



 本文详细介绍使用Scrapy框架爬取豆瓣电影Top250榜单的过程,包括项目搭建、定义Item、编写爬虫、数据处理及存储等内容。
本文详细介绍使用Scrapy框架爬取豆瓣电影Top250榜单的过程,包括项目搭建、定义Item、编写爬虫、数据处理及存储等内容。

学习网址:
http://www.ituring.com.cn/article/114408 http://python.jobbole.com/86584/ https://segmentfault.com/a/1190000003870052 runSpider->http://blog.youkuaiyun.com/wangsidadehao/article/details/52911746 CrawlSpider-->http://www.jianshu.com/p/0f64297fc912
总概:scrapy爬取网站的一般分为以下几步:1.新建scrapy project;2.定义Item;3.编写spider;4.定义pipelines;5.进行setting设置
1.新建scrapy project
首先,需要建立一个scrapy的项目。我用pycharm创建项目,所以需要将项目名称写入parameter里。
1a.创建一个CreateProj的python文件,命令和脚本设置parameter如下: startproject YourProjectName
#__author__='ZHENGT'
# -*- coding: utf-8 -*-
from scrapy import cmdline
cmdline.execute() #创建一个Project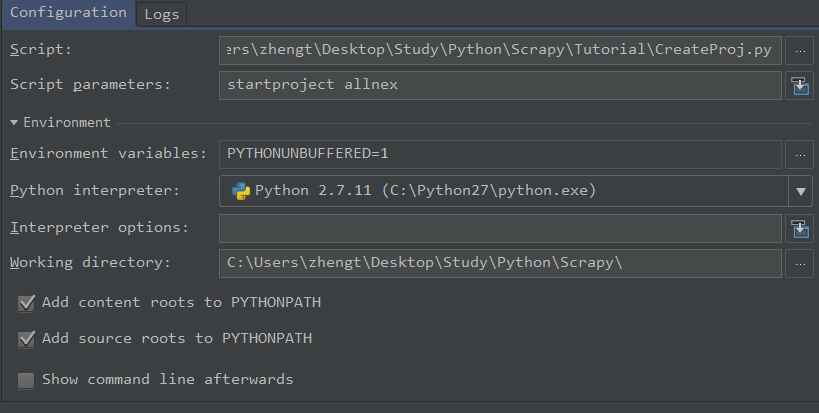
1b.运行后你会看到一个新建一个名字为allnex的project,结构如下
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块, 在这里添加代码
....__init__.py 项目的初始化文件
....items.py: 项目中的item文件
....pipelines.py: 项目中的pipelines文件
....settings.py: 项目全局设置文件
....spiders/ 爬虫模块目录
....__init__.py 爬虫初始化文件2.接下来,需要创建spider,在spiders目录下面,创建一个名为movie_spider的脚本文件。目录结构如下
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块, 在这里添加代码
....__init__.py 项目的初始化文件
....items.py: 项目中的item文件
....pipelines.py: 项目中的pipelines文件
....settings.py: 项目全局设置文件
....spiders/ 爬虫模块目录
....__init__.py 爬虫初始化文件
....movie_spider.py 爬虫文件
2a.观察网页内容,定义Item
豆瓣TOP250网址格式:https://movie.douban.com/top250?start=0&filter=
而点进去以后,每部电影的具体内容网址格式:https://movie.douban.com/subject/1292052/
这两部分等一下在写movie_spider的时候要用到.
观察网页内容可以发现,标题和年份标签是在id="content"下面

而评分标签则是在id="interest_sectl"下面

2b.创建item,用以数据归集,这里只选取三个:电影名称->name,电影年份->year,豆瓣分数-score
from scrapy.item import Item,Field #从scrapy引用item类
class DoubanmovieItem(Item): #定义一个类,用以存储spider数据
# define the fields for your item here like:
name=Field() #电影名
year=Field() #上映年份
score=Field() #豆瓣分数3.接下来就可以编写movie_spider爬虫
#__author__='ZHENGT'
# -*- coding: utf-8 -*-
from scrapy.selector import Selector #引入Selector分析xpath
from scrapy.contrib.spiders import CrawlSpider,Rule #引入爬虫
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from DoubanMovie.items import DoubanmovieItem #引入item类
class MovieSpider(CrawlSpider): #定义spider
name="doubanmovie" #定义spider名称
allowed_domains=["movie.douban.com"] #定义spider限制区域
start_urls=["https://movie.douban.com/top250"] #spider开始
rules=[
#CrawlSpider匹配下一页规则,并没有callback进行处理
Rule(SgmlLinkExtractor(allow=(r'https://movie.douban.com/top250\?start=\d+.*'))),
#CrawlSpider匹配下一层规则
Rule(SgmlLinkExtractor(allow=(r'https://movie.douban.com/subject/\d+')),
#使用函数进行处理
callback="parse_item"),
]
def parse_item(self,response): #数据处理,将返回pipelines
# print response.body #打印显示是否成功
sel=Selector(response) #将返回网页通过Selector转为xpath
item=DoubanmovieItem() #从items引入定义类
#进行网页数据抓取
item['name']=sel.xpath('//*[@id="content"]/h1/span[1]/text()').extract()
item['year'] = sel.xpath('//*[@id="content"]/h1/span[2]/text()').re(r'\((\d+)\)')
item['score'] = sel.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()').extract()
return item4.编写pipeline的类
f1 = "DoubanMovie.txt" #储存文件
class TxtPipeline(object): #定义pipeline
#Open Txt file
def process_item(self, item, spider):
#Insert data into txt
line=""
names=item['name'][0].encode("utf-8") #需要转码
years=item['year'][0].encode("utf-8")
scores=item['score'][0].encode("utf-8")
print type(names),type(years),type(scores),'<<<---------' #观察数据格式
line=names+years+scores #str联接
f=open(f1,'a')
f.write(line)
f.write("\n")
f.close()
return item #返回值5.设置settings.py
因为豆瓣不允许爬虫,所以需要设置USER_AGENT
BOT_NAME = 'DoubanMovie'
SPIDER_MODULES = ['DoubanMovie.spiders']
NEWSPIDER_MODULE = 'DoubanMovie.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 2
ITEM_PIPELINES = {
'DoubanMovie.pipelines.TxtPipeline': 1,
}
6.接下来,可以编写一个名字叫做Start_Spider来进行启动爬虫。
#__author__='ZHENGT'
# -*- coding: utf-8 -*-
#新建一个运行爬虫的模块
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from DoubanMovie.spiders.movie_spider import MovieSpider #引入spider类
#获取setting.py模块设置
settings=get_project_settings() #设置
process=CrawlerProcess(settings=settings)
#添加spider,可以添加多个spider
process.crawl(MovieSpider)
#启动spider
process.start()7.运行的时候结果,总共结果242个,丢失了几个
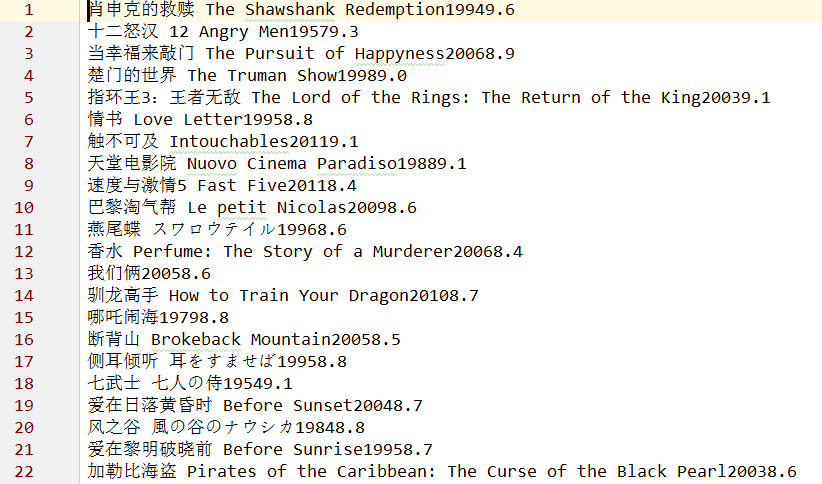

















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









