



 本文通过具体示例介绍如何在SQL中识别并删除重复的数据记录,确保数据表中记录的唯一性。
本文通过具体示例介绍如何在SQL中识别并删除重复的数据记录,确保数据表中记录的唯一性。
在某一数据表中,数据有冗余了,我们需要获取唯一的记录。
同这样的问题,使用例子来说时,最简单了。
创建一张数据表: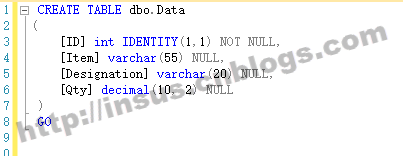


CREATE TABLE dbo.Data ( [ID] int IDENTITY(1,1) NOT NULL, [Item] varchar(55) NULL, [Designation] varchar(20) NULL, [Qty] decimal(10, 2) NULL ) GO
为这张表,添加一些数据,注意一些数据已经重复了: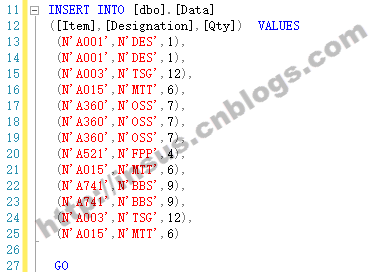
INSERT INTO [dbo].[Data] ([Item],[Designation],[Qty]) VALUES (N'A001',N'DES',1), (N'A001',N'DES',1), (N'A003',N'TSG',12), (N'A015',N'MTT',6), (N'A360',N'OSS',7), (N'A360',N'OSS',7), (N'A360',N'OSS',7), (N'A521',N'FPP',4), (N'A015',N'MTT',6), (N'A741',N'BBS',9), (N'A741',N'BBS',9), (N'A003',N'TSG',12), (N'A015',N'MTT',6) GO
如果数据是较高的一些版本,接下来使用ROW_NUMBER()来过滤数据: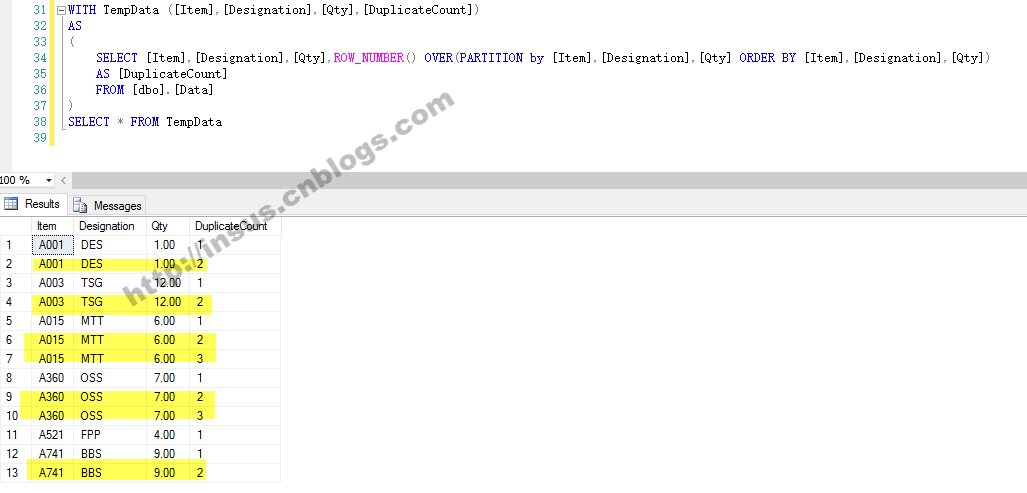
WITH TempData ([Item],[Designation],[Qty],[DuplicateCount]) AS ( SELECT [Item],[Designation],[Qty],ROW_NUMBER() OVER(PARTITION by [Item],[Designation],[Qty] ORDER BY [Item],[Designation],[Qty]) AS [DuplicateCount] FROM [dbo].[Data] ) SELECT * FROM TempData
上面只是知道哪些数据是在重复的。现在我们需要对上面的SQL语句稍改一下,把重复的记录删除: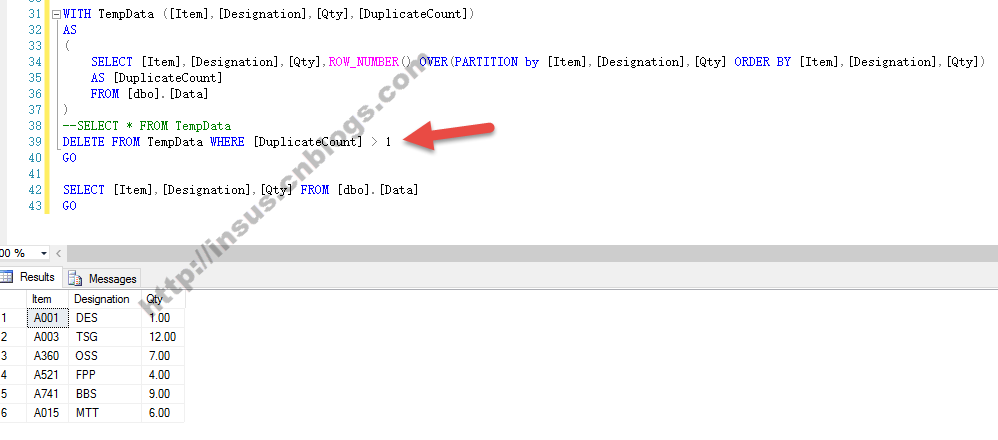
WITH TempData ([Item],[Designation],[Qty],[DuplicateCount]) AS ( SELECT [Item],[Designation],[Qty],ROW_NUMBER() OVER(PARTITION by [Item],[Designation],[Qty] ORDER BY [Item],[Designation],[Qty]) AS [DuplicateCount] FROM [dbo].[Data] ) --SELECT * FROM TempData DELETE FROM TempData WHERE [DuplicateCount] > 1 GO SELECT [Item],[Designation],[Qty] FROM [dbo].[Data] GO


















 8521
8521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









