






 本文从宏观角度出发,深入探讨了英文解释过程中的关键环节,解析了如何有效理解和运用英语解释技巧,提升英语水平。
本文从宏观角度出发,深入探讨了英文解释过程中的关键环节,解析了如何有效理解和运用英语解释技巧,提升英语水平。
1.宏观
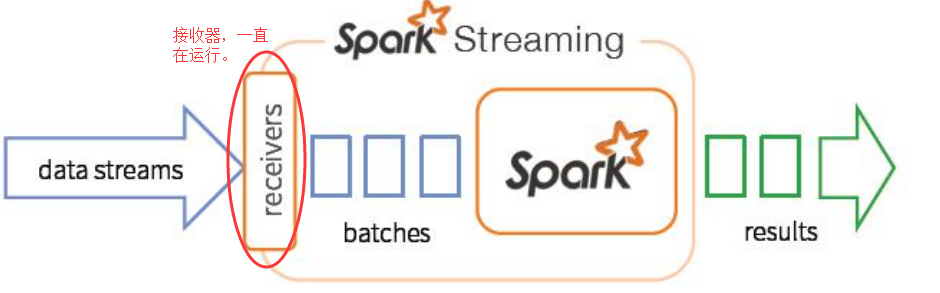
2.看英文解释过程
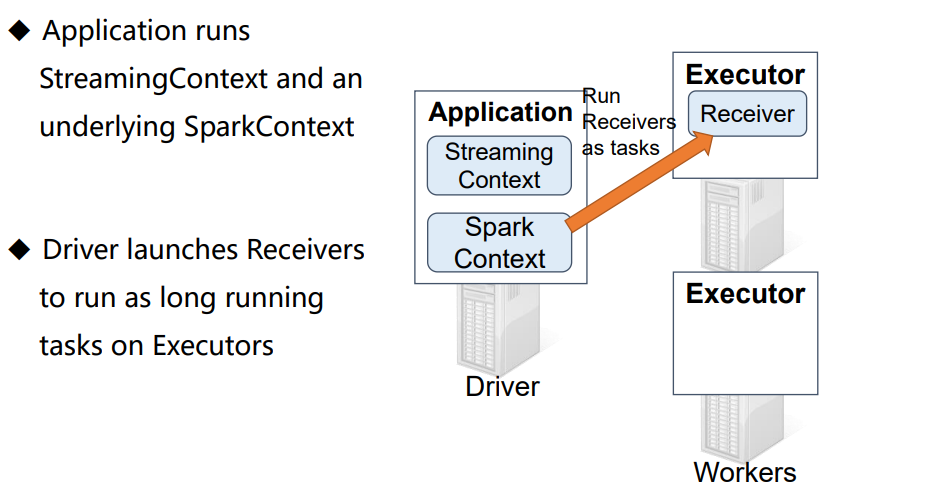
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
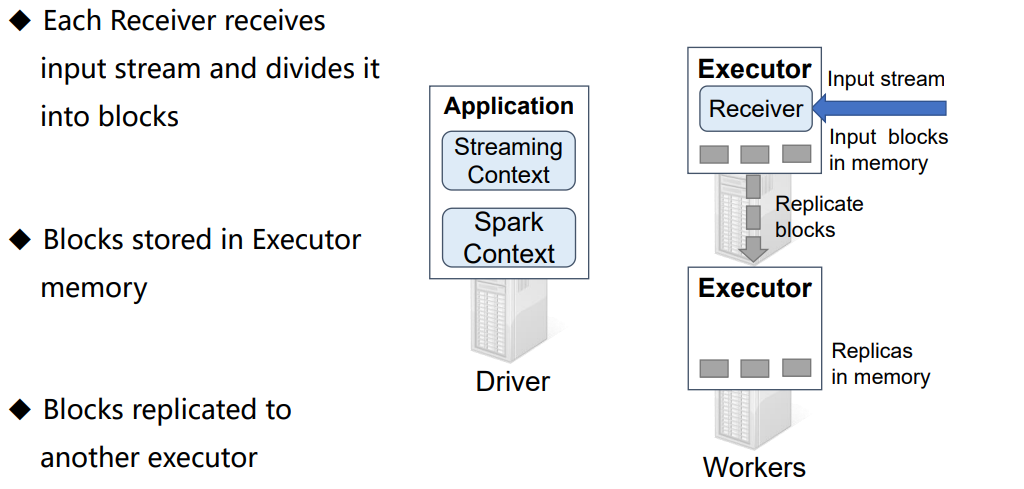
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
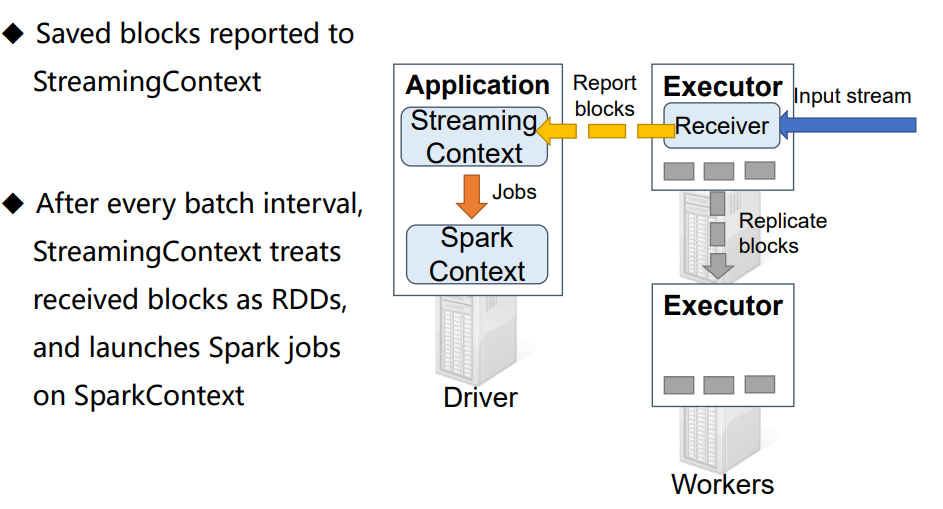
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
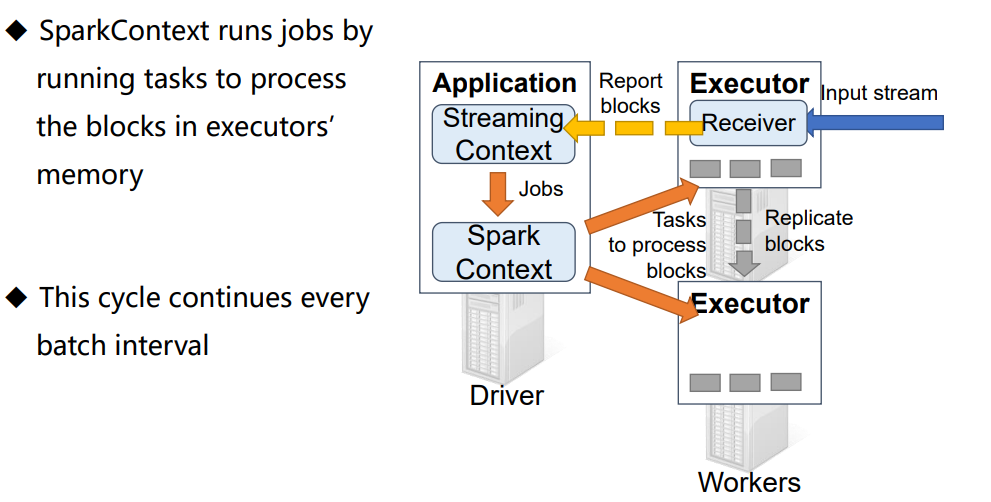
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
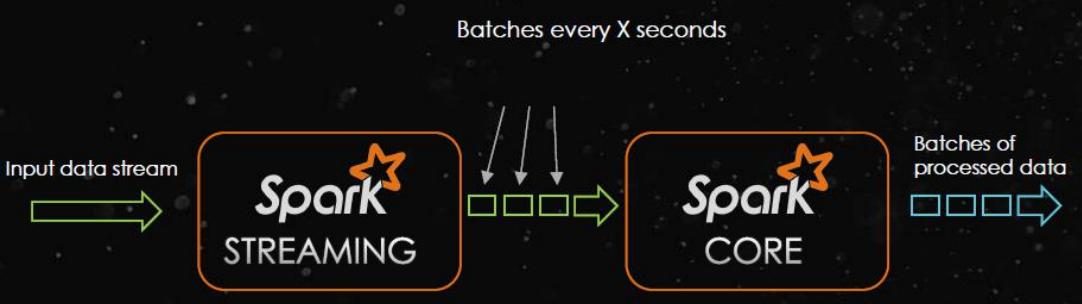


















 2406
2406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









