






1.HBase 与 Hive 的对比
1. Hive
(1) 数据仓库
Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双射关系,以
方便使用HQL 去管理查询。
(2) 用于数据分析、清洗
Hive 适用于离线的数据分析和清洗,延迟较高。
(3) 基于HDFS、MapReduce
Hive 存储的数据依旧在DataNode 上,编写的HQL 语句终将是转换为MapReduce 代码执行。
2. HBase
(1) 数据库
是一种面向列存储的非关系型数据库。
(2) 用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN 等操作。
(3) 基于HDFS
数据持久化存储的体现形式是Hfile,存放于 DataNode 中,被 ResionServer 以 region 的形式进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase 可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
2 HBase 与 Hive 集成使用
尖叫提示:HBase 与 Hive 的集成在最新的两个版本中无法兼容。所以,我们只能含着泪勇敢的重新编译:hive-hbase-handler-1.2.2.jar
环境准备
因为我们后续可能会在操作 Hive 的同时对 HBase 也会产生影响,所以 Hive 需要持有操作
HBase 的Jar,那么接下来拷贝Hive 所依赖的Jar 包(或者使用软连接的形式)。
export HBASE_HOME=/opt/module/hbase export HIVE_HOME=/opt/module/hive ln -s $HBASE_HOME/lib/hbase-common-1.3.1.jar $HIVE_HOME/lib/hbase-common-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-server-1.3.1.jar $HIVE_HOME/lib/hbase-server-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-client-1.3.1.jar $HIVE_HOME/lib/hbase-client-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-protocol-1.3.1.jar $HIVE_HOME/lib/hbase-protocol-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-it-1.3.1.jar $HIVE_HOME/lib/hbase-it-1.3.1.jar ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar$HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.3.1.jar
同时在 hive-site.xml 中修改 zookeeper 的属性,如下:
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
1.案例一
目标:建立 Hive 表,关联 HBase 表,插入数据到 Hive 表的同时能够影响 HBase 表。
分步实现:
(1) 在 Hive 中创建表同时关联 HBase
CREATE TABLE hive_hbase_emp_table( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
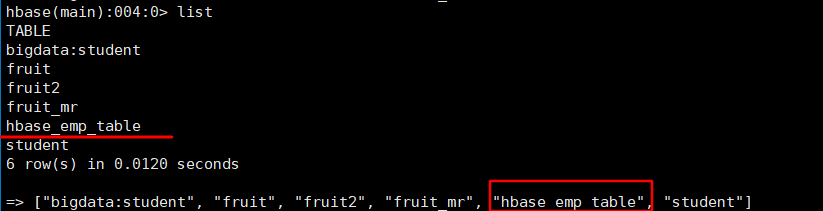
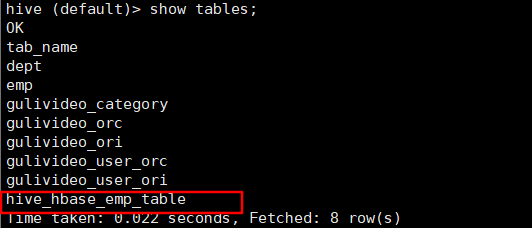
提示:完成之后,可以分别进入 Hive 和 HBase 查看,都生成了对应的表
(2) 在 Hive 中创建临时中间表,用于 load 文件中的数据
提示:不能将数据直接 load 进 Hive 所关联 HBase 的那张表中
CREATE TABLE emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by '\t';
(3) 向 Hive 中间表中 load 数据
hive> load data local inpath '/home/admin/softwares/data/emp.txt' into table emp;
(4) 通过 insert 命令将中间表中的数据导入到 Hive 关联 HBase 的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
(5) 查看 Hive 以及关联的 HBase 表中是否已经成功的同步插入了数据
Hive:
hive> select * from hive_hbase_emp_table;
HBase:
hbase> scan ‘hbase_emp_table’
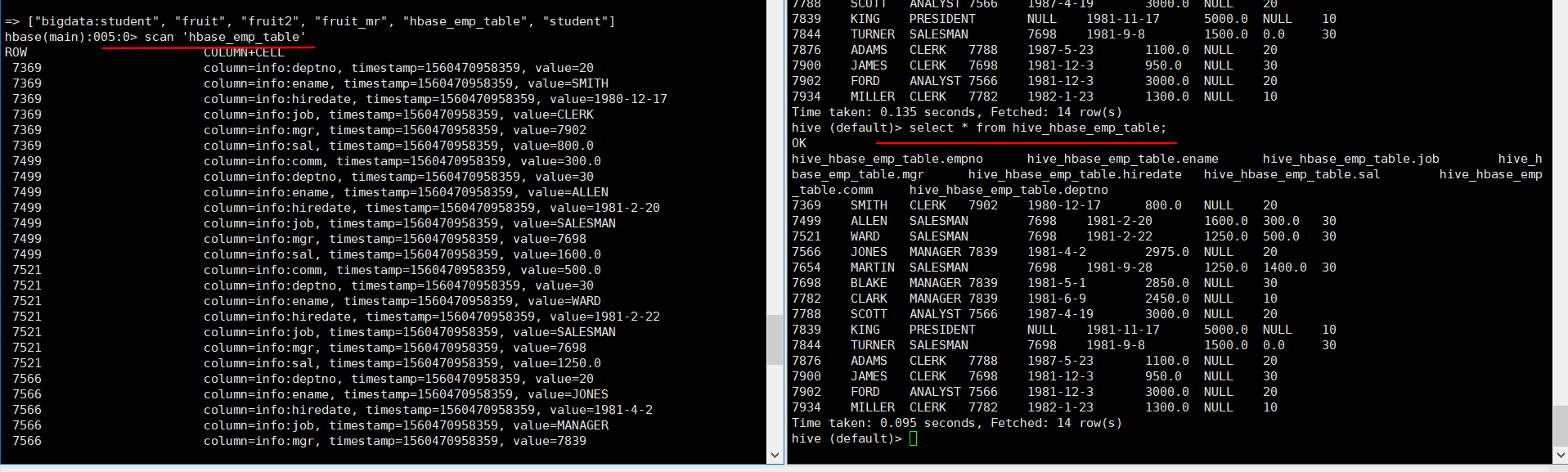
注:实际上HDFS上的hive下不存HBase的文件

2.案例二
目标:在 HBase 中已经存储了某一张表 hbase_emp_table,然后在 Hive 中创建一个外部表来
关联 HBase 中的 hbase_emp_table 这张表,使之可以借助 Hive 来分析 HBase 这张表中的数
据。
注:该案例 2 紧跟案例 1 的脚步,所以完成此案例前,请先完成案例 1。
分步实现:
(1) 在 Hive 中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
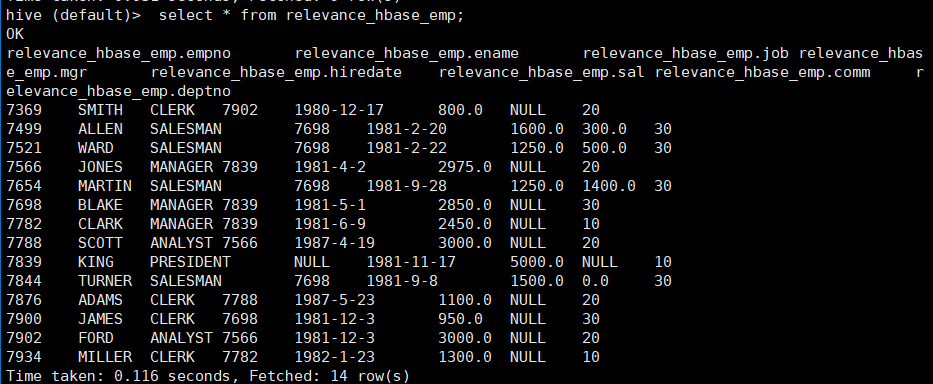
(2) 关联后就可以使用 Hive 函数进行一些分析操作了
hive (default)> select * from relevance_hbase_emp;

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









