,进一步揭示观众对该剧的喜爱之情。
转载原链接: http://www.cnblogs.com/fredkeke/p/8328387.html
我一向比较喜欢看武侠电影、小说,但是06年武林外传开播的时候并没有追剧,简单扫几眼之后发现他们都不会那种飞来飞去的打,一点也不刺激。09年在南京培训的时候,日子简单无聊透顶,大好的周末不能出门,只能窝在几平米的宿舍,一帮老爷们打游戏看电影,也就是在这个时候开始认真的看武林外传,从此一发不可收拾。
在之后这么多年,这部剧成了我茶余饭后消遣的必备品,吃饭的时候看一集、上厕所的时候看一点、挤地铁的上班路上看一看笑一笑……
好吧,废话就不多说了,进入今天的正题。《武林外传》豆瓣评分9.3,共计124,140人评价,5颗星占比73.2%,4颗星20.7%,3颗星5.2%。为了更好的分析大家对这部剧的评价,咱们通过分析短评人的情绪和词云来看一下。
首先,爬取《武林外传》热门短评,豆瓣的反爬虫做的还是比较好的,不登陆账户的爬虫或者短时间不限制时间的爬取数据都会被暂时封锁账户。因此,要登陆账户,拿到cookies,并且在循环爬取数据时设置sleep,
例如:time.sleep(random.randint(1, 10))
《武林外传》热门短评共爬取了507条评论,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import
time
import
random
import
requests
from
lxml
import
etree
absolute
=
'https://movie.douban.com/subject/3882715/comments'
page1_url
=
'https://movie.douban.com/subject/3882715/comments?start=0&limit=20&sort=new_score&status=P&percent_type='
page2_url
=
'https://movie.douban.com/subject/3882715/comments?start=20&limit=20&sort=new_score&status=P&percent_type='
header
=
{
'User-Agent'
:
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
,
'Connection'
:
'keep-alive'
}
f_cookies
=
open
(
'cookies.txt'
,
'r'
)
cookies
=
{}
for
line
in
f_cookies.read().split(
';'
):
name, value
=
line.strip().split(
'='
,
1
)
cookies[name]
=
value
def
next_page(url):
r
=
requests.get(url
=
url,cookies
=
cookies,headers
=
header).content
soup
=
etree.HTML(r)
return
soup.xpath(
'//*[@id="paginator"]/a[3]/@href'
)
def
html_prase(url):
r
=
requests.get(url
=
url,cookies
=
cookies,headers
=
header).content
return
etree.HTML(r)
def
comment_scripy(url):
page
=
html_prase(url)
for
i
in
range
(
1
,
21
):
comment
=
'
'.join(page.xpath('
/
/
*
[@
id
=
"comments"
]
/
div[
%
s]
/
div[
2
]
/
p
/
text()
' %i)).strip().replace('
\n
', '
,')
date
=
page.xpath(
'//*[@id="comments"]/div[%s]/div[2]/h3/span[2]/span[3]/text()'
%
i)
if
date:
date
=
'
'.join(page.xpath('
/
/
*
[@
id
=
"comments"
]
/
div[
%
s]
/
div[
2
]
/
h3
/
span[
2
]
/
span[
3
]
/
text()'
%
i)).strip()
else
:
date
=
'
'.join(page.xpath('
/
/
*
[@
id
=
"comments"
]
/
div[
%
s]
/
div[
2
]
/
h3
/
span[
2
]
/
span[
2
]
/
text()'
%
i)).strip()
rate
=
page.xpath(
'//*[@id="comments"]/div[%s]/div[2]/h3/span[2]/span[2]/@title'
%
i)
for
i
in
rate:
if
u
'\u4e00'
<
=
i <
=
u
'\u9fff'
:
rate
=
i.strip()
else
:
rate
=
'还行'
with
open
(
'date_rate_comment.txt'
,
'a'
, encoding
=
'utf-8'
) as f:
f.write(
str
(date)
+
','
+
str
(rate)
+
','
+
str
(comment)
+
'\n'
)
print
(
'正在打印第1页:'
)
comment_scripy(page1_url)
time.sleep(random.randint(
1
,
10
))
print
(
'正在打印第2页:'
)
comment_scripy(page2_url)
time.sleep(random.randint(
1
,
10
))
next_page_url
=
absolute
+
''.join(next_page(page2_url))
print
(next_page_url)
page
=
3
while
(next_page_url !
=
absolute):
print
(
'正在打印第%s页'
%
page)
next_page_url
=
absolute
+
''.join(next_page(next_page_url))
print
(next_page_url)
comment_scripy(next_page_url)
if
page
/
100
and
page
%
100
=
=
0
:
time.sleep(
100
)
else
:
time.sleep(random.randint(
1
,
10
))
page
=
page
+
1
|
其中cookies.txt文件就是每个人登陆后拿到的cookies对应的一长串数字代码,粘贴进txt空白文件就可以了。
接下来对数据进行清洗:
|
1
2
3
4
|
import
pandas as pd
name
=
[
'date'
,
'rate'
,
'comment'
]
df
=
pd.read_table(
'date_rate_comment.txt'
, encoding
=
'utf-8'
, header
=
None
, names
=
name, sep
=
','
)
df[
'date'
]
=
pd.to_datetime(df[
'date'
])
|
情感分析:
对短评给予SnowNPLP进行积极和消极情感分析,读取每段评论并进行情感值分析,最后计算出数值(0-1之间),当值大于0.5时代表句子的情感极性偏向积极,当分值小于0.5时,情感极性偏向消极,当然越偏向两边,说明大家看法分化越严重。
代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import
numpy as np
from
snownlp
import
SnowNLP
import
matplotlib.pyplot as plt
comment
=
[]
with
open
(
'date_rate_comment.txt'
, mode
=
'r'
, encoding
=
'utf-8'
) as f:
rows
=
f.readlines()
for
row
in
rows:
if
row
not
in
comment:
comment.append(row.strip(
'\n'
))
def
snowAnalysis(
self
):
sentimentslist
=
[]
for
li
in
self
:
print
(li)
s
=
SnowNLP(li)
print
(s.sentiments)
sentimentslist.append(s.sentiments)
plt.hist(sentimentslist, bins
=
np.arange(
0
,
1
,
0.01
))
plt.savefig(
"snowAnalysis.jpg"
)
plt.show()
snowAnalysis(comment)
|
图示如下:
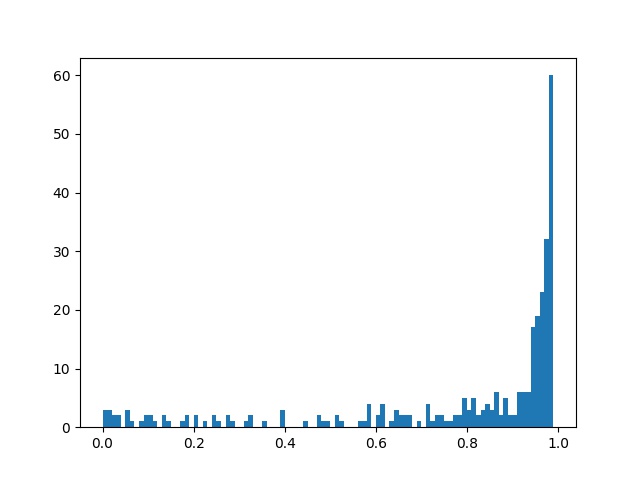
从上图情感分析可以看出来,大家对这部剧还是非常积极的。
词云分析代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
from
os
import
path
import
jieba
import
matplotlib.pyplot as plt
from
wordcloud
import
WordCloud, ImageColorGenerator
def
worldCloud(file_path):
f
=
open
(file_path,
'r'
,encoding
=
'UTF-8'
).read()
words_after_jieba
=
jieba.cut(f, cut_all
=
False
)
words_list
=
" "
.join(words_after_jieba)
print
(words_list)
backgroud_Image
=
plt.imread(
'wulinwaizhuan.jpg'
)
print
(
'加载图片成功!'
)
'''设置词云样式'''
stopwords
=
[
'哈哈'
,
'还是'
,
'电影'
,
'你们'
,
'这么'
,
'不过'
,
'什么'
,
'没有'
,
'这个'
,
'那个'
,
'大家'
,
'比较'
,
'真是'
,
'觉得'
,
'那么'
]
wc
=
WordCloud(
width
=
1024
,
height
=
860
,
background_color
=
'white'
,
# 设置背景颜色
mask
=
backgroud_Image,
# 设置背景图片
font_path
=
'Font/SimSun.ttf'
,
# 设置中文字体,若是有中文的话,这句代码必须添加,不然会出现方框,不出现汉字
max_words
=
300
,
# 设置最大现实的字数
stopwords
=
stopwords,
# 设置停用词
max_font_size
=
400
,
# 设置字体最大值
random_state
=
50
,
# 设置有多少种随机生成状态,即有多少种配色方案
)
wc.generate(words_list)
#wc.generate_from_text(wl_space_split)#开始加载文本
img_colors
=
ImageColorGenerator(backgroud_Image)
wc.recolor(color_func
=
img_colors)
#字体颜色为背景图片的颜色
plt.imshow(wc)
# 显示词云图
plt.axis(
'off'
)
# 是否显示x轴、y轴下标
plt.show()
#显示
# 获得模块所在的路径的
d
=
path.dirname(__file__)
wc.to_file(path.join(d,
"wordAnalysis.jpg"
))
print
(
'生成词云成功!'
)
worldCloud(
'date_rate_comment.txt'
)
|
其中:font_path='Font/SimSun.ttf',若有中文的话一定要加上,不然会出现方框,不显示汉字。SimSun.ttf这个文件可以从网上下载,放进Font这个文件夹下就可以了。

从词云分析来看,大家“力荐”、“推荐”的相当积极,广受好评。
总结
《武林外传》真的是一部轻松欢快的喜剧,值得大家拥有。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









