



运行到子函数时提示报错:
 ===
===
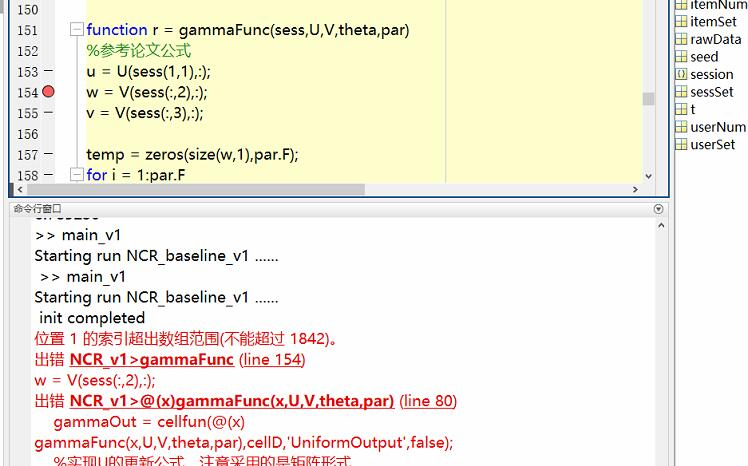
这个断点一步步debug下来是顺利的,但是咋就超出数组范围了呢,这会是什么问题。
——sess肯定超过索引了,那个sess(:,2)的值肯定超过V的行数了。
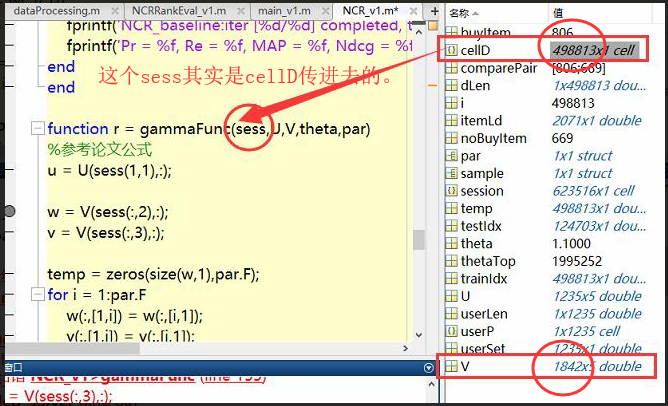
——由右图可知:V只有1842行,而cellD里面包含的肯定不止, 看是V错了, 还是cellD错了。
V的行数是整个数据集的所有item数目没错。而cellD的行数则是训练集的所有session数。
I mean:cellD里面包含的,每次肯定只能传cellD其中的一个元胞,把cellD里面每个元胞的最大值输出, 肯定有比1842大的,那么 怎么产生的问题就在哪了。
那么:把sess(:,2)最大值输出 和V的行比较即可见分晓:
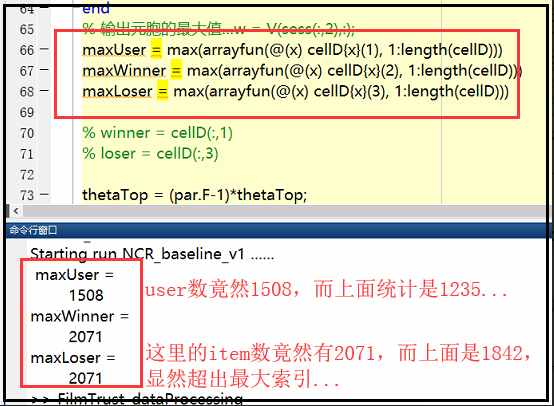
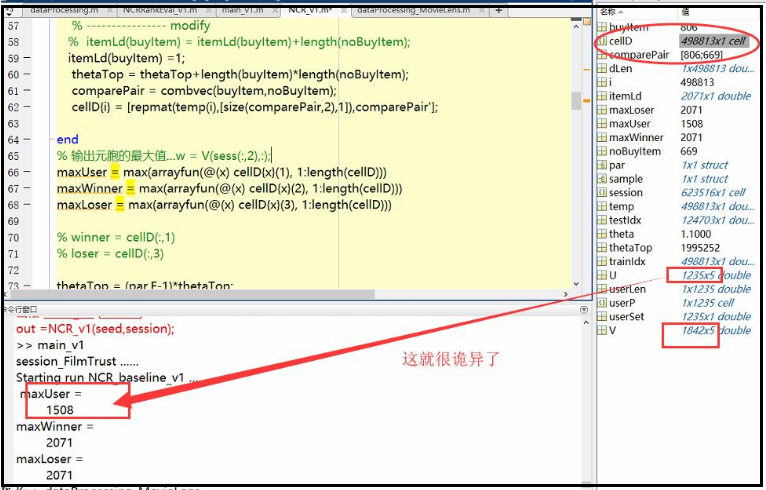
【原因】baseline里,原来生成的session.mat里面,userid、itemid是有重新编号的!!!按矩阵行序给userid和itemid编号的!!!
所以,回到数据预处理部分:
问题转变为:
以下rawData数据,第一列是userID,第二列是winner,第三列是loser。
现在要给它们的序号重排。userID 的序号重排是比较简单的。但是关于winner和loser这二者都是来自itemset,要将它们映射到同一个itemset,利用numunique可以操作吗?
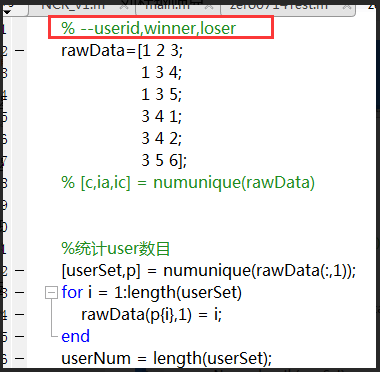
代码文件如下:
% --userid,winner,loser rawData=[1 2 3; 1 3 4; 1 3 5; 3 4 7; 3 4 2; 3 5 6]; %统计user数目 [userSet,p] = numunique(rawData(:,1)); for i = 1:length(userSet) rawData(p{i},1) = i; end userNum = length(userSet); %统计item数目---------原先 item1 = rawData(:,2); item2 = rawData(:,3); allItem = [item1', item2'] %合并所有item。 % 结果为:1×12double:2 3 3 4 4 5 3 4 5 7 2 6 unique_allItem = unique(allItem) % 对所有item去重并排序。 % 结果为:unique_allItem = 2 3 4 5 6 7 ,共6个 for i =1:length(unique_allItem) reSetAllItem (i) = i; end % 重新编号,从1开始。 % reSetAllItem 结果为:reSetAllItem = 1 2 3 4 5 6,共6个 itemNum = length(reSetAllItem) %利用combine矩阵,将原来的itemid与重排后的itemid对应起来。 combine = [unique_allItem',reSetAllItem'] % combine的结果为: % combine = % 2 1 % 3 2 % 4 3 % 5 4 % 6 5 % 7 6 %在combine矩阵查找,更新rawData的对应元素 for i = 1:length(rawData) for j = 1:length(combine) if rawData(i,2)==combine(j,1) rawData(i,2) = combine(j,2); end if rawData(i,3)==combine(j,1) rawData(i,3) = combine(j,2); end end end rawData % rawData的结果为: % rawData = % 1 1 2 % 1 2 3 % 1 2 4 % 2 3 6 % 2 3 1 % 2 4 5
运用到原问题上,即为:
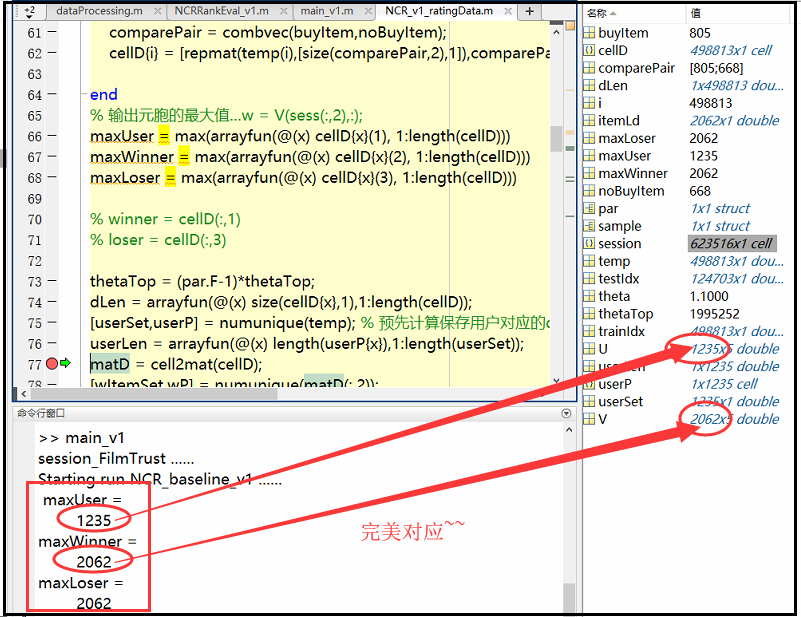


















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









