




简介:C语言编译器是将高级语言转换为机器可执行指令的关键工具。本文围绕“354654C语言编译器”展开,详细讲解其核心模块,包括词法分析、语法分析、目标码生成及代码优化等关键技术环节。通过分析编译器源码与相关文档,帮助开发者深入理解编译原理,掌握构建C语言编译器的核心流程与实现技巧,提升对编程语言底层机制的认知能力。
1. C语言编译器工作原理概述
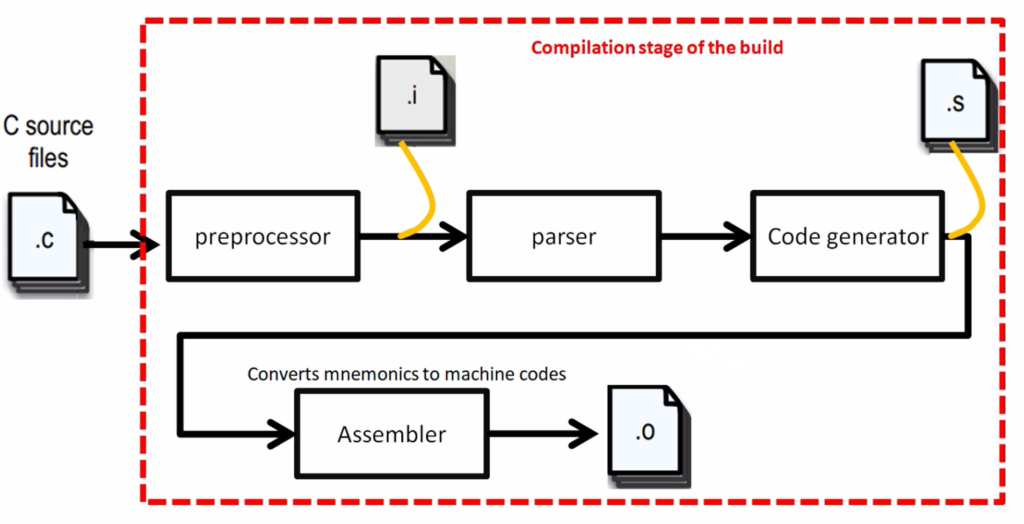
本章介绍C语言编译器的基本工作流程和核心组件,包括从源代码输入到可执行文件输出的全过程。编译器本质上是一个翻译系统,其主要任务是将高级语言(如C语言)转换为等价的、可被机器执行的低级语言(如汇编或机器码)。整个编译过程可分为多个阶段,包括词法分析、语法分析、语义分析、中间代码生成、优化和目标代码生成。这些阶段协同工作,确保程序逻辑被准确翻译,同时尽可能提升运行效率。理解编译器的工作原理不仅有助于深入掌握编程语言的本质,也为开发高性能、低错误率的系统软件打下坚实基础。
2. 词法分析器设计与实现
词法分析是编译过程的第一步,其核心任务是将字符序列转换为标记(Token)序列。这一步虽然在编译流程中处于基础层级,但其设计与实现直接影响后续语法分析的效率与准确性。本章将深入探讨词法分析器的设计原理与实现方法,涵盖基本概念、实现技术、优化策略与测试手段,帮助读者构建扎实的词法分析基础,为构建完整的编译器打下坚实的基础。
2.1 词法分析的基本概念
2.1.1 什么是词法单元(Token)
在编译过程中,词法单元(Token)是构成程序语言最小的语法单位。它由一个类别(Token Type)和一个值(Token Value)组成。例如,在表达式 int a = 10; 中,词法分析器会将其拆分为如下 Token:
| Token 类型 | Token 值 |
|---|---|
| 关键字 | int |
| 标识符 | a |
| 运算符 | = |
| 整数字面量 | 10 |
| 分号 | ; |
Token 的识别依赖于语言的词法规则,通常使用正则表达式来定义每种 Token 的格式。例如:
- 标识符可以定义为
[a-zA-Z_][a-zA-Z0-9_]* - 整数字面量可以定义为
[0-9]+ - 注释可以定义为
//.*或/\*.*?\*/(使用正则表达式)
词法分析器的任务就是按照这些规则逐个识别字符流中的 Token,并忽略空白字符和注释。
2.1.2 正则表达式与有限自动机(FA)的关系
正则表达式(Regular Expression)是描述词法规则的强大工具,而有限自动机(Finite Automaton, FA)则是实现正则表达式的计算模型。两者之间的关系可以通过以下方式理解:
- 正则表达式 用于定义 Token 的形式,例如:
regex integer: [0-9]+ identifier: [a-zA-Z_][a-zA-Z0-9_]* - 有限自动机 (FA)分为 确定有限自动机(DFA) 和 非确定有限自动机(NFA) 。它们用于模拟识别 Token 的过程。
- NFA 允许在某一状态下有多个转移路径,适合正则表达式的直接转换。
- DFA 是 NFA 的简化版本,每个状态只有一个确定的转移路径,便于实现高效识别。
示例流程图:正则表达式到有限自动机的转换过程
graph TD
A[正则表达式] --> B(构建NFA)
B --> C{是否需要优化?}
C -->|是| D[转换为DFA]
C -->|否| E[直接使用NFA]
D --> F[最小化DFA]
F --> G[生成状态转移表]
G --> H[词法分析器实现]
2.2 词法分析器的实现技术
2.2.1 使用 Lex/Flex 工具生成词法分析器
Lex 是一个经典的词法分析器生成工具,Flex(Fast Lex)是其 GNU 实现版本。开发者只需编写规则文件,Flex 会自动生成 C 语言的词法分析代码。
Flex 规则文件示例:
%{
#include <stdio.h>
%}
digit [0-9]
letter [a-zA-Z_]
"int" { printf("Keyword: %s\n", yytext); }
{letter}({letter}|{digit})* { printf("Identifier: %s\n", yytext); }
{digit}+ { printf("Integer: %s\n", yytext); }
"=" { printf("Operator: =\n"); }
";" { printf("Semicolon\n"); }
[ \t\n] ; // 忽略空白
. { printf("Unknown character: %s\n", yytext); }
int main(int argc, char **argv) {
yylex();
return 0;
}
逐行解析说明:
-
%{ ... %}:包含 C 头文件,用于后续函数调用。 -
digit和letter:定义宏,用于简化正则表达式。 -
%%:分隔规则部分与用户代码。 -
"int":匹配关键字,输出 Token 类型。 -
{letter}(...):匹配标识符,输出 Identifier。 -
{digit}+:匹配整数,输出 Integer。 -
"="和";":匹配运算符和分号。 -
[ \t\n]:匹配空白字符,不处理。 -
.:匹配任何未识别字符,输出 Unknown。 -
main():调用yylex()启动词法分析。
生成并运行命令:
flex lexer.l
gcc lex.yy.c -o lexer
./lexer < input.c
该方式的优点是开发效率高、规则清晰,适用于大多数语言的词法分析。
2.2.2 手动编写词法分析器的核心逻辑
对于某些特定场景(如嵌入式系统或教学目的),手动实现词法分析器更具灵活性。其核心逻辑包括:
- 字符读取 :从输入流中逐个读取字符。
- 状态机实现 :根据当前字符判断 Token 类型。
- 缓冲区管理 :暂存识别中的 Token。
- 错误处理 :处理非法字符和格式错误。
C语言手动实现示例:
#include <stdio.h>
#include <ctype.h>
#include <string.h>
char buffer[256];
int buf_index = 0;
void add_char(char c) {
buffer[buf_index++] = c;
buffer[buf_index] = '\0';
}
void clear_buffer() {
buf_index = 0;
buffer[0] = '\0';
}
int get_token(FILE *fp) {
int c;
clear_buffer();
while ((c = fgetc(fp)) != EOF) {
if (isspace(c)) {
if (c == '\n') return '\n';
continue;
}
if (isalpha(c) || c == '_') {
add_char(c);
while ((c = fgetc(fp)) != EOF && (isalnum(c) || c == '_')) {
add_char(c);
}
ungetc(c, fp);
if (strcmp(buffer, "int") == 0) return 'T_KEYWORD';
else return 'T_IDENTIFIER';
}
if (isdigit(c)) {
add_char(c);
while ((c = fgetc(fp)) != EOF && isdigit(c)) {
add_char(c);
}
ungetc(c, fp);
return 'T_INTEGER';
}
if (c == '=') {
return 'T_ASSIGN';
}
if (c == ';') {
return 'T_SEMICOLON';
}
return 'T_UNKNOWN';
}
return EOF;
}
int main() {
FILE *fp = fopen("input.c", "r");
int token;
while ((token = get_token(fp)) != EOF) {
switch (token) {
case 'T_KEYWORD': printf("Keyword: %s\n", buffer); break;
case 'T_IDENTIFIER': printf("Identifier: %s\n", buffer); break;
case 'T_INTEGER': printf("Integer: %s\n", buffer); break;
case 'T_ASSIGN': printf("Operator: =\n"); break;
case 'T_SEMICOLON': printf("Semicolon\n"); break;
case 'T_UNKNOWN': printf("Unknown character: %c\n", buffer[0]); break;
}
}
fclose(fp);
return 0;
}
逐行逻辑分析:
-
add_char():将字符添加到缓冲区,构建当前 Token。 -
clear_buffer():清空缓冲区,准备下一个 Token 的识别。 -
get_token():主函数,逐个读取字符并识别 Token。 - 若是字母或下划线,进入标识符识别流程。
- 若是数字,进入整数识别流程。
- 若是特殊字符(如
=、;),返回对应的 Token。 -
main():调用get_token()并打印 Token 类型。
该实现方式虽然代码量较大,但有助于深入理解词法分析机制,适合教学或小型项目。
2.3 词法分析器的优化与测试
2.3.1 性能优化策略
词法分析器的性能直接影响整个编译流程的效率。优化策略主要包括:
- 减少回溯 :避免频繁使用
ungetc(),尽量在读取字符时直接识别。 - 缓冲输入 :使用缓冲区一次性读取大块输入,减少 I/O 操作。
- 状态机优化 :使用 DFA 替代 NFA,提高识别效率。
- 预处理输入 :去除注释和空格,减少无效字符处理。
- 缓存 Token :对常见 Token(如关键字)进行缓存,提升识别速度。
2.3.2 词法分析结果的验证与调试
为了确保词法分析器的正确性,需进行系统性测试:
- 单元测试 :为每种 Token 编写测试用例,验证识别准确性。
- 边界测试 :测试最大长度的标识符、数字等边界情况。
- 错误注入测试 :插入非法字符,验证错误处理机制。
- 日志输出 :在调试阶段输出每一步识别过程,便于追踪问题。
- 性能测试 :测量处理大文件的耗时,评估性能瓶颈。
测试用例示例:
int main() {
int x = 10;
float y = 3.14;
char c = 'a';
return 0;
}
期望输出 Token 序列:
Keyword: int
Identifier: main
Operator: (
Operator: )
Semicolon
Keyword: int
Identifier: x
Operator: =
Integer: 10
Semicolon
Keyword: float
Identifier: y
Operator: =
Float: 3.14
Semicolon
Keyword: char
Identifier: c
Operator: =
Char: 'a'
Semicolon
Keyword: return
Integer: 0
Semicolon
通过构建全面的测试用例,可以有效验证词法分析器的功能与健壮性。
本章深入探讨了词法分析器的设计与实现方法,从 Token 的定义到正则表达式与有限自动机的关系,再到使用 Flex 工具与手动实现的具体步骤,最后介绍了优化与测试策略。通过本章内容,读者应能掌握构建高效、准确词法分析器的核心技术,并为后续语法分析奠定坚实基础。
3. 语法分析器设计与实现(BNF/EBNF语法规则)
语法分析是编译过程中的核心环节之一,其主要任务是根据词法分析器输出的 Token 序列,判断其是否符合某种定义良好的语法规则。语法分析器不仅需要识别出语法结构的正确性,还需要构建出程序的结构化表示,为后续的语义分析和代码生成提供基础。本章将围绕 BNF(Backus-Naur Form)和 EBNF(Extended Backus-Naur Form)等语法规则描述方式,深入探讨语法分析器的设计与实现方法。
3.1 上下文无关文法与语法分析基础
语法分析的核心是基于上下文无关文法(Context-Free Grammar, CFG)进行结构识别。上下文无关文法由一组产生式规则构成,这些规则定义了语言中合法句子的结构。
3.1.1 BNF与EBNF语法表示法
BNF(Backus-Naur Form)是最早用于描述程序设计语言语法的形式化表示方法。它通过非终结符、终结符、产生式等元素描述语言的结构。例如,一个简单的表达式文法可以用 BNF 表示如下:
<expr> ::= <term> | <expr> "+" <term>
<term> ::= <factor> | <term> "*" <factor>
<factor> ::= <number> | "(" <expr> ")"
在 BNF 中, ::= 表示“定义为”,尖括号 <...> 表示非终结符,而像 + 、 * 、 ( 、 ) 和 <number> 等则是终结符或进一步定义的非终结符。
EBNF(Extended BNF)是对 BNF 的扩展,引入了正则表达式中的某些符号,如 * (零次或多次)、 + (一次或多次)、 ? (可选)等,使得语法规则更加简洁易读。例如,上述 BNF 规则可改写为 EBNF 形式:
expr = term { "+" term } ;
term = factor { "*" factor } ;
factor = number | "(" expr ")" ;
| 特性 | BNF | EBNF |
|---|---|---|
| 表达能力 | 基础语法结构描述 | 更加简洁,支持循环、选择等结构 |
| 可读性 | 较低,需多个规则表达重复结构 | 高,使用符号简化规则书写 |
| 工具支持 | 多数编译器工具支持 BNF | 部分现代工具支持 EBNF |
代码示例:EBNF规则在Yacc/Bison中的使用
expr: term
| expr '+' term
;
term: factor
| term '*' factor
;
factor: NUMBER
| '(' expr ')'
;
这段 Bison 代码描述了与前面 EBNF 类似的语法结构。每个规则对应一个非终结符,冒号 : 后是产生式,竖线 | 表示“或”的关系。
逐行解释:
-expr: term表示 expr 可以由一个 term 构成。
-| expr '+' term表示 expr 也可以由 expr 加号 term 构成。
- 分号;表示该语法规则结束。
3.1.2 文法的歧义性与消除方法
歧义性(Ambiguity)是指一个句子可以对应多个不同的语法树结构。歧义文法在编译过程中会导致解析结果不确定,因此必须消除歧义。
示例:if-else 语句的歧义
考虑如下文法:
stmt = "if" expr "then" stmt
| "if" expr "then" stmt "else" stmt
| other_stmt ;
输入语句:
if a then if b then c else d
该语句可以被解释为:
if a then (if b then c) else d
或者:
if a then (if b then c else d)
这就是典型的“dangling-else”问题。
解决方法:
- 优先级设定 :为 else 子句赋予更高的优先级,使其与最近的未匹配的 if 匹配。
- 引入新的非终结符 :将匹配和未匹配的 if 语句分开处理,明确结构。
matched_stmt = "if" expr "then" matched_stmt "else" matched_stmt
| other_stmt ;
unmatched_stmt = "if" expr "then" stmt
| "if" expr "then" matched_stmt "else" unmatched_stmt ;
流程图说明:if-else 消除歧义的结构解析
graph TD
A[if a then ...] --> B{是否 else 存在?}
B -- 是 --> C[匹配 if a then (matched) else ...]
B -- 否 --> D[未匹配 if a then ...]
D --> E{下一层是否 else?}
E -- 是 --> F[if b then ... else ...]
E -- 否 --> G[if b then ...]
该流程图清晰地展示了不同情况下的匹配逻辑,有助于在语法分析器中实现 else 的绑定规则。
3.2 常用语法分析算法
语法分析算法主要分为两大类:自顶向下分析(Top-Down Parsing)和自底向上分析(Bottom-Up Parsing)。它们分别适用于不同类型的文法,并有各自的优缺点。
3.2.1 自顶向下分析:递归下降与LL(1)解析
自顶向下分析从文法的起始符号出发,尝试构建一棵语法树,逐步将非终结符替换为相应的产生式,直到与输入匹配。
LL(1) 分析器特点:
- LL 表示从左到右扫描输入,构造最左推导(Leftmost derivation)。
- 数字 1 表示向前查看一个输入符号(lookahead)。
- 要求文法为 LL(1) 文法,即每个非终结符的多个产生式的 FIRST 集合互不相交。
递归下降分析器实现示例(C语言)
void expr() {
term(); // 匹配 term
while (lookahead == '+') {
match('+'); // 匹配 '+' 符号
term(); // 匹配下一个 term
}
}
void term() {
factor(); // 匹配 factor
while (lookahead == '*') {
match('*');
factor();
}
}
void factor() {
if (lookahead == '(') {
match('(');
expr();
match(')');
} else if (isdigit(lookahead)) {
match(NUMBER);
} else {
error("Syntax error");
}
}
逐行解释:
-expr()表示对表达式的解析,先解析 term,然后循环处理 ‘+’ 操作。
-term()解析乘法操作。
-factor()处理括号和数字。
-match()函数用于消费当前 lookahead,并读取下一个字符。
-lookahead是当前输入字符,用于决定下一步操作。
优点:
- 实现简单,逻辑清晰。
- 适合手工编写。
缺点:
- 无法处理左递归文法。
- 需要预测产生式,因此要求文法为 LL(1)。
3.2.2 自底向上分析:LR(0)、SLR(1)与LALR(1)解析
自底向上分析从输入 Token 序列出发,逐步归约到文法的起始符号。常见的解析器类型包括 LR(0)、SLR(1)、LALR(1) 等。
LR(0) 分析器:
- 构建状态机,每个状态代表一个“项目集”(Item Set)。
- 使用栈进行归约和移进操作。
- 无需向前看符号(lookahead)。
SLR(1) 与 LALR(1):
- SLR(1) 在 LR(0) 的基础上引入 FOLLOW 集进行冲突解决。
- LALR(1) 是 SLR(1) 的增强版本,合并了具有相同核心的状态,减少了状态数量。
Bison 工具示例:
%token NUMBER
%left '+' '-'
%left '*' '/'
expr: expr '+' expr
| expr '*' expr
| '(' expr ')'
| NUMBER
;
逐行解释:
-%token定义终结符。
-%left定义运算符的结合性与优先级。
-expr: expr '+' expr表示表达式可以由两个 expr 加法构成。
- Bison 会自动生成 LALR(1) 分析器。
性能对比表:
| 分析器类型 | 是否支持左递归 | 是否需要 lookahead | 状态数 | 适用场景 |
|---|---|---|---|---|
| LL(1) | 否 | 是 | 少 | 小型语言、手动编写 |
| LR(0) | 是 | 否 | 多 | 简单文法 |
| SLR(1) | 是 | 是 | 中等 | 一般语言 |
| LALR(1) | 是 | 是 | 少 | 大型语言、工具生成 |
流程图:LALR(1) 解析过程
graph LR
A[输入Token流] --> B{状态栈}
B --> C[移进或归约]
C --> D[根据ACTION表选择动作]
D --> E{是否归约?}
E -- 是 --> F[执行归约并更新栈]
E -- 否 --> G[移进并更新栈]
G --> H[栈顶为接受状态?]
H -- 是 --> I[语法正确]
H -- 否 --> J[继续解析]
3.3 语法分析器的构建与调试
构建一个健壮的语法分析器不仅需要选择合适的算法和文法,还需要考虑错误处理与调试机制。
3.3.1 使用Yacc/Bison工具生成语法分析器
Yacc(Yet Another Compiler Compiler)和其 GNU 实现 Bison 是广泛使用的语法分析器生成工具。它们基于 LALR(1) 算法,可将 EBNF 规则转换为高效的解析代码。
使用流程:
- 编写
.y文件,定义词法规则和语法规则。 - 使用
bison -d parser.y生成.tab.c和.tab.h文件。 - 编写主函数和词法分析器接口。
- 编译并运行。
示例:Bison 主函数调用
#include "parser.tab.h"
int main(int argc, char **argv) {
yyparse(); // 调用语法分析器入口
return 0;
}
void yyerror(const char *s) {
fprintf(stderr, "Error: %s\n", s); // 错误处理函数
}
3.3.2 手动实现语法分析器的结构设计
对于某些特定场景,手动编写语法分析器更为灵活。结构设计通常包括:
- Token 结构体:
typedef enum {
TOK_PLUS, TOK_MUL, TOK_LPAREN, TOK_RPAREN, TOK_NUMBER, TOK_EOF
} TokenType;
typedef struct {
TokenType type;
int value; // 仅用于数字
} Token;
- 解析函数接口:
Token lookahead;
void match(TokenType expected);
void expr();
void term();
void factor();
3.3.3 语法错误处理与恢复机制
语法错误处理是语法分析器不可或缺的一部分。常见的错误恢复机制包括:
- 恐慌模式恢复(Panic Mode Recovery) :
- 忽略错误符号,直到遇到同步符号(如分号、右括号等)。
- 错误产生式 :
- 在文法中加入
error产生式,用于捕获错误并尝试恢复。
stmt: expr ';'
| "if" expr "then" stmt
| error ';' { yyerrok; }
;
yyerrok表示错误已处理,恢复解析。
流程图:错误恢复机制
graph LR
A[语法错误] --> B[跳过非法 Token]
B --> C{是否找到同步符号?}
C -- 是 --> D[继续解析]
C -- 否 --> E[继续跳过 Token]
D --> F[报告错误信息]
通过本章的深入分析,我们不仅掌握了 BNF/EBNF 语法规则的表示方法,还了解了主流的语法分析算法及其实现方式,并学习了语法分析器的构建与调试技巧。这些内容为后续章节中的语义分析与代码生成打下了坚实基础。
4. 抽象语法树(AST)构建
抽象语法树(Abstract Syntax Tree,AST)是编译流程中的关键数据结构,它以树状结构的形式表示程序的语法结构,忽略掉语法分析过程中的一些细节(如括号、分隔符等),保留语义信息。AST为后续的语义分析、中间代码生成、优化和目标码生成提供了清晰、结构化的基础。本章将从AST的基本概念出发,深入探讨其构建方法、遍历方式以及与语义分析的结合。
4.1 AST的基本概念与作用
AST是编译器在语法分析阶段生成的一种中间表示形式,它以树的形式表示程序的结构,每个节点代表一个语法构造,如表达式、语句、函数定义等。
4.1.1 AST与语法树的区别
| 对比项 | 语法树(Parse Tree) | 抽象语法树(AST) |
|---|---|---|
| 结构粒度 | 包含所有语法元素(如括号、关键字) | 只保留语义相关的结构 |
| 节点内容 | 每个语法规则产生一个节点 | 语义结构决定节点结构 |
| 应用阶段 | 语法分析阶段 | 语义分析及后续阶段 |
| 数据冗余度 | 较高,包含冗余符号 | 低,仅保留关键语义信息 |
| 实现复杂度 | 相对简单 | 需要手动设计节点结构 |
例如,C语言表达式 a + b * c 的语法树会包含乘法运算符、加法运算符及其括号结构(如果有的话),而AST则直接以 + 为根节点, a 为左子节点, * 为右子节点,其左右分别为 b 和 c 。
4.1.2 AST在编译流程中的关键作用
AST在编译器中承担了多个关键任务:
- 结构化表示程序逻辑 :便于后续处理和分析。
- 语义检查的基础 :变量类型检查、函数调用合法性等。
- 代码生成的起点 :将AST节点转换为中间代码或目标代码。
- 优化的数据结构 :基于AST进行代码优化,如常量折叠、表达式简化等。
- 代码重构和静态分析工具的基础 :如Clang AST用于代码分析、重构、插件开发等。
4.2 AST的构建方法
AST的构建通常发生在语法分析阶段之后,通过遍历语法分析器产生的语法结构,逐步构建出代表程序语义的树结构。
4.2.1 节点结构设计与内存管理
为了高效地构建和操作AST,需要设计良好的节点结构。以下是一个典型的C语言风格的AST节点结构定义:
typedef enum {
NODE_INT_LITERAL,
NODE_BINARY_OP,
NODE_VARIABLE,
NODE_ASSIGNMENT,
NODE_FUNCTION_CALL,
// 其他节点类型...
} NodeType;
typedef struct ASTNode {
NodeType type;
union {
int int_value;
struct {
char *name;
} var;
struct {
char op;
struct ASTNode *left;
struct ASTNode *right;
} bin_op;
// 其他字段...
};
} ASTNode;
节点结构设计要点:
- 使用联合体(union)实现多态节点结构。
- 类型字段(type)用于标识节点类型。
- 每个节点结构应包含其子节点的指针,以支持树的递归结构。
- 为每种节点类型设计独立的构造函数(如
new_int_node()、new_binary_node())以提高可维护性。
内存管理策略:
- 使用内存池(Memory Pool)管理AST节点,避免频繁的
malloc/free操作。 - 构建完成后统一释放整个AST的内存,减少内存泄漏风险。
- 在调试阶段启用内存检测工具(如Valgrind)确保内存安全。
4.2.2 递归构造AST的实现技巧
在语法分析过程中,AST的构建通常采用递归下降的方式。例如,在处理表达式时,根据运算符优先级递归构建子树。
以下是一个简化版的表达式解析和AST构造代码:
ASTNode* parse_expression(Parser *parser) {
return parse_additive(parser);
}
ASTNode* parse_additive(Parser *parser) {
ASTNode *left = parse_multiplicative(parser);
while (match(parser, '+') || match(parser, '-')) {
char op = previous_token(parser)->type;
ASTNode *right = parse_multiplicative(parser);
left = new_binary_node(op, left, right);
}
return left;
}
ASTNode* parse_multiplicative(Parser *parser) {
ASTNode *left = parse_primary(parser);
while (match(parser, '*') || match(parser, '/')) {
char op = previous_token(parser)->type;
ASTNode *right = parse_primary(parser);
left = new_binary_node(op, left, right);
}
return left;
}
ASTNode* parse_primary(Parser *parser) {
if (match(parser, TOKEN_INT)) {
return new_int_node(parser->previous.value);
} else if (match(parser, '(')) {
ASTNode *expr = parse_expression(parser);
consume(parser, ')', "Expected ')' after expression.");
return expr;
} else {
error(parser, "Expected expression.");
return NULL;
}
}
代码逻辑解读:
-
parse_expression()是入口函数,调用parse_additive()进行加减运算处理。 -
parse_additive()递归处理加减号,并构建二叉节点。 -
parse_multiplicative()处理乘除号,优先级高于加减。 -
parse_primary()处理基本表达式(如整数字面量或括号表达式)。 - 每次匹配到运算符后,创建新的
binary_op节点,将当前表达式与右侧新表达式组合。
参数说明:
-
Parser *parser:语法分析器上下文,用于读取和匹配输入标记。 -
match():判断当前标记是否为指定类型。 -
previous_token():获取上一个匹配的标记。 -
consume():消费指定标记,否则报错。 -
new_binary_node():创建一个新的二叉运算节点。
4.3 AST的遍历与优化
构建完AST之后,下一步是对其进行遍历和优化。常见的遍历方式包括前序、中序和后序遍历,而优化策略则包括常量折叠、冗余节点删除等。
4.3.1 前序、中序、后序遍历方式
遍历方式决定了处理节点的顺序:
graph TD
A[+] --> B[a]
A --> C[*]
C --> D[b]
C --> E[c]
遍历顺序示例:
- 前序遍历 (根左右):
+ a * b c - 中序遍历 (左根右):
a + b * c - 后序遍历 (左右根):
a b c * +
遍历函数实现示例(后序):
void post_order_traversal(ASTNode *node) {
if (!node) return;
switch (node->type) {
case NODE_BINARY_OP:
post_order_traversal(node->bin_op.left);
post_order_traversal(node->bin_op.right);
printf("Op: %c\n", node->bin_op.op);
break;
case NODE_INT_LITERAL:
printf("Int: %d\n", node->int_value);
break;
case NODE_VARIABLE:
printf("Var: %s\n", node->var.name);
break;
default:
printf("Unknown node type\n");
}
}
用途:
- 代码生成 :后序遍历适合生成目标码。
- 求值 :后序遍历可自然地用于表达式求值。
- 优化 :某些优化策略(如常量折叠)依赖遍历顺序。
4.3.2 AST简化与优化策略
优化策略示例:
- 常量折叠(Constant Folding) :
将常量表达式在编译时求值,例如将 3 + 5 替换为 8 。
```c
ASTNode optimize_constant_folding(ASTNode node) {
if (node->type == NODE_BINARY_OP) {
node->bin_op.left = optimize_constant_folding(node->bin_op.left);
node->bin_op.right = optimize_constant_folding(node->bin_op.right);
if (node->bin_op.left->type == NODE_INT_LITERAL &&
node->bin_op.right->type == NODE_INT_LITERAL) {
int result;
switch (node->bin_op.op) {
case '+': result = node->bin_op.left->int_value + node->bin_op.right->int_value; break;
case '-': result = node->bin_op.left->int_value - node->bin_op.right->int_value; break;
case '*': result = node->bin_op.left->int_value * node->bin_op.right->int_value; break;
case '/': result = node->bin_op.left->int_value / node->bin_op.right->int_value; break;
}
free(node->bin_op.left);
free(node->bin_op.right);
free(node);
return new_int_node(result);
}
}
return node;
}
```
- 冗余节点删除 :
删除无意义的节点,如 (a) 可以简化为 a 。
- 公共子表达式消除 :
若两个表达式相同,可复用计算结果。
优化前后对比:
| 原始表达式 | AST结构 | 优化后表达式 | AST结构 |
|---|---|---|---|
3 + (4 + 5) | 树形结构,两层加法 | 3 + 9 | 单层加法 |
a * 1 | 乘法节点,右为1 | a | 单变量节点 |
4.4 AST与语义分析的结合
AST不仅用于结构表示,更是语义分析的起点。语义分析通常包括:
- 类型检查 :变量是否已声明、运算是否类型匹配。
- 作用域分析 :变量是否在当前作用域内定义。
- 函数调用验证 :参数数量、类型是否正确。
- 控制流分析 :如
break是否在循环中使用。
示例:变量类型检查
假设AST中存在变量节点 NODE_VARIABLE ,我们需要在语义分析阶段查找其类型并检查是否匹配:
void check_variable_type(ASTNode *node, SymbolTable *symtab) {
if (node->type == NODE_VARIABLE) {
Symbol *sym = lookup_symbol(symtab, node->var.name);
if (!sym) {
fprintf(stderr, "Error: variable '%s' not declared\n", node->var.name);
exit(1);
}
node->type_info = sym->type;
} else if (node->type == NODE_BINARY_OP) {
check_variable_type(node->bin_op.left, symtab);
check_variable_type(node->bin_op.right, symtab);
// 检查左右操作数类型是否一致
if (node->bin_op.left->type_info != node->bin_op.right->type_info) {
fprintf(stderr, "Type mismatch in binary operation\n");
exit(1);
}
}
}
参数说明:
-
SymbolTable *symtab:符号表,保存变量名与类型的映射。 -
lookup_symbol():在符号表中查找变量。 -
type_info:节点类型信息字段。
实际意义:
- 提高程序安全性:避免运行时类型错误。
- 支持更高级的编译优化:如根据类型选择最优指令。
- 支持语言特性扩展:如泛型、模板等。
本章从AST的基本概念出发,深入讲解了其结构设计、构建方法、遍历与优化策略,以及如何与语义分析结合,为后续编译流程打下坚实基础。下一章将进入中间代码生成阶段,介绍如何从AST生成中间表示并进行优化。
5. 中间代码生成与优化技术
中间代码(Intermediate Representation,简称 IR)是现代编译器设计中的核心结构之一。它位于高级语言抽象和目标机器代码之间,承担着代码翻译与优化的双重使命。通过中间代码的构建与优化,编译器可以实现跨平台支持、提升执行效率,并为后续的代码生成提供良好的基础结构。本章将从IR的基本概念、生成过程、优化策略,以及SSA(Static Single Assignment)形式的高级优化技术等方面,全面剖析中间代码在现代编译器中的关键作用。
5.1 中间代码的概念与形式
中间代码是编译过程中的一个抽象表示层,用于在源语言和目标机器之间建立一个中立的、便于处理的代码形式。它的设计直接影响到编译器的可移植性、可维护性以及优化能力。
5.1.1 常见中间表示形式(IR)
中间代码的形式多种多样,常见的包括三地址码(Three-Address Code)、控制流图(Control Flow Graph,CFG)、静态单赋值形式(SSA)等。
| IR 形式 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 三地址码 | 每条指令最多包含三个操作数,通常为两个源操作数和一个目标操作数 | 简洁直观,适合教学与实现 | 表达能力有限,不便于优化 |
| 控制流图 | 以基本块为节点,边表示控制流转移 | 便于分析程序结构和流程 | 表示复杂,需结合其他IR形式 |
| 静态单赋值(SSA) | 每个变量只被赋值一次,便于数据流分析 | 高效支持优化,如常量传播、死代码消除 | 实现复杂,需插入Phi函数处理合并点 |
以三地址码为例,其典型形式如下:
t1 = a + b
t2 = t1 * c
d = t2
每条指令都只操作最多三个变量,这种形式便于后续的代码生成和优化处理。
5.1.2 IR的优缺点与适用场景
- 三地址码 :适用于教学编译器和小型编译器项目,易于理解和实现,但不便于进行复杂的优化操作。
- 控制流图(CFG) :用于分析程序流程,尤其在循环优化、异常处理中具有重要作用。
- 静态单赋值(SSA) :是现代工业级编译器(如LLVM、GCC)中广泛采用的形式,支持高级优化,但实现复杂。
不同IR形式的选择取决于编译器的目标和应用场景。例如,在嵌入式系统中,可能更倾向于使用三地址码;而在高性能编译器中,SSA则是首选。
5.2 中间代码生成过程
中间代码的生成是将AST(抽象语法树)转化为IR的过程,是编译流程中从高层语义到低层结构的转换关键。
5.2.1 从AST到IR的映射规则
AST的每个节点都对应源语言中的语法结构,如表达式、声明、控制结构等。将AST转换为IR的过程,通常采用递归下降的方式进行。
以表达式节点为例,考虑如下C代码:
int result = a + b * c;
对应的AST结构如下:
graph TD
A[result] --> B[=]
B --> C[a]
B --> D[+]
D --> E[b]
D --> F[*]
F --> G[c]
在转换为三地址码时,遵循运算优先级,生成如下IR:
t1 = b * c
t2 = a + t1
result = t2
每个操作符节点都被映射为一条三地址指令,临时变量(如t1、t2)被引入以保持每条指令的操作数数量不超过两个。
5.2.2 表达式、控制结构的IR表示
表达式的处理
表达式处理是中间代码生成的核心部分之一。以逻辑与( && )为例:
if (a > 0 && b < 10) {
// do something
}
转换为IR时,需要考虑短路求值特性,生成如下代码:
if a <= 0 goto L1
if b >= 10 goto L1
// body of if
L1:
其中, L1 是一个标签,表示跳转目标。
控制结构的处理
控制结构如 if-else 、 for 、 while 等,需要生成相应的控制流指令,并构建控制流图(CFG)。
例如, while 循环:
while (i < 10) {
i++;
}
对应的IR如下:
L0:
if i >= 10 goto L1
i = i + 1
goto L0
L1:
每个标签代表一个基本块的起始, goto 和 if 指令构成控制流转移。
5.3 中间代码优化技术
优化是中间代码阶段的重要任务,其目标是减少执行时间、降低内存占用或提升代码质量。常见的优化技术包括局部优化和全局优化。
5.3.1 局部优化:常量折叠、公共子表达式消除
常量折叠(Constant Folding)
常量折叠是指在编译阶段对常量表达式进行求值,避免在运行时重复计算。
例如:
x = 3 + 4 * 2;
优化后的IR为:
x = 11;
公共子表达式消除(Common Subexpression Elimination, CSE)
当两个表达式具有相同的输入和操作符时,可以只计算一次并将结果复用。
原始IR:
t1 = a + b
t2 = a + b
优化后:
t1 = a + b
t2 = t1
5.3.2 全局优化:循环不变代码移动、死代码消除
循环不变代码移动(Loop Invariant Code Motion)
将循环中不随迭代变化的代码移出循环体,以减少重复计算。
原始IR:
for (i = 0; i < N; i++) {
x = a + b;
arr[i] = x * i;
}
优化后:
x = a + b
for (i = 0; i < N; i++) {
arr[i] = x * i;
}
死代码消除(Dead Code Elimination)
删除程序中永远不会被执行的代码片段。
例如:
if (false) {
x = 10; // 死代码
}
优化后该部分代码将被移除。
5.4 基于SSA的高级优化简介
静态单赋值形式(SSA)是现代编译器中使用的一种高级IR形式,它通过限制变量只能被赋值一次,极大地简化了数据流分析和优化过程。
5.4.1 SSA的基本概念
在SSA中,每个变量只能被赋值一次,因此,当变量在不同路径中被赋予不同值时,需要使用 Phi函数 来合并值。
例如:
if (cond) {
x = 1;
} else {
x = 2;
}
y = x + 1;
在SSA中,x的两个赋值路径被表示为不同的版本,合并时使用Phi函数:
if cond {
x1 = 1;
} else {
x2 = 2;
}
x3 = phi(x1, x2)
y = x3 + 1;
5.4.2 SSA的优化能力
SSA形式极大地提升了以下优化的效率:
- 常量传播(Constant Propagation) :在数据流分析中更容易识别常量值。
- 死代码消除(Dead Code Elimination) :能够精确判断变量是否被使用。
- 循环优化(Loop Optimization) :便于识别和处理循环不变量。
例如,假设在SSA中某变量被赋值但从未使用,编译器可以安全地将其删除。
5.4.3 SSA的构建与退出
将普通IR转换为SSA形式的过程称为 SSA构造 ,通常包括变量重命名和Phi函数插入。退出SSA阶段时,需要进行 Phi合并 ,将多个变量版本合并为传统变量名,以便后续代码生成。
以下是构造SSA的简单算法步骤:
- 变量重命名 :为每个变量分配唯一的版本号。
- 插入Phi函数 :在控制流合并点插入Phi函数,合并不同路径的值。
- 数据流分析 :基于SSA进行优化。
- 退出SSA :将Phi函数替换为实际的寄存器拷贝或内存操作。
本章从中间代码的基本概念出发,深入探讨了其生成过程、优化策略以及SSA形式的高级优化机制。中间代码作为编译器中的关键结构,其设计与优化直接决定了编译器的性能与效率。在下一章中,我们将进入编译器的最后一环——目标代码生成,探讨如何将中间代码转化为可执行的汇编或机器码。
6. 目标码生成流程(汇编或机器码)
在编译器的整个流程中,目标码生成是最终将高级语言代码转化为底层可执行形式的关键步骤。它决定了程序在目标平台上的运行效率与兼容性。本章将详细介绍目标码生成的流程、关键技术,包括指令选择、寄存器分配、汇编语言输出、链接过程,以及目标码优化与跨平台适配策略。
6.1 目标代码生成的基本流程
目标码生成阶段的核心任务是将中间表示(IR)转换为具体的机器指令或汇编语言。这一过程涉及多个关键步骤:
6.1.1 指令选择与代码映射
指令选择(Instruction Selection)是将IR中的操作映射为具体目标平台的机器指令。该过程通常采用模式匹配技术,如树文法或指令模板匹配。
示例:
假设我们有如下IR表达式:
t1 = a + b
在x86架构下,可能的汇编代码为:
movl a, %eax
addl b, %eax
movl %eax, t1
指令选择的实现方式:
- 树文法匹配 :使用基于树的文法规则来匹配IR节点。
- 动态规划 :通过代价模型选择最优指令组合。
- 指令模板库 :为每种IR操作维护一组可选的机器指令模板。
6.1.2 寄存器分配与溢出处理
寄存器分配(Register Allocation)是将IR中的虚拟寄存器映射到目标平台的物理寄存器。由于物理寄存器数量有限,需要进行寄存器着色(Graph Coloring)或线性扫描(Linear Scan)等算法。
步骤简述:
1. 构建变量活跃区间(Live Range)。
2. 构建干扰图(Interference Graph)。
3. 使用着色算法为变量分配寄存器。
4. 若无法分配,则将变量溢出到栈(Spill to Stack)。
代码示例(伪代码):
def allocate_registers(ir):
interference_graph = build_interference_graph(ir)
coloring = graph_coloring(interference_graph, available_registers)
for var in ir.variables:
if var in coloring:
ir.replace(var, coloring[var]) # 替换为物理寄存器
else:
spill_to_stack(var) # 溢出到栈
溢出处理策略:
- 使用栈帧(Stack Frame)保存溢出变量。
- 插入 load/store 指令进行数据搬移。
- 优化溢出频率,减少访存开销。
6.2 汇编语言输出与链接
生成目标码的下一步是将中间指令转化为具体的汇编语言,并为链接器准备可重定位的目标文件。
6.2.1 AT&T与Intel汇编语法对比
不同的平台和工具链使用不同的汇编语法风格。常见的有 AT&T 与 Intel 两种格式。
| 特性 | AT&T 格式 | Intel 格式 |
|---|---|---|
| 操作数顺序 | 源在前,目标在后 | 目标在前,源在后 |
| 寄存器前缀 | % | 无前缀 |
| 立即数前缀 | $ | 直接写数字 |
| 内存寻址方式 | (base, index, scale) | [base + index*scale + offset] |
示例对比:
; AT&T 格式
movl $5, %eax
addl %ebx, %eax
; Intel 格式
mov eax, 5
add eax, ebx
6.2.2 与链接器的交互流程
目标码生成后,通常会输出为 ELF(Executable and Linkable Format)格式的目标文件。链接器(如 ld 或 gold )负责将多个目标文件合并为可执行文件。
链接流程步骤:
1. 符号解析(Symbol Resolution) :解析全局变量和函数引用。
2. 重定位(Relocation) :将相对地址转换为绝对地址。
3. 段合并(Section Merging) :将 .text 、 .data 等段合并。
4. 最终输出 :生成可执行文件或共享库。
示例命令:
gcc -c main.c -o main.o # 编译为目标文件
gcc -c utils.c -o utils.o
gcc main.o utils.o -o program # 链接生成可执行文件
6.3 目标码优化与性能调优
目标码优化直接影响程序的执行效率和资源利用率,是提升性能的关键环节。
6.3.1 指令级并行与调度
现代处理器支持指令级并行(Instruction-Level Parallelism, ILP),编译器可以通过指令调度(Instruction Scheduling)来提升指令吞吐率。
调度策略:
- 静态调度 :在编译时重排指令顺序,避免流水线停顿。
- 延迟槽填充(Delay Slot Filling) :在跳转指令后插入有用指令。
- 软件流水线(Software Pipelining) :优化循环体中的指令序列。
示例优化:
原始代码:
addl %eax, %ebx
movl (%esi), %ecx
subl %ecx, %edx
优化后(考虑数据依赖):
movl (%esi), %ecx
addl %eax, %ebx
subl %ecx, %edx
6.3.2 缓存优化与内存访问模式优化
内存访问效率对性能影响极大。目标码优化应关注以下方面:
- 局部性优化 :提高指令和数据的局部性,减少缓存缺失。
- 数据对齐 :按平台要求对齐数据结构,提升访问效率。
- 内存访问模式优化 :如将数组访问顺序改为按行优先,避免跨页访问。
示例:结构体内存对齐优化
struct Example {
char a;
int b; // 4字节对齐
short c; // 2字节对齐
};
优化后的结构体:
struct Example {
char a;
char pad[3]; // 填充3字节
int b;
short c;
char pad2[2]; // 填充2字节
};
6.4 平台适配与跨平台编译器设计思路
目标码生成的最后一步是平台适配。现代编译器(如 LLVM)支持多目标架构,其核心思想是将目标码生成模块解耦,便于移植。
平台适配关键点:
- 目标描述文件(Target Description) :定义寄存器集、指令集、调用约定等。
- 后端插件化设计 :将不同平台的代码生成逻辑模块化。
- 运行时支持库(Runtime Support) :如浮点运算库、异常处理支持。
跨平台编译器设计思路(以LLVM为例):
1. 前端将源代码转换为通用中间表示(LLVM IR)。
2. 中端进行通用优化。
3. 后端根据目标平台特性生成目标码。
graph TD
A[源代码] --> B(LLVM前端)
B --> C[LLVM IR]
C --> D[中端优化]
D --> E[目标后端]
E --> F[目标码输出]
跨平台示例:
clang -target arm-linux-gnueabi -mcpu=cortex-a9 -O2 main.c -o main_arm
clang -target x86_64-pc-linux-gnu -O2 main.c -o main_x86
以上命令使用 LLVM 的 Clang 编译器,为不同平台生成目标码。
本章深入讲解了目标码生成的全过程,从指令选择、寄存器分配到汇编输出、链接流程,再到性能优化与平台适配策略,为构建高性能、跨平台的编译器提供了技术支撑。下一章将进入运行时系统与内存管理环节,进一步探讨程序执行时的底层机制。
简介:C语言编译器是将高级语言转换为机器可执行指令的关键工具。本文围绕“354654C语言编译器”展开,详细讲解其核心模块,包括词法分析、语法分析、目标码生成及代码优化等关键技术环节。通过分析编译器源码与相关文档,帮助开发者深入理解编译原理,掌握构建C语言编译器的核心流程与实现技巧,提升对编程语言底层机制的认知能力。

















 3069
3069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









