




简介:STL(标准模板库)是C++编程的重要基石,提供高效的数据结构与算法支持。本资料深入讲解STL五大核心组件:容器、迭代器、算法、函数对象和分配器,涵盖vector、list、map、unordered_map等常用容器,sort、find等常用算法,以及迭代器类型、仿函数使用和自定义分配器等内容。适合C++进阶开发者通过理论与实践结合,提升代码效率与模块化能力。
1. STL泛型编程与五大组件概述
STL(Standard Template Library)是C++标准库中最具影响力的部分,其核心理念是 泛型编程 ——通过模板机制实现与数据类型无关的通用算法和数据结构。这种设计不仅提高了代码复用性,还增强了程序的可维护性与扩展性。
STL由五大核心组件构成,分别是:
- 容器(Containers) :用于存储数据,如
vector、list、map等; - 迭代器(Iterators) :提供统一的访问接口,使算法可以独立于容器类型进行操作;
- 算法(Algorithms) :提供大量常用操作,如排序、查找、遍历等;
- 函数对象(Function Objects) :也称仿函数,用于将行为封装为对象,增强算法的灵活性;
- 分配器(Allocators) :负责内存管理,使得容器可以适配不同的内存模型。
这些组件之间高度解耦,却又紧密协作:算法通过迭代器操作容器中的元素,函数对象提供操作逻辑,而分配器则保障内存的高效使用。理解这种协作机制,是掌握STL编程的关键。
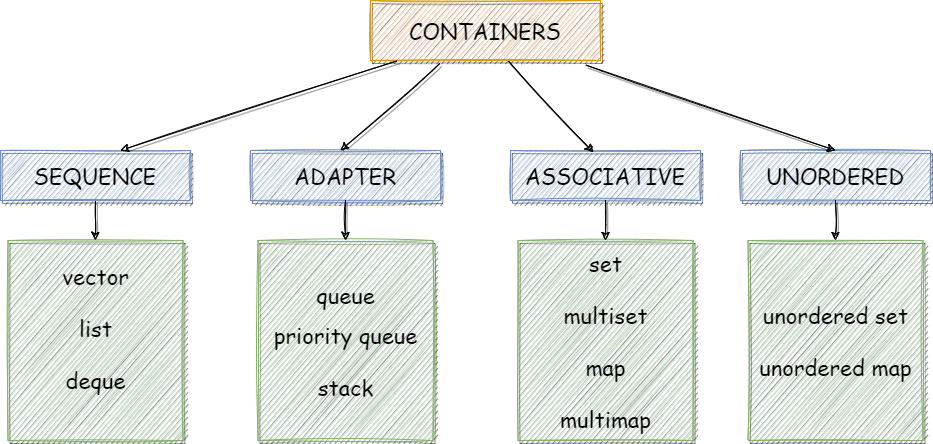
2. STL容器分类与核心容器详解
STL容器是C++标准模板库中最为基础且核心的组件之一。它们不仅提供了高效的数据结构实现,还通过统一的接口封装,使得开发者能够专注于逻辑设计,而非底层数据操作。STL容器根据其组织结构和访问方式,主要分为 序列式容器 (Sequence Containers)和 关联式容器 (Associative Containers),此外还有一类 容器适配器 (Container Adaptors)用于封装和扩展已有容器功能。
在本章中,我们将深入探讨这些容器的内部机制、使用场景及其性能特性,帮助读者在实际开发中做出合理的选择与应用。
2.1 容器的基本分类与使用场景
STL容器的分类依据是其数据组织方式和访问效率。理解它们的分类和特性,有助于我们在面对不同问题时,选择最合适的容器类型。
2.1.1 序列式容器与关联式容器的对比
| 分类 | 容器类型 | 特点描述 |
|---|---|---|
| 序列式容器 | vector , list , deque | 元素按顺序排列,支持随机或顺序访问,插入/删除效率因容器结构而异 |
| 关联式容器 | set , multiset , map , multimap | 元素自动排序,支持基于键的快速查找,底层多为红黑树实现 |
| 无序关联容器 | unordered_set , unordered_map | 基于哈希表实现,元素无序,查找效率更高(平均O(1)) |
| 容器适配器 | stack , queue , priority_queue | 基于已有容器封装,提供特定行为(如栈、队列、优先队列) |
序列式容器 强调元素的顺序性和访问方式,适合需要频繁访问和操作连续数据的场景;而 关联式容器 则强调元素的唯一性和查找效率,适合需要频繁进行查找、插入和删除操作的场景。
2.1.2 不同容器的性能特点与适用领域
| 容器类型 | 插入效率 | 查找效率 | 删除效率 | 典型应用场景 |
|---|---|---|---|---|
| vector | 尾插快 | 随机访问 | 尾删快 | 动态数组、需要快速随机访问的场合 |
| list | 插入快 | 顺序访问 | 插入快 | 需频繁插入/删除中间元素的场合 |
| deque | 头尾快 | 随机访问 | 头尾快 | 双端队列、频繁在首尾操作的场合 |
| set/map | O(log n) | O(log n) | O(log n) | 需要唯一键值、自动排序、快速查找的场合 |
| unordered_set/map | O(1) | O(1) | O(1) | 快速查找、允许重复键(multiset/map) |
| stack/queue | 封装底层 | 封装底层 | 封装底层 | 实现特定逻辑(如DFS、BFS、优先处理任务) |
通过对比可以发现,不同的容器在性能上各有千秋。例如, vector 在尾部操作上非常高效,但在中间插入或删除时需要移动大量元素;而 list 在插入和删除时非常高效,但无法支持快速的随机访问。
2.2 序列容器深入剖析
序列容器是STL中最基础的一类容器,它们以线性结构组织数据,并支持顺序或随机访问。下面我们分别深入分析 vector 、 list 和 deque 三种典型序列容器。
2.2.1 vector容器的动态扩容机制与使用技巧
vector 是一种动态数组,其核心特点是 支持随机访问 ,并且可以在运行时动态扩展。当元素数量超过当前容量时, vector 会自动分配新的内存空间,并将原有数据拷贝过去。
示例代码:vector动态扩容演示
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec;
for (int i = 0; i < 10; ++i) {
vec.push_back(i);
std::cout << "Size: " << vec.size()
<< ", Capacity: " << vec.capacity() << std::endl;
}
return 0;
}
输出结果:
Size: 1, Capacity: 1
Size: 2, Capacity: 2
Size: 3, Capacity: 4
Size: 4, Capacity: 4
Size: 5, Capacity: 8
Size: 6, Capacity: 8
Size: 7, Capacity: 8
Size: 8, Capacity: 8
Size: 9, Capacity: 16
Size: 10, Capacity: 16
逻辑分析与参数说明:
-
push_back():将元素插入到vector尾部。 -
size():返回当前元素个数。 -
capacity():返回当前内存分配的容量。 - 扩容机制:当
size() == capacity()时,vector会重新分配内存(通常是当前容量的两倍),并将旧数据复制到新内存中。
使用技巧:
- 预先调用
reserve()预留空间,避免频繁扩容。 - 使用
shrink_to_fit()释放多余内存。 - 避免在中间频繁插入/删除,否则会引发大量元素移动。
2.2.2 list容器的链表结构与插入删除性能分析
std::list 是双向链表结构,支持高效的插入和删除操作,但不支持随机访问。
示例代码:list插入与删除性能测试
#include <iostream>
#include <list>
#include <chrono>
int main() {
std::list<int> lst;
for (int i = 0; i < 10000; ++i) {
lst.push_back(i);
}
auto start = std::chrono::high_resolution_clock::now();
lst.insert(std::next(lst.begin(), 5000), 9999); // 在中间插入
auto end = std::chrono::high_resolution_clock::now();
std::cout << "Insertion time: "
<< std::chrono::duration_cast<std::chrono::microseconds>(end - start).count()
<< " μs" << std::endl;
return 0;
}
逻辑分析:
-
std::next():将迭代器前移5000次,定位到中间位置。 - 插入操作时间极短,因为链表只需调整指针,无需移动数据。
优势分析:
- 插入/删除时间复杂度为 O(1)(给定迭代器)。
- 内存分配灵活,适合元素频繁变动的场景。
- 缺点是无法随机访问,只能顺序遍历。
2.2.3 deque容器的双端队列实现原理
deque (double-ended queue)是一个支持在头部和尾部快速插入/删除的容器,其底层实现为 分段连续空间 ,每个分段称为一个“块”。
示例代码:deque双端插入性能测试
#include <iostream>
#include <deque>
#include <chrono>
int main() {
std::deque<int> dq;
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 100000; ++i) {
dq.push_front(i); // 头部插入
dq.push_back(i); // 尾部插入
}
auto end = std::chrono::high_resolution_clock::now();
std::cout << "Double-ended insertion time: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms" << std::endl;
return 0;
}
逻辑分析:
-
push_front()和push_back():分别在头部和尾部插入元素。 -
deque的双端操作效率高,适合实现双端队列、滑动窗口等结构。
deque结构示意图(mermaid):
graph LR
A[deque] --> B[Map]
B --> C[Block 1]
B --> D[Block 2]
B --> E[Block N]
C --> F[Data 0-999]
D --> G[Data 1000-1999]
E --> H[Data ...]
deque 通过“Map”管理多个“Block”,每个Block保存一定数量的元素。这种结构使得 deque 既支持快速的双端操作,又具备一定的随机访问能力。
2.3 关联容器深度解析
关联容器的特点是 自动排序 ,并支持基于键的快速查找。它们的底层实现通常是 红黑树 或 哈希表 。
2.3.1 set/multiset的底层红黑树实现与操作
set 是有序集合,元素不可重复; multiset 允许重复元素。它们的底层实现为 红黑树 ,支持高效的插入、删除和查找操作。
示例代码:set插入与查找操作
#include <iostream>
#include <set>
int main() {
std::set<int> s;
s.insert(5);
s.insert(3);
s.insert(8);
s.insert(5); // 重复插入无效
for (int x : s) {
std::cout << x << " ";
}
auto it = s.find(3);
if (it != s.end()) {
std::cout << "\nFound: " << *it << std::endl;
}
return 0;
}
输出结果:
3 5 8
Found: 3
操作说明:
-
insert():插入元素,若已存在则忽略。 -
find():查找元素,若存在返回迭代器,否则返回end()。 - 时间复杂度:O(log n),适用于需要快速查找且元素唯一或需排序的场景。
2.3.2 map/multimap的键值对管理与查找效率
map 是键值对容器,键唯一; multimap 允许键重复。它们同样基于红黑树实现。
示例代码:map键值对操作
#include <iostream>
#include <map>
int main() {
std::map<std::string, int> age;
age["Alice"] = 30;
age["Bob"] = 25;
age["Charlie"] = 35;
for (const auto& pair : age) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
if (age.count("Bob")) {
std::cout << "Bob's age: " << age["Bob"] << std::endl;
}
return 0;
}
操作说明:
-
operator[]:通过键访问值,若不存在则插入默认值。 -
count():判断键是否存在。 - 适用于需要通过键快速查找、更新、删除的场合,如配置表、缓存等。
2.3.3 unordered_set/unordered_map的哈希表实现与冲突解决
无序容器如 unordered_set 和 unordered_map 基于 哈希表 实现,元素无序,但查找效率更高(平均O(1))。
示例代码:unordered_map查找效率测试
#include <iostream>
#include <unordered_map>
#include <chrono>
int main() {
std::unordered_map<int, std::string> umap;
for (int i = 0; i < 100000; ++i) {
umap[i] = "value" + std::to_string(i);
}
auto start = std::chrono::high_resolution_clock::now();
auto it = umap.find(50000);
auto end = std::chrono::high_resolution_clock::now();
if (it != umap.end()) {
std::cout << "Found: " << it->second << std::endl;
}
std::cout << "Find time: "
<< std::chrono::duration_cast<std::chrono::microseconds>(end - start).count()
<< " μs" << std::endl;
return 0;
}
操作说明:
- 哈希函数将键映射到桶中,查找时直接定位,无需遍历。
- 冲突解决:使用链地址法或开放寻址法。
2.4 容器适配器的应用实践
容器适配器是对已有容器进行封装,提供特定接口的容器。常见的适配器包括 stack 、 queue 和 priority_queue 。
2.4.1 queue与stack的封装原理与应用场景
stack 和 queue 分别封装了LIFO(后进先出)和FIFO(先进先出)的行为。
示例代码:stack与queue的使用
#include <iostream>
#include <stack>
#include <queue>
int main() {
std::stack<int> s;
s.push(1);
s.push(2);
std::cout << "Stack top: " << s.top() << std::endl;
std::queue<int> q;
q.push(10);
q.push(20);
std::cout << "Queue front: " << q.front() << std::endl;
return 0;
}
封装说明:
-
stack默认基于deque实现,提供push,pop,top接口。 -
queue也默认基于deque,提供push,pop,front,back接口。
2.4.2 priority_queue的堆结构实现与优先级队列管理
priority_queue 是一个最大堆(默认),用于实现优先级队列。
示例代码:priority_queue的使用
#include <iostream>
#include <queue>
int main() {
std::priority_queue<int> pq;
pq.push(3);
pq.push(1);
pq.push(4);
pq.push(1);
while (!pq.empty()) {
std::cout << pq.top() << " ";
pq.pop();
}
return 0;
}
输出结果:
4 3 1 1
实现原理:
- 底层使用堆结构(默认大根堆),每次
top()返回最大值。 - 插入和删除时间复杂度均为 O(log n),适合任务调度、事件优先处理等场景。
本章通过理论与实践相结合的方式,深入剖析了STL容器的分类、核心实现与应用场景。在下一章中,我们将继续深入探讨STL的迭代器体系与算法基础,进一步提升对STL整体架构的理解与应用能力。
3. 迭代器体系与算法基础
在C++的STL中,迭代器是连接容器和算法的桥梁,它使得算法能够独立于容器的具体实现而操作数据。理解迭代器体系是掌握STL泛型编程的关键。本章将深入探讨迭代器的分类、常用STL算法的使用、迭代器适配器的应用以及算法与容器的结合实战,帮助开发者在实际项目中高效地使用STL。
3.1 迭代器的概念与分类
迭代器(Iterator)是STL中用于遍历容器元素的一种抽象机制。它类似于指针,但功能更加强大,支持多种操作方式。STL将迭代器分为五种基本类型,每种类型对应不同的访问能力和操作限制。
3.1.1 输入/输出/前向/双向/随机访问迭代器的功能区别
| 迭代器类型 | 功能特性 |
|---|---|
| 输入迭代器 | 只读,只能向前移动,适用于单次遍历(如 istream_iterator ) |
| 输出迭代器 | 只写,只能向前移动,适用于单次写入(如 ostream_iterator ) |
| 前向迭代器 | 支持读写,只能向前移动,适用于多次遍历 |
| 双向迭代器 | 支持读写,可向前和向后移动(如 list 、 set 的迭代器) |
| 随机访问迭代器 | 支持所有指针操作,如+、-、[]、<、>等(如 vector 、 deque 的迭代器) |
这些迭代器的划分依据是它们所支持的操作能力。例如, vector 的迭代器是随机访问类型,允许通过索引直接访问元素;而 list 的迭代器是双向类型,只能通过++或–逐个移动。
示例代码:不同容器迭代器的使用
#include <iostream>
#include <vector>
#include <list>
#include <set>
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
std::list<int> l = {10, 20, 30, 40, 50};
std::set<int> s = {100, 200, 300};
// vector的随机访问迭代器
for (auto it = v.begin(); it != v.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// list的双向迭代器
for (auto it = l.begin(); it != l.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// set的双向迭代器
for (auto it = s.begin(); it != s.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}
逐行解读分析:
- 第4~6行:引入头文件,包含
vector、list和set容器。 - 第8~12行:定义并初始化三个容器。
- 第15~19行:使用随机访问迭代器遍历
vector,支持++操作。 - 第20~24行:使用双向迭代器遍历
list,同样支持++操作。 - 第25~29行:使用
set的双向迭代器进行遍历。
3.1.2 各类容器所支持的迭代器类型
不同容器支持的迭代器类型不同,这与它们的底层实现结构密切相关。例如:
-
vector和deque:支持随机访问迭代器。 -
list和forward_list:支持双向或前向迭代器。 -
set、map、multiset、multimap:支持双向迭代器。 -
unordered_set、unordered_map:支持前向迭代器。
这种设计使得STL算法可以在不关心容器实现细节的前提下,通过迭代器抽象接口完成操作。
#include <iostream>
#include <vector>
#include <set>
#include <unordered_set>
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
std::set<int> s = {10, 20, 30, 40};
std::unordered_set<int> us = {100, 200, 300};
// vector的随机访问迭代器
std::cout << "vector随机访问:" << *(v.begin() + 2) << std::endl;
// set的双向迭代器
auto it = s.begin();
std::advance(it, 2);
std::cout << "set双向访问:" << *it << std::endl;
// unordered_set的前向迭代器
auto uit = us.begin();
++uit;
std::cout << "unordered_set前向访问:" << *uit << std::endl;
return 0;
}
逐行解读分析:
- 第11行:
vector的随机访问迭代器可以直接通过加法访问第三个元素。 - 第15行:
set的双向迭代器需通过std::advance移动两个位置。 - 第18行:
unordered_set的前向迭代器只能通过++操作访问下一个元素。
3.2 常用STL算法详解
STL算法库提供了大量通用算法,如排序、查找、元素操作等。这些算法通过迭代器操作数据,实现了与容器的解耦,提高了代码的复用性。
3.2.1 排序算法sort与稳定排序stable_sort
std::sort 是最常用的排序算法,其默认使用快速排序实现,时间复杂度为O(n log n)。而 std::stable_sort 则保证排序后相同元素的相对顺序不变,通常使用归并排序实现。
#include <iostream>
#include <vector>
#include <algorithm>
struct Student {
int age;
std::string name;
};
bool compare_by_age(const Student& a, const Student& b) {
return a.age < b.age;
}
int main() {
std::vector<Student> students = {
{22, "Alice"},
{20, "Bob"},
{22, "Charlie"},
{19, "David"}
};
// 使用stable_sort保证相同年龄的相对顺序
std::stable_sort(students.begin(), students.end(), compare_by_age);
for (const auto& s : students) {
std::cout << s.name << " (" << s.age << ")\n";
}
return 0;
}
逐行解读分析:
- 第8~12行:定义学生结构体及排序函数。
- 第17行:使用
stable_sort按年龄排序,相同年龄的保持原顺序。 - 第19~22行:输出结果,验证排序稳定性。
3.2.2 查找算法find与二分查找binary_search
std::find 用于在序列中查找特定元素,其时间复杂度为O(n)。而 std::binary_search 要求序列已排序,可在O(log n)时间内完成查找。
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {1, 3, 5, 7, 9};
// 查找是否存在元素5
if (std::find(v.begin(), v.end(), 5) != v.end()) {
std::cout << "元素5存在\n";
}
// 二分查找元素7
if (std::binary_search(v.begin(), v.end(), 7)) {
std::cout << "元素7存在\n";
}
return 0;
}
逐行解读分析:
- 第9行:使用
find查找元素5是否存在。 - 第13行:使用
binary_search查找元素7是否存在,要求容器已排序。
3.2.3 元素操作算法reverse、unique与copy
-
std::reverse:将容器元素逆序。 -
std::unique:去除相邻重复元素。 -
std::copy:复制元素到另一个容器。
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {1, 2, 2, 3, 4, 4, 5};
// 去重
auto last = std::unique(v.begin(), v.end());
v.erase(last, v.end());
// 逆序
std::reverse(v.begin(), v.end());
// 复制到新容器
std::vector<int> v2(v.size());
std::copy(v.begin(), v.end(), v2.begin());
for (int x : v2) {
std::cout << x << " ";
}
return 0;
}
逐行解读分析:
- 第10行:使用
unique去除相邻重复元素。 - 第11行:使用
erase真正删除多余元素。 - 第14行:使用
reverse将容器逆序。 - 第17~18行:使用
copy将元素复制到新容器v2中。
3.3 迭代器适配器的应用
STL提供了多种迭代器适配器,用于扩展迭代器的功能,如逆序访问、插入操作等。
3.3.1 reverse_iterator的逆序访问机制
reverse_iterator 是对普通迭代器的封装,使其按逆序访问容器元素。
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
// 使用reverse_iterator逆序遍历
for (auto rit = v.rbegin(); rit != v.rend(); ++rit) {
std::cout << *rit << " ";
}
return 0;
}
逐行解读分析:
- 第9行:使用
rbegin()和rend()获取逆序迭代器范围。 - 第10行:输出结果为
5 4 3 2 1。
3.3.2 counting_iterator与插入迭代器的使用场景
插入迭代器如 back_inserter 、 front_inserter 和 inserter 用于将算法结果插入容器。
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
int main() {
std::vector<int> src = {1, 2, 3, 4, 5};
std::vector<int> dst;
// 使用back_inserter将src复制到dst
std::copy(src.begin(), src.end(), std::back_inserter(dst));
for (int x : dst) {
std::cout << x << " ";
}
return 0;
}
逐行解读分析:
- 第13行:使用
back_inserter自动调用push_back将元素插入dst。 - 第15行:输出复制后的容器内容。
3.4 算法与容器的结合实战
STL算法与容器的结合使用可以极大提高代码的简洁性和效率。以下通过两个典型场景展示算法与容器的高效协作。
3.4.1 使用算法对vector进行高效排序与去重
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {5, 3, 5, 2, 3, 1, 2};
// 排序
std::sort(v.begin(), v.end());
// 去重
v.erase(std::unique(v.begin(), v.end()), v.end());
for (int x : v) {
std::cout << x << " ";
}
return 0;
}
逐行解读分析:
- 第11行:使用
sort将数组排序。 - 第14行:使用
unique去除相邻重复元素,并通过erase删除多余部分。
3.4.2 利用迭代器实现list容器的高效遍历与修改
#include <iostream>
#include <list>
#include <algorithm>
int main() {
std::list<int> lst = {10, 20, 30, 40, 50};
// 使用迭代器修改元素值
for (auto it = lst.begin(); it != lst.end(); ++it) {
*it *= 2;
}
for (int x : lst) {
std::cout << x << " ";
}
return 0;
}
逐行解读分析:
- 第11~13行:使用双向迭代器遍历
list,并对每个元素乘以2。 - 第15~16行:输出修改后的列表。
总结
迭代器体系是STL泛型编程的核心之一,它将容器与算法分离,使得代码具有高度的可复用性和灵活性。本章从迭代器的分类、常用算法的使用、迭代器适配器的扩展功能,以及算法与容器的结合实战四个方面,深入剖析了迭代器在STL中的重要作用。通过具体代码示例和逻辑分析,展示了如何在实际项目中高效使用STL迭代器与算法,提升开发效率与代码质量。
4. 函数对象与STL扩展功能
4.1 函数对象(仿函数)的设计与使用
4.1.1 函数对象与普通函数的区别
函数对象,也称为仿函数(Functor),是C++中一种将对象用作函数调用的技术。它本质上是一个类或结构体,重载了 operator() ,从而可以像普通函数一样被调用。与普通函数相比,函数对象具有更高的灵活性和状态保持能力。
| 特性 | 普通函数 | 函数对象 |
|---|---|---|
| 状态保持 | 无法保存状态 | 可以保存内部状态 |
| 函数指针 | 通过函数指针调用 | 通过对象实例调用 |
| 泛型支持 | 难以泛化 | 支持模板泛型编程 |
| 构造与析构 | 不涉及 | 可在构造/析构中执行初始化与清理 |
函数对象在STL中广泛应用于算法中,例如排序、查找、变换等操作。例如:
#include <iostream>
#include <vector>
#include <algorithm>
struct Square {
int operator()(int x) {
return x * x;
}
};
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
std::vector<int> result(vec.size());
std::transform(vec.begin(), vec.end(), result.begin(), Square());
for (int i : result) {
std::cout << i << " ";
}
return 0;
}
代码解析:
-
struct Square定义了一个函数对象,重载了operator()。 -
std::transform是一个STL算法,用于将输入范围的元素应用函数对象并输出到目标范围。 -
Square()创建了函数对象的临时实例并传入算法中。
执行流程:
- 定义一个
vector<int>,存储原始数据。 - 定义另一个
vector<int>用于存储变换结果。 - 使用
std::transform,将每个元素传入Square::operator()并计算平方。 - 最后输出结果。
4.1.2 自定义函数对象的实现方式
自定义函数对象的核心在于重载 operator() ,使得对象可以像函数一样被调用。函数对象可以携带状态,这在泛型算法中非常有用。
例如,定义一个带状态的函数对象,记录调用次数:
#include <iostream>
class Counter {
private:
int count;
public:
Counter() : count(0) {}
void operator()(int x) {
count++;
std::cout << "Call " << count << ": " << x << std::endl;
}
};
int main() {
Counter counter;
counter(10); // Call 1: 10
counter(20); // Call 2: 20
return 0;
}
代码分析:
-
Counter类维护了一个私有成员变量count,记录调用次数。 - 每次调用
operator()时,都会递增count并输出当前值。 - 函数对象可以像普通函数一样使用,但同时具有状态记忆功能。
优势:
- 函数对象比函数指针更灵活,可以在类中定义多个重载的
operator(),实现不同功能。 - 可以结合模板泛型编程,实现通用性更强的函数对象。
template<typename T>
class Adder {
private:
T value;
public:
Adder(T v) : value(v) {}
T operator()(T x) {
return x + value;
}
};
int main() {
Adder<int> add5(5);
std::cout << add5(10) << std::endl; // 输出 15
return 0;
}
逻辑分析:
-
Adder<T>是一个泛型函数对象,接受一个模板参数。 - 构造函数传入一个加法因子
value。 -
operator()接收一个参数x,并返回x + value。
4.2 标准函数对象的典型应用
4.2.1 less/greater比较器在排序中的应用
STL 提供了多种标准函数对象,用于排序、比较等操作。其中 std::less<T> 和 std::greater<T> 是最常用的比较器。
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional>
int main() {
std::vector<int> vec = {5, 3, 8, 1, 6};
// 使用 greater 进行降序排序
std::sort(vec.begin(), vec.end(), std::greater<int>());
for (int i : vec) {
std::cout << i << " ";
}
return 0;
}
执行结果:
8 6 5 3 1
逻辑分析:
-
std::greater<int>()是一个标准函数对象,用于比较两个整数的大小。 - 在
std::sort中传入该比较器后,排序顺序变为降序。
函数对象在算法中的作用流程图:
graph TD
A[算法入口] --> B{比较器类型}
B -->|less<T>| C[升序排序]
B -->|greater<T>| D[降序排序]
C --> E[调用operator()]
D --> E
E --> F[返回比较结果]
F --> G[完成排序]
4.2.2 bind绑定器在函数适配中的作用
std::bind 是 C++11 引入的标准库函数,用于将函数或函数对象的部分参数绑定,生成新的可调用对象。它在函数对象适配中非常有用。
#include <iostream>
#include <functional>
#include <vector>
#include <algorithm>
using namespace std::placeholders;
int multiply(int a, int b) {
return a * b;
}
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
std::vector<int> result(vec.size());
// 绑定第一个参数为2,生成新的函数对象
auto multiplyBy2 = std::bind(multiply, 2, _1);
std::transform(vec.begin(), vec.end(), result.begin(), multiplyBy2);
for (int i : result) {
std::cout << i << " ";
}
return 0;
}
输出结果:
2 4 6 8 10
逐行分析:
-
multiply是一个普通函数,接受两个整数并返回乘积。 -
std::bind(multiply, 2, _1)将第一个参数固定为 2,第二个参数使用占位符_1表示调用时传入。 -
multiplyBy2是一个新的可调用对象,相当于int multiplyBy2(int x) { return multiply(2, x); }。 - 使用
std::transform对整个容器应用该函数对象,完成乘法操作。
4.3 函数对象与算法结合的高级技巧
4.3.1 利用函数对象实现自定义排序逻辑
函数对象可以用于实现复杂的排序逻辑。例如,按字符串长度排序:
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
struct CompareByLength {
bool operator()(const std::string& a, const std::string& b) {
return a.length() < b.length();
}
};
int main() {
std::vector<std::string> words = {"apple", "banana", "pear", "grape", "kiwi"};
std::sort(words.begin(), words.end(), CompareByLength());
for (const auto& word : words) {
std::cout << word << " ";
}
return 0;
}
输出结果:
kiwi pear grape apple banana
分析:
-
CompareByLength是一个函数对象,重载了operator()来比较两个字符串的长度。 - 通过传入该函数对象,
std::sort实现了按长度排序的功能。
4.3.2 bind与lambda表达式在STL中的灵活使用
C++11 引入了 Lambda 表达式,使得函数对象的定义更加简洁。结合 std::bind ,可以实现非常灵活的函数适配。
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {10, 20, 30, 40, 50};
int factor = 3;
// 使用 lambda 表达式实现乘法变换
std::transform(vec.begin(), vec.end(), vec.begin(),
[factor](int x) { return x * factor; });
for (int i : vec) {
std::cout << i << " ";
}
return 0;
}
输出结果:
30 60 90 120 150
逻辑分析:
-
[factor](int x) { return x * factor; }是一个 Lambda 表达式,捕获factor并定义一个匿名函数对象。 - 该函数对象被传入
std::transform,完成对每个元素的乘法操作。
函数对象、bind 与 lambda 的关系图:
graph LR
A[函数对象] --> B[operator()]
C[bind] --> D[参数绑定]
E[Lambda] --> F[匿名函数对象]
B --> G[STL算法]
D --> G
F --> G
4.4 分配器(allocator)机制与自定义
4.4.1 分配器的基本职责与接口设计
分配器(Allocator)是 STL 中用于管理内存的组件。它定义了内存分配、释放、构造和析构的接口,使得容器可以独立于具体的内存管理策略。
标准分配器接口包括:
template <class T>
class allocator {
public:
T* allocate(size_t n); // 分配内存
void deallocate(T* p, size_t n); // 释放内存
void construct(T* p, const T& val); // 构造对象
void destroy(T* p); // 析构对象
};
默认情况下,STL 容器使用 std::allocator 进行内存管理。例如:
std::vector<int> vec; // 默认使用 std::allocator<int>
4.4.2 自定义分配器以提升内存管理效率
在某些高性能场景中,可以自定义分配器以优化内存分配策略。例如,实现一个简单的池式分配器:
#include <iostream>
#include <vector>
#include <memory>
template <typename T>
class SimplePoolAllocator {
public:
using value_type = T;
SimplePoolAllocator() = default;
template <typename U>
SimplePoolAllocator(const SimplePoolAllocator<U>&) {}
T* allocate(std::size_t n) {
std::cout << "Allocate " << n << " elements\n";
return static_cast<T*>(::operator new(n * sizeof(T)));
}
void deallocate(T* p, std::size_t n) {
std::cout << "Deallocate " << n << " elements\n";
::operator delete(p);
}
};
int main() {
std::vector<int, SimplePoolAllocator<int>> vec;
vec.push_back(10);
vec.push_back(20);
return 0;
}
输出结果:
Allocate 1 elements
Deallocate 1 elements
逻辑分析:
-
SimplePoolAllocator实现了allocate和deallocate方法。 - 在
vector定义时指定该分配器,使其使用自定义内存管理。 -
new和delete被重载,用于跟踪内存分配行为。
自定义分配器的使用流程图:
graph TD
A[容器创建] --> B[使用自定义分配器]
B --> C[调用allocate分配内存]
C --> D[执行构造函数]
D --> E[使用内存]
E --> F[调用deallocate释放内存]
通过自定义分配器,我们可以控制内存分配行为,从而在特定场景下优化性能,例如减少内存碎片、提高缓存命中率等。
5. STL进阶应用与性能优化
在掌握了STL的基本组件、容器、算法、迭代器、函数对象等核心概念后,我们进入了更深层次的使用场景: 性能优化 。STL虽然强大,但其默认行为并不总是最优的。在实际开发中,尤其是在处理大规模数据、高并发、内存敏感等场景下,开发者必须深入理解STL容器的底层实现机制,并结合具体业务需求进行针对性优化。本章将围绕 容器性能对比与选择策略、常见性能瓶颈与优化技巧、多线程环境下的STL使用注意事项、高性能STL应用案例分析 四个方向,系统讲解如何在真实项目中发挥STL的最大性能优势。
5.1 STL容器性能对比与选择策略
选择合适的容器是提升性能的第一步。STL提供了多种容器类型,它们在插入、删除、查找等操作的性能表现差异显著。了解这些差异有助于在不同场景下做出最优选择。
5.1.1 插入、删除与查找操作的效率分析
我们通过一张表格来对比常见容器在不同操作上的时间复杂度:
| 容器类型 | 插入(尾部) | 插入(中间) | 删除(尾部) | 删除(中间) | 查找(按值) |
|---|---|---|---|---|---|
vector | O(1) | O(n) | O(1) | O(n) | O(n) |
list | O(1) | O(1) | O(1) | O(1) | O(n) |
deque | O(1) | O(n) | O(1) | O(n) | O(n) |
map | - | O(log n) | - | O(log n) | O(log n) |
unordered_map | - | 平均 O(1) | - | 平均 O(1) | 平均 O(1) |
代码示例:不同容器插入性能对比
下面的代码展示了在 vector 和 list 中插入大量数据的性能差异。
#include <iostream>
#include <vector>
#include <list>
#include <chrono>
int main() {
const int N = 1000000;
std::vector<int> vec;
std::list<int> lst;
// 测试 vector 插入性能
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < N; ++i) {
vec.push_back(i);
}
auto end = std::chrono::high_resolution_clock::now();
std::cout << "vector 插入 " << N << " 次耗时: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms\n";
// 测试 list 插入性能
start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < N; ++i) {
lst.push_back(i);
}
end = std::chrono::high_resolution_clock::now();
std::cout << "list 插入 " << N << " 次耗时: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms\n";
return 0;
}
代码逻辑分析:
-
vector插入 :每次插入都可能触发扩容操作(通常为2倍增长),但大多数情况下是 O(1)。 -
list插入 :链表结构决定了插入操作始终为 O(1),但内存分配开销较大。 - 性能差异 :尽管
list插入复杂度低,但在实际测试中,vector因为缓存友好性更好,往往表现更优。
参数说明:
-
N:插入元素个数,可根据测试需求调整。 -
std::chrono:用于高精度计时。
5.1.2 内存占用与缓存友好性考量
除了操作复杂度,内存占用和缓存命中率也是选择容器的重要因素。
内存占用对比图(示意图)
graph TD
A[vector] --> B[内存连续]
C[list] --> D[内存分散]
E[map] --> F[红黑树结构]
G[unordered_map] --> H[哈希桶结构]
解释:
-
vector:内存连续,有利于 CPU 缓存预取,提高访问速度。 -
list:每个节点独立分配内存,造成内存碎片,且不利于缓存命中。 -
map/set:红黑树结构占用内存较多,适合需要有序性的场景。 -
unordered_map/unordered_set:哈希桶结构在查找快,但哈希冲突和扩容可能带来额外内存开销。
优化建议:
- 对于需要频繁访问的数据,优先选择
vector。 - 若频繁插入删除且无顺序要求,可考虑
unordered_map。 - 若需要有序性且数据量不大,使用
map。
5.2 常见性能瓶颈与优化技巧
尽管STL提供了高效的实现,但不当使用仍可能导致性能瓶颈。本节将介绍两个常见问题: vector 扩容机制的优化方法 和 map 查找效率的提升与避免重复插入。
5.2.1 vector扩容机制的优化方法
vector 在动态扩容时会重新分配内存并复制已有元素,这个过程可能成为性能瓶颈。我们可以通过以下方式优化:
使用 reserve() 预分配内存
std::vector<int> vec;
vec.reserve(1000000); // 预先分配内存
for (int i = 0; i < 1000000; ++i) {
vec.push_back(i);
}
代码解释:
-
reserve():仅分配内存,不构造对象。 - 避免多次扩容,提高性能。
- 若能预估数据量,应优先使用。
性能对比测试(伪代码)
// 无 reserve
std::vector<int> vec1;
for(...) push_back(); // 多次扩容
// 有 reserve
std::vector<int> vec2;
vec2.reserve(N);
for(...) push_back(); // 无扩容
优化建议:
- 预分配内存是
vector性能优化的关键。 - 若容器最终大小可预测,应尽量使用
reserve()。
5.2.2 map查找效率的提升与避免重复插入
map 的查找是 O(log n),但频繁插入重复键值可能导致性能下降。
使用 insert_or_assign (C++17)
std::map<int, std::string> m;
m.insert_or_assign(1, "one"); // 如果存在键1,更新值;否则插入
使用 try_emplace 避免构造临时对象
m.try_emplace(2, 3, 'a'); // 只有在键2不存在时才构造值
代码逻辑分析:
-
insert_or_assign:避免重复插入,同时更新值。 -
try_emplace:传参构造对象,避免临时对象构造,提升性能。
优化建议:
- 在插入前使用
find()检查是否存在,避免重复插入。 - 使用 C++17 的新方法提高效率。
5.3 多线程环境下的STL使用注意事项
STL容器本身不是线程安全的。在多线程环境下,若多个线程同时访问或修改容器,必须进行同步控制。
5.3.1 STL容器的线程安全性问题
- 只读访问 :多个线程可以安全地同时读取同一个容器。
- 写操作 :必须使用锁(如
mutex)保护。 - 并发读写 :必须加锁,否则会导致数据竞争和未定义行为。
示例代码:多线程写入 map
#include <iostream>
#include <map>
#include <thread>
#include <mutex>
std::map<int, int> data;
std::mutex mtx;
void insertData(int start, int end) {
for (int i = start; i < end; ++i) {
std::lock_guard<std::mutex> lock(mtx);
data[i] = i * i;
}
}
int main() {
std::thread t1(insertData, 0, 500000);
std::thread t2(insertData, 500000, 1000000);
t1.join();
t2.join();
std::cout << "Size: " << data.size() << std::endl;
return 0;
}
代码解释:
-
std::mutex:保证多线程对map的互斥访问。 -
std::lock_guard:RAII风格的锁,自动加锁和释放。
优化建议:
- 多线程写操作必须加锁。
- 可考虑使用
shared_mutex提高读并发性能。
5.3.2 使用锁机制保护共享数据
使用 shared_mutex 提高读并发
#include <shared_mutex>
std::map<int, int> data;
std::shared_mutex smtx;
// 读线程
void readData() {
std::shared_lock lock(smtx);
// 读取 data
}
// 写线程
void writeData(int key, int val) {
std::unique_lock lock(smtx);
data[key] = val;
}
说明:
-
shared_lock:允许多个线程同时读。 -
unique_lock:写时独占。
优化建议:
- 对读多写少的场景,优先使用
shared_mutex。 - 避免粒度过细的锁,减少锁竞争。
5.4 高性能STL应用案例分析
在实际项目中,如何结合业务场景选择和优化STL容器,是决定性能的关键。下面通过两个案例展示高性能STL的实际应用。
5.4.1 在大规模数据处理中的STL优化策略
场景 :读取1亿条数据,统计每个键的出现次数。
使用 unordered_map 进行统计:
std::unordered_map<int, int> counts;
for (const auto& key : data) {
counts[key]++;
}
优化点:
- 使用
unordered_map而非map,避免红黑树开销。 - 预分配桶数(bucket count)提升性能:
counts.rehash(1000000); // 设置桶数量
说明:
-
rehash():强制调整桶数,减少哈希冲突。 - 若数据量已知,提前 rehash 可显著提升效率。
5.4.2 高并发场景下的容器选择与内存管理
场景 :高并发服务器,处理百万级并发请求,需维护一个连接池。
使用 deque 作为连接池容器:
std::deque<Connection> pool;
std::mutex pool_mtx;
void addConnection(Connection conn) {
std::lock_guard<std::mutex> lock(pool_mtx);
pool.push_back(std::move(conn));
}
Connection getConnection() {
std::lock_guard<std::mutex> lock(pool_mtx);
if (!pool.empty()) {
Connection conn = std::move(pool.front());
pool.pop_front();
return conn;
}
return createNewConnection();
}
说明:
-
deque支持高效头尾操作,适合队列结构。 - 配合
mutex实现线程安全的连接池。
优化建议:
- 使用
std::move避免拷贝。 - 预分配内存池,减少动态分配。
本章通过性能对比、优化技巧、线程安全控制、实战案例四个维度,深入探讨了如何在实际项目中充分发挥STL的性能潜力。掌握这些内容,将使你在大规模、高性能、多线程项目中更加得心应手。
6. STL综合实战与项目应用
6.1 基于STL的数据结构与算法实现
STL的强大之处在于它不仅提供了基础数据结构和算法,还支持开发者将它们灵活组合,实现复杂的逻辑。本节将通过两个经典问题来演示如何使用STL进行数据结构与算法的实现。
6.1.1 使用vector与list实现图的邻接表存储
图的邻接表表示法非常适合使用STL中的 vector 和 list 组合实现。其中, vector 用于表示图中所有顶点,每个顶点对应一个 list ,存储其邻接顶点。
#include <iostream>
#include <vector>
#include <list>
using namespace std;
class Graph {
private:
int V; // 顶点数量
vector<list<int>> adjList; // 邻接表
public:
Graph(int V) : V(V), adjList(V) {}
// 添加边
void addEdge(int u, int v) {
adjList[u].push_back(v);
adjList[v].push_back(u); // 无向图双向添加
}
// 打印邻接表
void printGraph() {
for (int i = 0; i < V; ++i) {
cout << "顶点 " << i << " 的邻接顶点为: ";
for (int v : adjList[i]) {
cout << v << " ";
}
cout << endl;
}
}
};
int main() {
Graph g(5);
g.addEdge(0, 1);
g.addEdge(0, 4);
g.addEdge(1, 2);
g.addEdge(1, 3);
g.addEdge(2, 3);
g.addEdge(3, 4);
g.printGraph();
return 0;
}
代码解释:
-
vector<list<int>> adjList:每个顶点对应一个链表,保存其邻接点。 -
addEdge(int u, int v):在顶点u和v之间添加一条边,适用于无向图。 -
printGraph():遍历邻接表,打印每个顶点的邻接点。
6.1.2 利用priority_queue实现Dijkstra最短路径算法
Dijkstra算法用于求解单源最短路径问题,可以利用 priority_queue 高效实现。
#include <iostream>
#include <vector>
#include <queue>
#include <utility>
#include <climits>
using namespace std;
typedef pair<int, int> pii; // (距离, 顶点)
class Graph {
private:
int V;
vector<vector<pii>> adj;
public:
Graph(int V) : V(V), adj(V) {}
void addEdge(int u, int v, int weight) {
adj[u].push_back({v, weight});
adj[v].push_back({u, weight}); // 无向图
}
void dijkstra(int start) {
vector<int> dist(V, INT_MAX);
priority_queue<pii, vector<pii>, greater<pii>> pq;
dist[start] = 0;
pq.push({0, start});
while (!pq.empty()) {
int u = pq.top().second;
int d = pq.top().first;
pq.pop();
if (d > dist[u]) continue;
for (auto& edge : adj[u]) {
int v = edge.first;
int weight = edge.second;
if (dist[u] + weight < dist[v]) {
dist[v] = dist[u] + weight;
pq.push({dist[v], v});
}
}
}
cout << "从顶点 " << start << " 出发的最短路径为:" << endl;
for (int i = 0; i < V; ++i) {
cout << "顶点 " << i << ": " << dist[i] << endl;
}
}
};
int main() {
Graph g(5);
g.addEdge(0, 1, 10);
g.addEdge(0, 4, 5);
g.addEdge(1, 2, 1);
g.addEdge(1, 4, 2);
g.addEdge(2, 3, 4);
g.addEdge(3, 4, 3);
g.dijkstra(0);
return 0;
}
代码说明:
-
priority_queue<pii, vector<pii>, greater<pii>>:最小堆实现优先队列,按距离排序。 - 每次取出当前最短路径的顶点进行松弛操作,更新邻接顶点的距离。
- 时间复杂度为
O(E log V),适合中等规模图处理。
6.2 STL在实际项目中的典型应用
STL的高效性和可扩展性使其在实际项目中被广泛使用,特别是在数据处理和查找优化方面。
6.2.1 使用map实现词频统计工具
#include <iostream>
#include <fstream>
#include <sstream>
#include <map>
#include <string>
using namespace std;
int main() {
ifstream file("sample.txt");
map<string, int> wordCount;
string line, word;
while (getline(file, line)) {
istringstream iss(line);
while (iss >> word) {
++wordCount[word];
}
}
for (const auto& pair : wordCount) {
cout << pair.first << " : " << pair.second << endl;
}
return 0;
}
说明:
-
map<string, int>:用于保存单词和出现次数。 - 使用
ifstream读取文件内容,istringstream逐行分割单词。 - 最终输出每个单词及其出现次数。
6.2.2 利用unordered_map优化大规模查找场景
相比 map , unordered_map 基于哈希表实现,查找效率为 O(1) ,适合大规模数据查找。
#include <iostream>
#include <unordered_map>
#include <vector>
using namespace std;
int main() {
unordered_map<int, string> userMap;
vector<int> queries = {1001, 1003, 1002, 1001};
// 初始化数据
userMap[1001] = "Alice";
userMap[1002] = "Bob";
userMap[1003] = "Charlie";
for (int id : queries) {
if (userMap.find(id) != userMap.end()) {
cout << "用户ID " << id << " 对应姓名: " << userMap[id] << endl;
} else {
cout << "用户ID " << id << " 不存在" << endl;
}
}
return 0;
}
说明:
-
unordered_map<int, string>:用于快速查找用户信息。 -
find方法查找是否存在该键,时间复杂度接近常数级。
6.3 STL在系统开发中的高级应用
STL不仅可以用于算法和数据结构,还能在系统级开发中扮演重要角色。
6.3.1 利用STL构建配置文件解析模块
#include <iostream>
#include <fstream>
#include <sstream>
#include <map>
#include <string>
using namespace std;
map<string, string> parseConfig(const string& filename) {
map<string, string> config;
ifstream file(filename);
string line;
while (getline(file, line)) {
size_t pos = line.find('=');
if (pos != string::npos) {
string key = line.substr(0, pos);
string value = line.substr(pos + 1);
config[key] = value;
}
}
return config;
}
int main() {
auto config = parseConfig("config.ini");
for (const auto& pair : config) {
cout << pair.first << " = " << pair.second << endl;
}
return 0;
}
说明:
-
parseConfig函数读取配置文件,按=分割键值对。 - 使用
map<string, string>保存配置项,便于后续使用。
6.3.2 基于STL的线程池设计与实现
#include <iostream>
#include <thread>
#include <vector>
#include <queue>
#include <functional>
#include <mutex>
#include <condition_variable>
using namespace std;
class ThreadPool {
private:
vector<thread> workers;
queue<function<void()>> tasks;
mutex mtx;
condition_variable cv;
bool stop = false;
public:
ThreadPool(size_t threads) {
for (size_t i = 0; i < threads; ++i) {
workers.emplace_back([this] {
while (true) {
function<void()> task;
{
unique_lock<mutex> lock(this->mtx);
this->cv.wait(lock, [this] { return this->stop || !this->tasks.empty(); });
if (this->stop && this->tasks.empty()) return;
task = move(this->tasks.front());
this->tasks.pop();
}
task();
}
});
}
}
template<class F>
void enqueue(F&& f) {
{
lock_guard<mutex> lock(mtx);
tasks.emplace(forward<F>(f));
}
cv.notify_one();
}
~ThreadPool() {
{
lock_guard<mutex> lock(mtx);
stop = true;
}
cv.notify_all();
for (thread& worker : workers) {
worker.join();
}
}
};
int main() {
ThreadPool pool(4);
for (int i = 0; i < 8; ++i) {
pool.enqueue([i] {
cout << "执行任务 " << i << " in thread " << this_thread::get_id() << endl;
this_thread::sleep_for(chrono::milliseconds(100));
});
}
return 0;
}
说明:
- 使用
queue<function<void()>>保存任务队列。 - 多线程环境下使用
mutex和condition_variable进行同步。 - 线程池自动管理线程生命周期,适合高并发任务调度。
6.4 STL在C++11/14/17新标准下的演进
随着C++标准的不断演进,STL也引入了大量新特性,提升了代码的可读性和性能。
6.4.1 新增容器与算法的支持情况
C++11引入了 unordered_set 、 unordered_map 等哈希容器,C++17新增了 std::variant 、 std::optional 等类型安全容器。例如:
#include <iostream>
#include <variant>
int main() {
variant<int, double, string> v = 3.14;
cout << "当前类型为: " << v.index() << endl; // 输出 1
v = "hello";
cout << "当前值为: " << get<string>(v) << endl;
return 0;
}
6.4.2 Lambda表达式与智能指针在STL中的融合应用
Lambda表达式使得STL算法可以更简洁地传入逻辑:
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
vector<int> nums = {1, 2, 3, 4, 5};
int threshold = 3;
auto it = find_if(nums.begin(), nums.end(), [threshold](int x) {
return x > threshold;
});
if (it != nums.end()) {
cout << "第一个大于 " << threshold << " 的数是: " << *it << endl;
}
return 0;
}
智能指针如 shared_ptr 、 unique_ptr 与容器结合,有效避免内存泄漏:
#include <iostream>
#include <vector>
#include <memory>
int main() {
vector<shared_ptr<int>> vec;
vec.push_back(make_shared<int>(10));
vec.push_back(make_shared<int>(20));
for (auto ptr : vec) {
cout << *ptr << " ";
}
cout << endl;
return 0;
}
本节展示了STL在现代C++中的强大能力,不仅支持传统算法与数据结构,还与现代语言特性深度融合,成为构建高性能C++程序的核心工具之一。
简介:STL(标准模板库)是C++编程的重要基石,提供高效的数据结构与算法支持。本资料深入讲解STL五大核心组件:容器、迭代器、算法、函数对象和分配器,涵盖vector、list、map、unordered_map等常用容器,sort、find等常用算法,以及迭代器类型、仿函数使用和自定义分配器等内容。适合C++进阶开发者通过理论与实践结合,提升代码效率与模块化能力。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









