



 本文深入解析Elastic-Job分布式调度框架的工作原理,涵盖初始化配置、作业调度流程、作业执行细节等内容。介绍了如何配置Zookeeper实现作业注册和服务发现,以及通过Quartz框架实现定时任务调度。
本文深入解析Elastic-Job分布式调度框架的工作原理,涵盖初始化配置、作业调度流程、作业执行细节等内容。介绍了如何配置Zookeeper实现作业注册和服务发现,以及通过Quartz框架实现定时任务调度。

Elastic-job-lite 官方概述
Quartz-scheduler
Job类型
Job的执行器: LiteJob中execute方法实例化AbstractElasticJobExecutor。
- ScriptJob : ScriptJobExecutor
- SimpleJob : SimpleJobExecutor
/** * 简单分布式作业接口. * */ public interface SimpleJob extends ElasticJob { /** * 执行作业. * * @param shardingContext 分片上下文 */ void execute(ShardingContext shardingContext); } - DataflowJob: DataflowJobExecutor。当开启streamingProcess时,当fetchData方法获取数据不为空时,将循环执行。
-
/** * 数据流分布式作业接口. * * * @param <T> 数据类型 */ public interface DataflowJob<T> extends ElasticJob { /** * 获取待处理数据. * * @param shardingContext 分片上下文 * @return 待处理的数据集合 */ List<T> fetchData(ShardingContext shardingContext); /** * 处理数据. * * @param shardingContext 分片上下文 * @param data 待处理数据集合 */ void processData(ShardingContext shardingContext, List<T> data); }DataflowJobExecutor: @Override protected void process(final ShardingContext shardingContext) { DataflowJobConfiguration dataflowConfig = (DataflowJobConfiguration) getJobRootConfig().getTypeConfig(); if (dataflowConfig.isStreamingProcess()) { streamingExecute(shardingContext); } else { oneOffExecute(shardingContext); } } private void streamingExecute(final ShardingContext shardingContext) { List<Object> data = fetchData(shardingContext); while (null != data && !data.isEmpty()) { processData(shardingContext, data); if (!getJobFacade().isEligibleForJobRunning()) { break; } data = fetchData(shardingContext); } } private void oneOffExecute(final ShardingContext shardingContext) { List<Object> data = fetchData(shardingContext); if (null != data && !data.isEmpty()) { processData(shardingContext, data); } }
初始化过程
ZookeeperRegistryCenter
- ZookeeperConfiguration:设置serverLists<包括IP地址和端口号,多个地址用逗号分隔>、namespace、digest等连接zookeeper的属性。
- CuratorFramework: 连接zk客户端
namespace一定不能反斜杠开头:
初始化curatorFramework实例NamespaceImpl对象时:PathUtils.validatePath("/" + namespace)。
java.lang.IllegalArgumentException: Invalid namespace: /zookeeper/scheduler/namespace/local
at org.apache.curator.framework.imps.NamespaceImpl.<init>(NamespaceImpl.java:48)
at org.apache.curator.framework.imps.CuratorFrameworkImpl.<init>(CuratorFrameworkImpl.java:116)
at org.apache.curator.framework.CuratorFrameworkFactory$Builder.build(CuratorFrameworkFactory.java:145)
at com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter.init(ZookeeperRegistryCenter.java:97)上图中显示的<init>标识的是class文件中代表对象的构造方法,在类实例化时调用。
JobScheduler<SpringJobScheduler>
- 创建config节点,保存配置信息。如果没有设置overwrite为true, 以zk为准。
- 依quartz框架创建scheduler、JobDetail 实例对象,并封装入JobScheduleController。
- JobRegistry保存任务的当前分片总数,保存<jobName, jobInstance>和<jobName, jobScheduleController>等映射。
- 持久化任务各功能节点,并给指定节点路径为"/${jobName}"的TreeCache添加各功能的监控TreeCacheListener。
- JobScheduleController调用scheduler.scheduleJob(jobDetail, createTrigger(cron))开始任务
public void init() {
LiteJobConfiguration liteJobConfigFromRegCenter = schedulerFacade.updateJobConfiguration(liteJobConfig);
JobRegistry.getInstance().setCurrentShardingTotalCount(liteJobConfigFromRegCenter.getJobName(),
liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getShardingTotalCount());
JobScheduleController jobScheduleController = new JobScheduleController(createScheduler(),
createJobDetail(liteJobConfigFromRegCenter.getTypeConfig().getJobClass()),
liteJobConfigFromRegCenter.getJobName());
JobRegistry.getInstance().registerJob(liteJobConfigFromRegCenter.getJobName(), jobScheduleController,
regCenter);
schedulerFacade.registerStartUpInfo(!liteJobConfigFromRegCenter.isDisabled());
jobScheduleController.scheduleJob(liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getCron());
}LiteJobConfiguration
使用JobTypeConfiguration,JobTypeConfiguration使用JobCoreConfiguration,层层嵌套。设置jobName、cron、shardingTotalCount、shardingItemParameters、failover、misfire、jobClass、monitorExecution等作业属性。
JobScheduler.init() -> schedulerFacade.registerStartUpInfo(liteJobConfig) 中注册config节点时,通过overwrite属性configService.persist(liteJobConfig)判定是否需要覆盖zk上的配置。如果设置overwrite为false,将从zookeeper上获取配置数据。
ConfigurationService:
public void persist(final LiteJobConfiguration liteJobConfig) {
checkConflictJob(liteJobConfig);
if (!jobNodeStorage.isJobNodeExisted(ConfigurationNode.ROOT) || liteJobConfig.isOverwrite()) {
jobNodeStorage.replaceJobNode(ConfigurationNode.ROOT, LiteJobConfigurationGsonFactory.toJson(liteJobConfig));
}
}SchedulerFacade
启动任务初始化zk节点信息,开启zk节点事件监控; 开启检测分布式作业服务分片含离线作业实例;
终止调度时,删除leader/election/instance临时节点,关闭监控ServerSocket,关闭检测一致性服务。
/**
* 注册作业启动信息.
*
* @param enabled 作业是否启用
*/
public void registerStartUpInfo(final boolean enabled) {
listenerManager.startAllListeners();
leaderService.electLeader();
serverService.persistOnline(enabled);
instanceService.persistOnline();
shardingService.setReshardingFlag();
monitorService.listen();
if (!reconcileService.isRunning()) {
reconcileService.startAsync();
}
}LiteJobFacade
在JobRunShell初始化时通过quartz运行原理PropertySettingJobFactory.setBeanProps方法将JobDetail.getJobDataMap()被反射注入到LiteJob中。
在任务运行中提供对节点信息获取或更新的服务。
LiteJob
JobDetail中指定任务的执行类:quartz.Job。将成员变量的值按名称存在JobDetail中的JobDataMap中。通过SimpleJobFactory构建,PropertySettingJobFactory设置成员属性值。
private JobDetail createJobDetail(final String jobClass) {
JobDetail result = JobBuilder.newJob(LiteJob.class).withIdentity(liteJobConfig.getJobName()).build();
result.getJobDataMap().put(JOB_FACADE_DATA_MAP_KEY, jobFacade);
Optional<ElasticJob> elasticJobInstance = createElasticJobInstance();
if (elasticJobInstance.isPresent()) {
result.getJobDataMap().put(ELASTIC_JOB_DATA_MAP_KEY, elasticJobInstance.get());
} else if (!jobClass.equals(ScriptJob.class.getCanonicalName())) {
try {
result.getJobDataMap().put(ELASTIC_JOB_DATA_MAP_KEY, Class.forName(jobClass).newInstance());
} catch (final ReflectiveOperationException ex) {
throw new JobConfigurationException("Elastic-Job: Job class '%s' can not initialize.", jobClass);
}
}
return result;
}JobScheduleController
保存scheduler、jobDetail、JobName间的关系。控制作业调度启动、重新触发、关闭调度能控制操作。
package com.dangdang.ddframe.job.lite.internal.schedule;
import com.dangdang.ddframe.job.exception.JobSystemException;
import lombok.RequiredArgsConstructor;
import org.quartz.CronScheduleBuilder;
import org.quartz.CronTrigger;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.TriggerBuilder;
import org.quartz.TriggerKey;
/**
* 作业调度控制器.
*
* @author zhangliang
*/
@RequiredArgsConstructor
public final class JobScheduleController {
private final Scheduler scheduler; // quartzScheduler
private final JobDetail jobDetail; // LiteJob
private final String triggerIdentity; // JobName
/**
* 调度作业.
*
* @param cron CRON表达式
*/
public void scheduleJob(final String cron) {
try {
// RAMJobStore保存了Key的惟一信息
if (!scheduler.checkExists(jobDetail.getKey())) {
scheduler.scheduleJob(jobDetail, createTrigger(cron));
}
scheduler.start();
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
/**
* 重新调度作业.
*
* @param cron CRON表达式
*/
public void rescheduleJob(final String cron) {
try {
CronTrigger trigger = (CronTrigger) scheduler.getTrigger(TriggerKey.triggerKey(triggerIdentity));
if (!scheduler.isShutdown() && null != trigger && !cron.equals(trigger.getCronExpression())) {
scheduler.rescheduleJob(TriggerKey.triggerKey(triggerIdentity), createTrigger(cron));
}
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
private CronTrigger createTrigger(final String cron) {
return TriggerBuilder.newTrigger().withIdentity(triggerIdentity).withSchedule(CronScheduleBuilder.cronSchedule(cron).withMisfireHandlingInstructionDoNothing()).build();
}
/**
* 暂停作业.
*/
public void pauseJob() {
try {
if (!scheduler.isShutdown()) {
scheduler.pauseAll();
}
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
/**
* 恢复作业.
*/
public void resumeJob() {
try {
if (!scheduler.isShutdown()) {
scheduler.resumeAll();
}
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
/**
* 立刻启动作业.
*/
public void triggerJob() {
try {
if (!scheduler.isShutdown()) {
scheduler.triggerJob(jobDetail.getKey());
}
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
/**
* 关闭调度器.
*/
public void shutdown() {
try {
if (!scheduler.isShutdown()) {
scheduler.shutdown();
}
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
}
执行过程
init: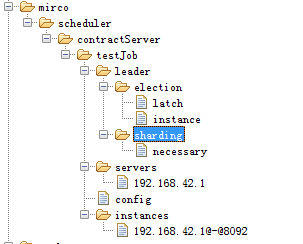
running: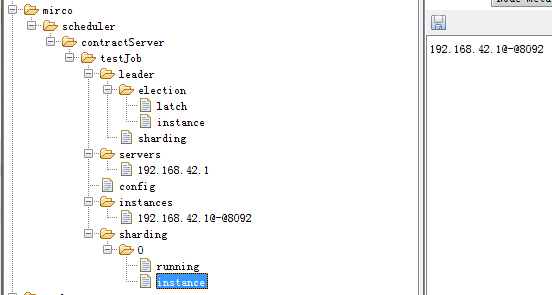
org.quartz.core.QuartzSchedulerThread:
通过Object.wait(long timeout)的方式阻塞执行,循环创建org.quartz.core.JobRunShell对象并初始化JobExecutionContextImpl的过程。JobExecutionContextImpl对象中包含通过JobFactory创建出来的org.quartz.Job实例对象LitJob。通过JobDetail.getJobDataMap()反射注入的elasticJob和JobFacade调用JobExecutorFactory创建AbstractElasticJobExecutor实例,执行execute()。
- 通过创建或更新“systemTime/current”节点获取注册中心创建时间。检查本机与创建时间误差秒数是否在允许范围,不在则所抛出的异常;
- 判定是否开启失效转移,如果开启,获取运行在本作业服务器的失效转移序列号,否则执行分片过程,获取过滤掉禁用的正常分片。
- 如果当前分片项仍在运行则设置任务被错过执行的标记。
- 创建sharding/${itemIndex}/running节点。
- 按ExecutionSource.NORMAL_TRIGGER执行方式依据ShardingContexts来调用AbstractElasticJobExecutor的process方法,最终调用elasticJob的execute方法。当多个分片时,使用线程池处理,并CountDownLatch等待所有任务都执行完成;
- 判定判断作业是否需要执行错过的任务,若是,则按ExecutionSource.MISFIRE执行方式,并清除任务被错过执行的标记;
- 判定是否需要分片转移(leader/failover/items下存在分片节点,且当前服务空闲)。若是则执行FailoverLeaderExecutionCallback:
- ${namespaces}/${jobUniqueId}/leader/failover/latch下生成失效节点。
- 填充sharding/${itemIndex}/failover数据为当前执行的jobInstanceId;
- 清除leader/failover/items/${itemIndex}标记并重新触发任务。
- finally:
- 删除sharding/${itemIndex}/running节点;
- 若有failover,则删除sharding/${itemIndex}/failover。
AbstractElasticJobExecutor:
/**
* 执行作业.
*/
public final void execute() {
try {
jobFacade.checkJobExecutionEnvironment();
} catch (final JobExecutionEnvironmentException cause) {
jobExceptionHandler.handleException(jobName, cause);
}
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_STAGING, String.format("Job '%s' execute begin.", jobName));
}
if (jobFacade.misfireIfRunning(shardingContexts.getShardingItemParameters().keySet())) {
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_FINISHED, String.format(
"Previous job '%s' - shardingItems '%s' is still running, misfired job will start after previous job completed.", jobName,
shardingContexts.getShardingItemParameters().keySet()));
}
return;
}
try {
jobFacade.beforeJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
execute(shardingContexts, JobExecutionEvent.ExecutionSource.NORMAL_TRIGGER);
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
jobFacade.failoverIfNecessary();
try {
jobFacade.afterJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
}
修改config配置
配置信息保存在zk的${namespaces}/${jobUniqueId}/config节点上。
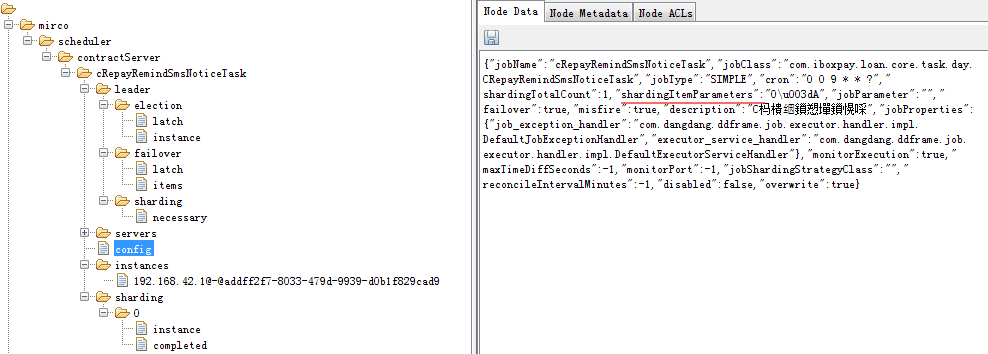
当config节点数据变动时,触发CronSettingAndJobEventChangedJobListener事件响应,并重新生成org.quartz.impl.StdScheduler的CronTrigger。调用scheduler.rescheduleJob方法。
public class QuartzScheduler implements RemotableQuartzScheduler:
public Date rescheduleJob(TriggerKey triggerKey,
Trigger newTrigger) throws SchedulerException {
validateState();
if (triggerKey == null) {
throw new IllegalArgumentException("triggerKey cannot be null");
}
if (newTrigger == null) {
throw new IllegalArgumentException("newTrigger cannot be null");
}
OperableTrigger trig = (OperableTrigger)newTrigger;
Trigger oldTrigger = getTrigger(triggerKey);
if (oldTrigger == null) {
return null;
} else {
trig.setJobKey(oldTrigger.getJobKey());
}
trig.validate();
Calendar cal = null;
if (newTrigger.getCalendarName() != null) {
cal = resources.getJobStore().retrieveCalendar(
newTrigger.getCalendarName());
}
Date ft = trig.computeFirstFireTime(cal);
if (ft == null) {
throw new SchedulerException(
"Based on configured schedule, the given trigger will never fire.");
}
if (resources.getJobStore().replaceTrigger(triggerKey, trig)) {
notifySchedulerThread(newTrigger.getNextFireTime().getTime());
notifySchedulerListenersUnscheduled(triggerKey);
notifySchedulerListenersSchduled(newTrigger);
} else {
return null;
}
return ft;
}
手动触发任务
TriggerListenerManager管理JobTriggerStatusJobListener来响应手动触发任务的执行。
class JobTriggerStatusJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
//判定事件类型、触发类型、触发的执行实例是否是本机服务的实例
if (!InstanceOperation.TRIGGER.name().equals(data) || !instanceNode.isLocalInstancePath(path) || Type.NODE_UPDATED != eventType) {
return;
}
instanceService.clearTriggerFlag();
if (!JobRegistry.getInstance().isShutdown(jobName) && !JobRegistry.getInstance().isJobRunning(jobName)) {
// TODO 目前是作业运行时不能触发, 未来改为堆积式触发
JobRegistry.getInstance().getJobScheduleController(jobName).triggerJob();
}
}
}扩展接口
在AbstractElasticJobExecutor.execute()中
- ElasticJobListener 弹性化分布式作业监听器接口
先执行JobFacade.beforeJobExecuted调用ElasticJobListener.beforeJobExecuted;再执行process();最后执行JobFacade.afterJobExecuted调用ElasticJobListener.afterJobExecuted。 - JobEventBus 运行事件总线
先注册JobEventListener,方法上有@Subscribe的按< 参数对象(Event),Collection<实例JobEventListener对象,方法名称>> 形式保存在EventBus中。在执行过程中,提供JobExecutionEvent和JobStatusTraceEvent两种JobEvent事件来publish到总线上进行处理。
JobFacade
/**
* 作业执行前的执行的方法.
*
* @param shardingContexts 分片上下文
*/
void beforeJobExecuted(ShardingContexts shardingContexts);
/**
* 作业执行后的执行的方法.
*
* @param shardingContexts 分片上下文
*/
void afterJobExecuted(ShardingContexts shardingContexts);
/**
* 发布执行事件.
*
* @param jobExecutionEvent 作业执行事件
*/
void postJobExecutionEvent(JobExecutionEvent jobExecutionEvent);
/**
* 发布作业状态追踪事件.
*
* @param taskId 作业Id
* @param state 作业执行状态
* @param message 作业执行消息
*/
void postJobStatusTraceEvent(String taskId, JobStatusTraceEvent.State state, String message);
作业注册不能同名
作业服务时按IP在${namespaces}/${jobUniqueId}/servers节点注册。同名的作业只会生成惟一的jobInstanceId,生成规则与当前作业服务器JVM的进程ID有关。 JobRegistry用ConcurrentHashMap保存jobName与JobInstance、JobScheduleController 值对关系。会进行更行操作,虽然对象是新内存,但jobInstanceId和scheduler是同一个。
数据分片
作业框架只负责将分片合理的分配给相关的作业服务器,作业服务器需根据所分配的分片匹配数据进行处理。将真实数据和逻辑分片对应,用于解耦作业框架和数据的关系。分片是发现服务器波动,或修改分片总数,将标记一个状态,而非直接分片。
设置shardingTotalCount、shardingItemParameters 信息。
作业高可用
将分片项设置为1,并使用多于1台的服务器执行作业,作业将会以1主n从的方式执行。一旦执行作业的服务器崩溃,等待执行的服务器将会在下次作业启动时替补执行。开启失效转移和监控功能,可以保证在本次作业执行时崩溃,备机立即启动替补执行(monitorExecution = true && failover =true)。
弹性扩容缩容
将任务拆分为n个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服务器加入集群,或现有服务器下线,在保留本次任务执行不变的情况下,下次任务开始前触发任务重分片。


















 1982
1982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









