



 本文深入解析Java堆和栈的区别,包括内存动态分配、存取速度、对象创建和内存分布。重点讲解了字符串共享实例,以及如何影响内存效率和程序性能。
本文深入解析Java堆和栈的区别,包括内存动态分配、存取速度、对象创建和内存分布。重点讲解了字符串共享实例,以及如何影响内存效率和程序性能。
堆和栈都是Java用来在RAM中存放数据的地方。
堆
(1)Java的堆是一个运行时数据区,类的对象从堆中分配空间。这些对象通过new等指令建立,通过垃圾回收器来销毁。
(2)堆的优势是可以动态地分配内存空间,需要多少内存空间不必事先告诉编译器,因为它是在运行时动态分配的。但缺点是,由于需要在运行时动态分配内存,所以存取速度较慢。
栈
(1)栈中主要存放一些基本数据类型的变量(byte,short,int,long,float,double,boolean,char)和对象的引用。
(2)栈的优势是,存取速度比堆快,栈数据可以共享。但缺点是,存放在栈中的数据占用多少内存空间需要在编译时确定下来,缺乏灵活性。
举例说明栈数据可以共享
String可以用以下两种方式来创建:
String str1 = new String("abc");
String str2= "abc";
第一种使用new来创建的对象,它存放在堆中。每调用一次就创建一个新的对象。
第二种是先在栈中创建对象的引用str2,然后查找栈中有没有存放“abc”,如果没有,则将“abc”存放进栈,并将str2指向“abc”,如果已经有“abc”,则直接将str2指向“abc”。
下面用代码说明上面的理论
public classDemo {public static voidmain(String[] args) {
String str1= new String("abc");
String str2= new String("abc");
System.out.println(str1==str2);
}
}
输出结果为:false
public classDemo {public static voidmain(String[] args) {
String str1= "abc";
String str2= "abc";
System.out.println(str1==str2);
}
}
输出结果为:true
因此,用第二种方式创建多个“abc”字符串,在内存中其实只存在一个对象而已。这种写法有利于节省内存空间。同时还可以提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否创建新对象。
代码一:
public classDemo {public static voidmain(String[] args) {
String s1= "china";
String s2= "china";
String s3= "china";
String ss1= new String("china");
String ss2= new String("china");
String ss3= new String("china");
}
}
思考:分布情况会怎样?
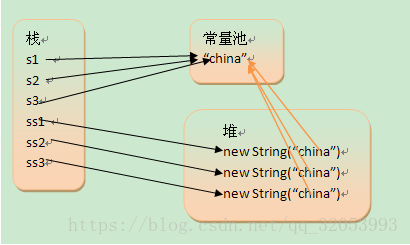
思考:为什么?
s1、s2、s3都是基本类型的局部变量,
ss1、ss2、ss3都是String对象的引用,
所以都在栈区
而"china"是常量,
所以放在常量区
而三个new的对象,
自然就放在堆区
代码二:
classBirthDate{private intday;private intmonth;private intyear;public BirthDate(int d, int m, inty) {
day=d;
month=m;
year=y;
}//省略get.set方法.
}public classTest{public static voidmain(String[] arg) {int date = 9;
Test test= newTest();
test.change(date);
BirthDate d1= new BirthDate(7,7,1970);
}public void change(inti){
i= 1234;
}
}
思考:内存如何分布?
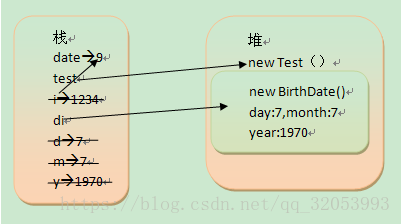
思考:为什么?
从执行代码部分看,
date, test, i, d1, d,m、y.
都属于基本类型的局部变量, 因此都分配到栈区。
而Test(),Birthdate()两个都是new出来的对象,因此都放在堆区。
---------------------
作者:Devin_教主
来源:优快云
原文:https://blog.youkuaiyun.com/qq_32053993/article/details/82812305

















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









