






Python爬虫百度新闻
微笑的小小刀:
有梦想,爱技术。在城市中奋斗却向往着田园生活
有故事,有酒,来来来, 与尔同销万古愁
谢谢大家支持
总体步骤
- python 环境准备
- 页面url分析
- 代码抓取
python 环境准备
- pycharm
- beautifulSoup
- requests
页面url 分析

1487561491324.png
这是直接在页面上进行百度新闻搜索,要注意url 。
这里先在python中写一段测试代码:
url = "http://news.baidu.com/ns?word=%CE%A2%D0%A6%B5%C4%D0%A1%D0%A1%B5%B6&cl=2&rn=20"
r = requests.get(url)
html = r.text
soup = BeautifulSoup(html, 'html.parser')
div_items = soup.find_all('div', class_='tn-bxitem')
在div_items那行打个断点。运行到那里之后的效果:

1487561766140.png
我们将soup里面的value拷贝出来,这就是我们从百度上面抓取的东西,现在就是对他进行分析。
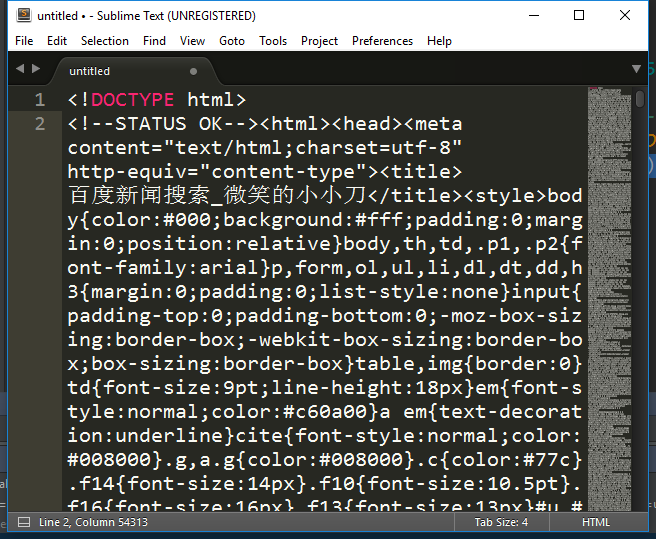
1487561867829.png
总行数有54313行, 我们就是要从里面找到有用的信息。
可以看到,他是把css样式文件也放在里面了,我们先把<style>标签里面的东西删掉
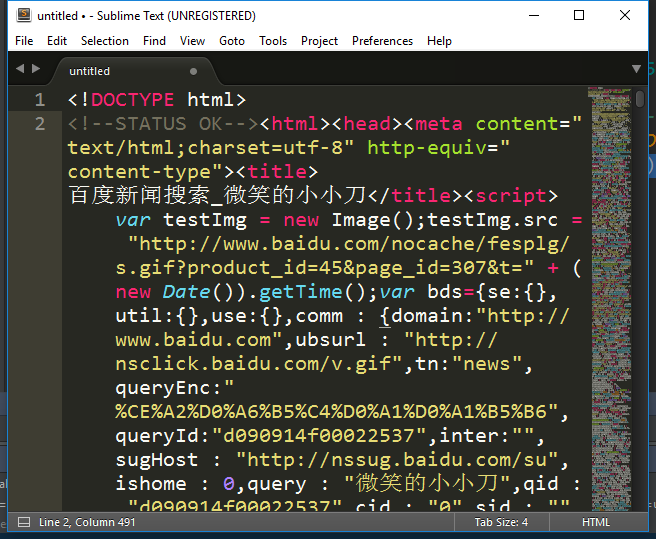
1487563085891.png
然后再把js <script>的代码删掉,只保留html代码。
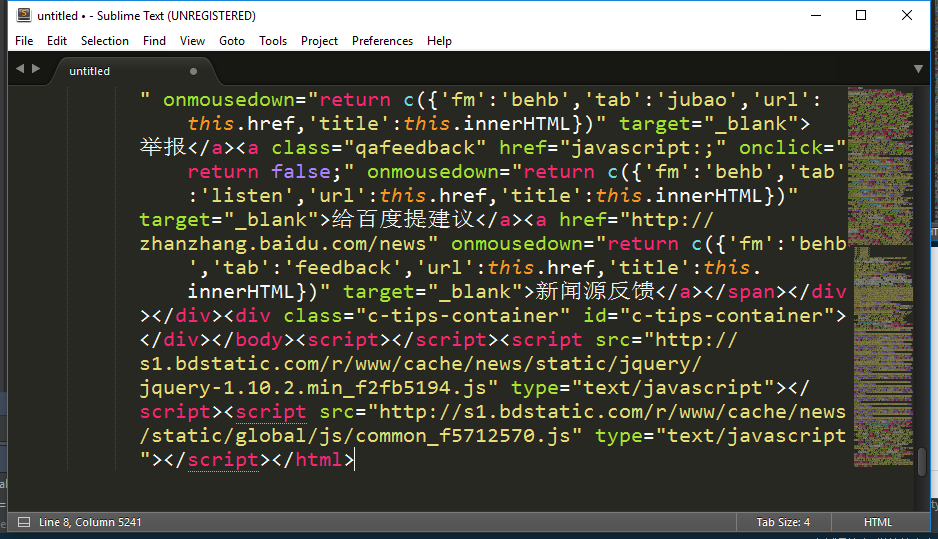
1487563291005.png
最后删完之后只剩下5241行了。虽然还是很多,但已经是比较少的了。
寻找有用信息
可以看到,结果被包涵在类名为 result的div里面, 我们就要在程序里面把这个div取出来
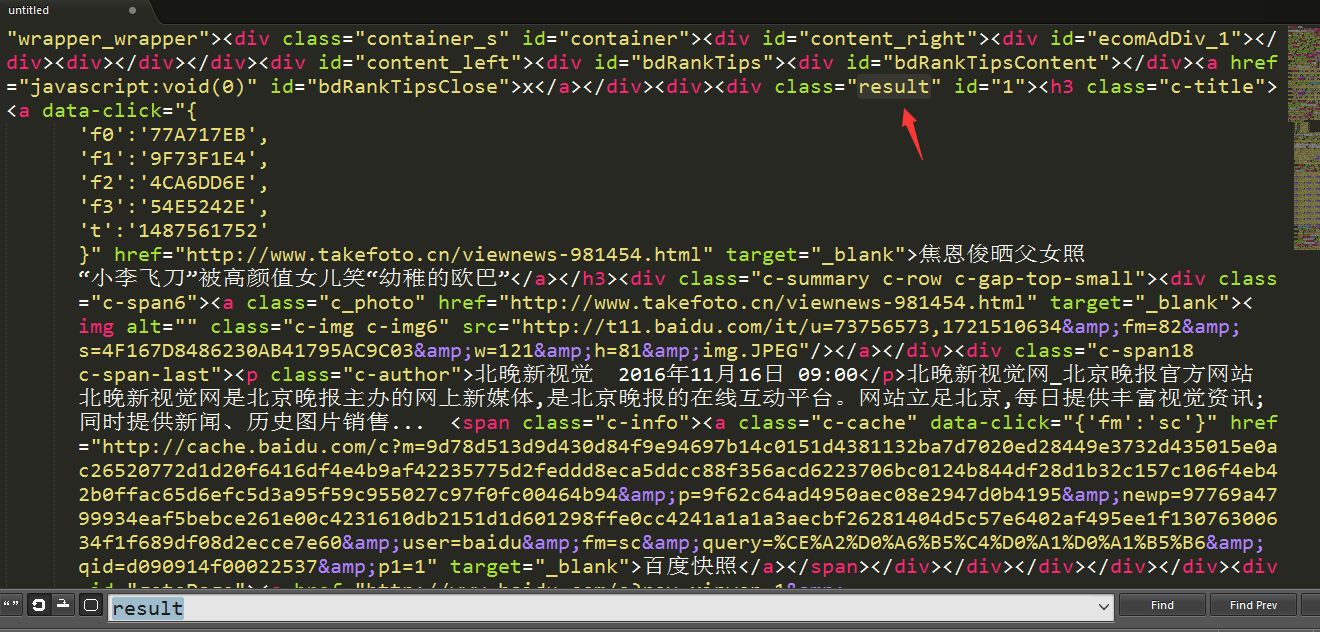
1487571577529.png
在上述程序中加入代码:
soup = BeautifulSoup(html, 'html.parser')
# 取出结果div
div_items = soup.find_all('div', class_='result')
print(div_items)
在print处打上断点可见:
正是我们需要的新闻,但还有细节需要提炼出来。可以注意到, 我们需要的东西都在class="result"的div里面。
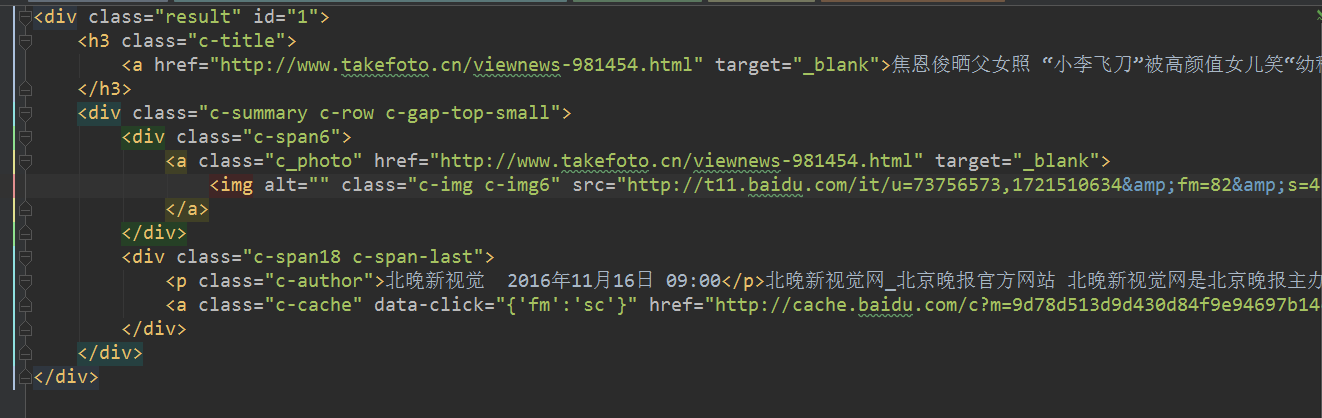
1487574102509.png
-
从h3 class="c-title"中取出标题,以及链接
添加代码:
# 取出结果div div_items = soup.find_all('div', class_='result') for div in div_items: # 取出title , 链接 a_title = div.find('h3', class_='c-title').find('a').get_text() a_href = div.find('h3', class_='c-title').find('a').get('href') print(a_title) print(a_href)
在控制台上打印结果如下:

1487575841227.png
-
取出简介
a_href = div.find('h3', class_='c-title').find('a').get('href') # 取出简介 a_summary = div.find('div', class_='c-summary').get_text()在控制如打印结果如下:

1487576938977.png
-
整理信息输出到文件
# 取出简介 a_summary = div.find('div', class_='c-summary').get_text() # 获取当前时间 now = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 输出到文件 with open('news' + now + '.txt', 'a', encoding='utf-8') as file: file.write("标题: " + a_title + "\n") file.write("链接: " + a_href + "\n") file.write("简介: " + a_summary + "\n") 输出到文件的结果

1487578138979.png
代码整理
from bs4 import BeautifulSoup
import requests
import time
# 定义url
url = "http://news.baidu.com/ns?word=%CE%A2%D0%A6%B5%C4%D0%A1%D0%A1%B5%B6&cl=2&rn=20"
r = requests.get(url)
html = r.text
soup = BeautifulSoup(html, 'html.parser')
# 取出结果div
div_items = soup.find_all('div', class_='result')
for div in div_items:
# 取出title , 链接
a_title = div.find('h3', class_='c-title').find('a').get_text()
a_href = div.find('h3', class_='c-title').find('a').get('href')
# 取出简介
a_summary = div.find('div', class_='c-summary').get_text()
# 获取当前时间
now = time.strftime('%Y-%m-%d', time.localtime(time.time()))
with open('news' + now + '.txt', 'a', encoding='utf-8') as file:
file.write("标题: " + a_title + "\n")
file.write("链接: " + a_href + "\n")
file.write("简介: " + a_summary + "\n")

















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









