



 该博客讨论了如何在Python的Matplotlib库中创建一个显示多个类别的随机散点图,同时保持数据的随机分布,并正确设置图例。作者遇到了在保留随机性与正确标签之间做出选择的问题。通过使用颜色映射和循环遍历不同类别,解决了这个问题,使得点的分布保持随机,同时每个类别的点都有独特的颜色和对应的图例。此外,还对比了使用ggplot2在R中实现相同效果的方法。
该博客讨论了如何在Python的Matplotlib库中创建一个显示多个类别的随机散点图,同时保持数据的随机分布,并正确设置图例。作者遇到了在保留随机性与正确标签之间做出选择的问题。通过使用颜色映射和循环遍历不同类别,解决了这个问题,使得点的分布保持随机,同时每个类别的点都有独特的颜色和对应的图例。此外,还对比了使用ggplot2在R中实现相同效果的方法。
我试图在python/matplotlib中构建来自多个类的大量数据的散点图。不幸的是,我不得不在随机数据和图例标签之间做出选择。有没有一种方法可以两者兼得(最好不用手动编码标签?)在
最小可重复性示例:import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
X = np.random.normal(0, 1, [5000, 2])
Y = np.random.normal(0.5, 1, [5000, 2])
data = np.concatenate([X,Y])
classes = np.concatenate([np.repeat('X', X.shape[0]),
np.repeat('Y', Y.shape[0])])
用随机点绘制:
^{pr2}$
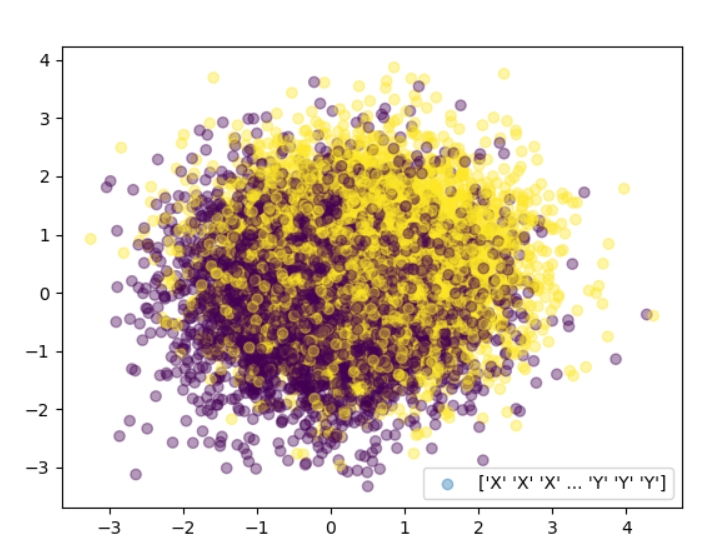
这给了我一个错误的传说。在
用正确的图例绘制:from matplotlib import cm
unique_classes = np.unique(classes)
colors = cm.Set1(np.linspace(0, 1, len(unique_classes)))
for i, class in enumerate(unique_classes):
ax.scatter(data[classes == class, 0],
data[classes == class, 1],
c=colors[i],
label=class,
alpha=0.4)
plt.legend()
plt.show()
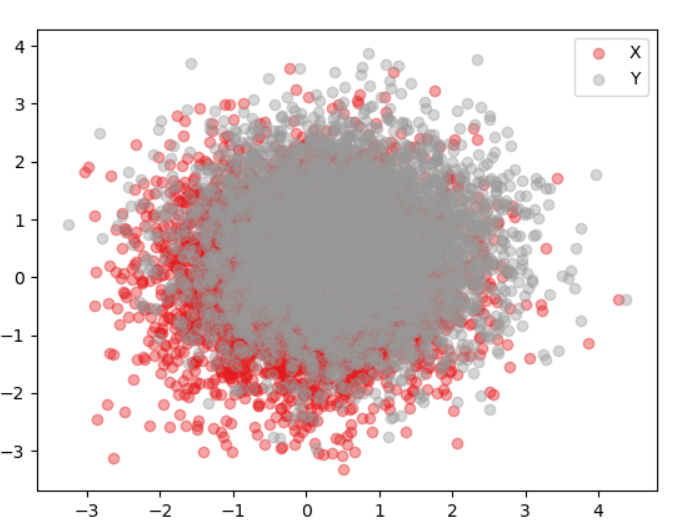
但现在这些点并没有随机化,结果图也不能代表数据。在
我在寻找一些东西,可以得到如下的结果:library(ggplot2)
X
Y
data
data$classes
plot_idx
ggplot(data[plot_idx,], aes(x=V1, y=V2, color=classes)) +
geom_point(alpha=0.4, size=3)
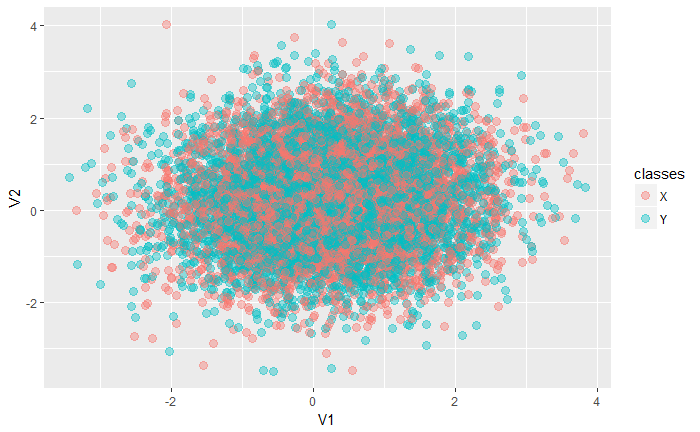

















 5481
5481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









