 RTX4090云显卡与AI伦理
RTX4090云显卡与AI伦理




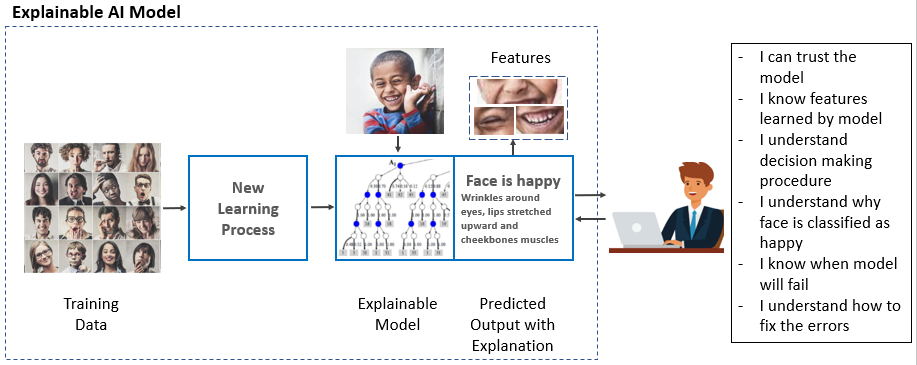
1. AI伦理问题的兴起与技术背景
随着人工智能技术的迅猛发展,深度学习模型对计算资源的需求呈指数级增长。RTX4090作为当前消费级显卡中的性能巅峰,凭借其强大的浮点运算能力、高达24GB的显存以及对CUDA和Tensor Core的全面支持,已成为本地训练中小型AI模型的重要硬件基础。然而,随着云计算平台广泛集成RTX4090级别的虚拟GPU实例,“云显卡”正成为AI开发的新范式。
AI算力平民化背后的伦理隐忧
算力的“democratization”使得个人开发者、研究机构甚至恶意行为者都能以较低成本获取前所未有的计算能力。这种技术可及性的提升,在加速创新的同时,也显著降低了滥用AI的技术门槛。例如,利用单块RTX4090即可在数小时内完成人脸深度伪造模型的微调(如使用StyleGAN3 + FaceSwap),或在云端租用多卡实例进行大规模语言模型的非法数据爬取与训练。
# 示例:基于RTX4090的轻量级LoRA微调脚本片段
import torch
from peft import LoRAConfig, get_peft_model
model = torch.load("llama-7b.bin").cuda() # 模型加载至显存
lora_config = LoRAConfig(r=8, lora_alpha=16, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config) # 添加低秩适配
# 此类操作可在云显卡上匿名运行,监管难度大
该现象凸显了一个核心问题: 技术能力与伦理约束之间的脱节 。高性能算力本身虽无善恶之分,但其使用的匿名性、跨境流动性与高效率,为虚假信息生成、隐私侵犯和算法歧视提供了温床。尤其在缺乏有效审计机制的云环境中,RTX4090级别算力可能被用于自动化操控舆论、批量生成诈骗语音或非法监控系统集成。
技术演进与伦理挑战的共生关系
回顾AI发展历程,伦理问题始终紧随技术突破而来。从早期专家系统的决策黑箱,到大数据时代的隐私泄露,再到如今生成式AI的泛滥式内容生产,每一次能力跃迁都重构了人机关系和社会信任边界。而RTX4090所代表的高算力终端,正是这一演进链条上的关键节点——它不仅是工具,更是权力的载体。
本章旨在揭示:AI伦理已不再局限于算法设计层面的公平性讨论,而必须扩展至 基础设施层的治理 。只有理解高性能显卡如何改变AI开发范式,才能前瞻性地构建覆盖“硬件—平台—用户”的全链路伦理框架,为后续章节的理论分析与实践方案提供坚实支撑。
2. AI伦理的核心理论框架
人工智能技术的迅猛发展,已经超越了单纯的技术演进范畴,逐步嵌入社会运行的深层结构。从自动驾驶决策到信贷评分系统,从医疗诊断辅助到司法风险评估,AI正在参与甚至主导关键性社会判断。这一转变使得“技术中立”的传统假设受到严峻挑战。在RTX4090级别算力被广泛部署于云端、可被全球用户按需调用的背景下,AI系统的潜在影响范围急剧扩大。一个未经充分伦理审查的模型,借助高性能云显卡完成训练后,可能在数小时内生成成千上万条虚假信息或执行大规模隐私侵犯行为。因此,构建一套系统化、可操作的AI伦理理论框架,成为当前技术治理的紧迫任务。
该框架不仅需要回应传统伦理学中的公平、责任与权利问题,还需适应分布式计算环境下的新现实——即开发者与使用者地理分离、平台中介作用增强、硬件资源高度集中等特征。本章将深入剖析AI伦理的三大核心支柱:基本原则体系、算力分配困境以及技术中立性的哲学争议,并结合现代GPU云计算的实际场景,探讨这些抽象理念如何转化为具体的责任边界与制度设计。
2.1 AI伦理的基本原则体系
AI伦理并非空泛的道德说教,而是建立在一系列可验证、可实施的基本原则之上。这些原则构成了技术开发与应用过程中的“价值锚点”,为政策制定、系统设计和公众监督提供依据。其中, 公平性、透明性与可解释性 是公认的三大基石,它们共同指向一个核心诉求:确保AI系统不会在无意识或隐蔽状态下加剧社会不公、剥夺个体权利或逃避问责。
2.1.1 公平性、透明性与可解释性的定义边界
“公平性”在AI语境下远比日常理解复杂。它不仅指算法对待不同群体的一视同仁,更涉及对历史偏见的识别与修正。例如,在招聘筛选模型中,若训练数据反映过往性别歧视现象(如男性工程师占比过高),模型可能学习到“男性更适合技术岗位”的错误关联,从而在预测时系统性地降低女性候选人的评分。这种偏差虽非开发者主观意图,却构成事实上的结构性歧视。
为此,研究者提出了多种数学化的公平性度量标准,以量化并监控模型行为:
| 公平性准则 | 数学表达式 | 适用场景 |
|---|---|---|
| 统计均等(Statistical Parity) | $ P(\hat{Y}=1 \mid A=0) = P(\hat{Y}=1 \mid A=1) $ | 关注结果分布一致性,适用于资源分配类任务 |
| 机会均等(Equal Opportunity) | $ P(\hat{Y}=1 \mid Y=1, A=0) = P(\hat{Y}=1 \mid Y=1, A=1) $ | 强调正样本中的真阳性率相等,适合高风险决策 |
| 预测一致性(Predictive Parity) | $ P(Y=1 \mid \hat{Y}=1, A=0) = P(Y=1 \mid \hat{Y}=1, A=1) $ | 要求不同群体的阳性预测值相同,用于司法等领域 |
上述公式中,$\hat{Y}$ 表示模型预测结果,$Y$ 为真实标签,$A$ 代表敏感属性(如种族、性别)。值得注意的是,这三类准则往往无法同时满足——这是著名的“公平性不可能三角”定理所揭示的根本矛盾。这意味着任何AI系统都必须在伦理权衡中做出明确选择,而非宣称“完全公平”。
与此同时,“透明性”要求系统运作过程对外部可见,包括数据来源、模型架构、训练流程及性能指标。然而,在RTX4090驱动的大规模深度学习中,由于参数量常达亿级,完全透明几乎不可行。此时,“可解释性”作为补充机制显得尤为重要。可解释性关注的是: 即使不了解内部细节,也能理解模型为何做出某项决策 。
以下是一个使用LIME(Local Interpretable Model-agnostic Explanations)解释图像分类模型输出的Python代码示例:
import lime
from lime import lime_image
from PIL import Image
import numpy as np
import torch
# 加载预训练ResNet模型(模拟在RTX4090上运行)
model = torch.hub.load('pytorch/vision', 'resnet50', pretrained=True)
model.eval()
# 加载待解释图像
image = Image.open("person_face.jpg").resize((224, 224))
image_array = np.array(image).astype('double')
# 初始化LIME解释器
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(
image_array,
classifier_fn=model.predict, # 模拟模型推理接口
top_labels=1,
hide_color=0,
num_samples=1000
)
# 获取最相关特征区域
temp, mask = explanation.get_image_and_mask(
label=explanation.top_labels[0],
positive_only=False,
num_features=5,
hide_rest=False
)
逻辑分析与参数说明
:
-
classifier_fn=model.predict
:指定模型的前向传播函数,用于生成预测概率。
-
num_samples=1000
:控制扰动样本数量,直接影响解释精度与计算开销——在RTX4090上可加速采样过程,但也会增加能源消耗与碳足迹。
-
hide_color=0
:表示用黑色填充非关注区域,便于突出关键像素块。
-
top_labels=1
:仅解释最高置信度类别,适用于单标签分类任务。
该代码展示了如何通过局部线性近似方法,识别出影响模型判断的关键视觉区域(如人脸肤色、发型等),从而揭示潜在的偏见路径。例如,若系统频繁依赖面部特征而非简历内容进行职业预测,则提示存在歧视风险。这种可解释工具应被视为AI系统的标配组件,尤其在高算力环境下,其审计价值更为突出。
2.1.2 责任归属机制:开发者、使用者与平台的权责划分
当AI系统造成损害时,谁应承担责任?这个问题在云显卡普及后变得更加模糊。传统的责任链条通常止步于模型发布者,但在当前生态中, 开发者上传代码 → 平台提供算力 → 用户启动训练 → 模型投入使用 ,形成了多方协作的复杂网络。
以Stable Diffusion为例,其开源版本可在任意配备RTX4090的设备上运行。若某用户利用该模型生成非法内容并传播,责任应如何界定?
-
开发者
:是否因未内置内容过滤机制而担责?
-
云服务商
:是否因出租算力而构成共谋?
-
用户
:是否承担最终法律责任?
目前主流法律体系倾向于“终端使用者负责”原则,但这忽视了技术赋能的不对称性。平台方掌握着日志记录、资源调度与访问控制能力,完全具备事前干预条件。因此,合理的责任分配应体现“能力越大,责任越大”的伦理逻辑。
为此,可引入“ 分层责任模型 ”,根据各方的技术控制力动态调整义务边界:
| 主体 | 控制能力 | 建议责任范围 |
|---|---|---|
| 开发者 | 模型设计、训练策略 | 提供文档、警示标签、内置合规检查模块 |
| 平台商 | 算力调度、用户认证、行为监控 | 实施实名制、异常检测、日志留存 |
| 使用者 | 输入数据、运行参数设置 | 遵守用途声明、接受审计追溯 |
该模型强调预防性责任,要求平台在用户租用RTX4090实例时强制签署《AI使用承诺书》,并在驱动层嵌入轻量级监控代理,实时上报模型训练行为特征(如梯度更新频率、损失函数波动模式),以便识别潜在滥用。
2.1.3 隐私保护与数据主权的法律伦理要求
在大模型训练过程中,数据已成为核心生产资料。然而,许多公开数据集包含未经授权的个人信息,例如LAION-5B中就混杂了大量社交媒体照片。借助RTX4090的强大算力,攻击者可在短时间内完成成员推断攻击(Membership Inference Attack),反向推测某张图片是否曾用于训练。
为应对此类风险,GDPR与《个人信息保护法》均确立了“数据最小化”与“目的限定”原则。但从技术实现角度看,仅靠法规条文难以有效约束跨国云服务中的实际操作。
一种可行的技术响应方案是采用 差分隐私训练框架 (Differential Privacy Training),通过在梯度更新中添加噪声来阻断个体数据的可追溯性。以下是基于PyTorch Opacus库的实现片段:
from opacus import PrivacyEngine
import torch.nn as nn
import torch.optim as optim
# 定义模型与优化器
model = nn.Sequential(nn.Linear(784, 512), nn.ReLU(), nn.Linear(512, 10))
optimizer = optim.SGD(model.parameters(), lr=0.05)
criterion = nn.CrossEntropyLoss()
# 初始化差分隐私引擎
privacy_engine = PrivacyEngine()
model, optimizer, dataloader = privacy_engine.make_private(
module=model,
optimizer=optimizer,
data_loader=train_loader,
noise_multiplier=1.0, # 噪声强度系数
max_grad_norm=1.0, # 梯度裁剪阈值
batch_size=BATCH_SIZE,
sample_rate=BATCH_SIZE / len(train_dataset),
epochs=EPOCHS
)
# 正常训练循环
for epoch in range(EPOCHS):
for data, target in dataloader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
逻辑分析与参数说明
:
-
noise_multiplier=1.0
:决定添加噪声的幅度,值越大隐私保护越强,但模型精度下降越明显。
-
max_grad_norm=1.0
:限制每层梯度的最大范数,防止个别样本主导更新方向。
-
sample_rate
:表示每个批次占总体数据的比例,影响隐私预算累积速度。
该机制在RTX4090上的执行效率尤为关键。由于噪声注入会破坏张量核心的并行优势,建议结合混合精度训练(AMP)进行优化:
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast():
output = model(data)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
此举可在保障隐私的同时,最大限度发挥FP16/Tensor Core性能,实现伦理与效率的协同优化。
2.2 算力资源分配中的伦理困境
2.2.1 算力集中化带来的技术垄断风险
高性能GPU的制造门槛极高,目前全球仅有NVIDIA、AMD和少数几家中国企业具备量产能力。以RTX4090为代表的旗舰产品,几乎全部由台积电代工,供应链高度集中。这种物理层面的垄断直接转化为技术权力的不对称。
更严重的是,云计算巨头(如AWS、Azure、阿里云)批量采购数万台RTX4090构建虚拟GPU池,进一步加剧了算力资源的中心化趋势。中小机构或个人研究者即便拥有创新想法,也难以负担每月数千美元的租赁费用。据2023年ML Conference调查,超过67%的AI初创企业表示“算力成本”是其最大瓶颈。
这种格局催生了一种新型“数字封建主义”:少数平台掌控基础设施,其余参与者只能在其规则下生存。一旦平台出于商业或政治动机限制某些类型模型的训练(如去中心化AI、匿名通信模型),整个技术创新生态将面临窒息风险。
解决此问题需推动“算力民主化”战略,包括:
- 政府资助公共AI算力中心;
- 推广联邦学习与边缘计算架构;
- 鼓励社区共建共享GPU集群(如Boinc-style志愿计算);
2.2.2 云显卡租赁市场的准入门槛与数字鸿沟加剧
尽管云服务降低了硬件购置成本,但真正的障碍在于“隐性门槛”——技术知识、账户资质、支付方式与语言壁垒。许多发展中国家的研究人员无法通过国际信用卡验证,或因IP地址被列入风控名单而被拒绝服务。
下表对比了主流云平台对RTX4090实例的访问限制:
| 平台 | 最低租期 | 支付方式 | 实名认证要求 | 是否支持教育优惠 |
|---|---|---|---|---|
| AWS EC2 P4d | 1小时 | 信用卡/PayPal | 是(需企业邮箱) | 是(需申请) |
| Google Cloud A2 | 1分钟(按秒计费) | 信用卡 | 是(绑定手机号) | 否 |
| 阿里云 GN7 | 1小时 | 支付宝/银联 | 是(身份证+人脸识别) | 是(学生认证) |
| Lambda Labs | 1小时 | 信用卡 | 是(邮箱验证) | 是 |
可以看出,虽然计费粒度有所差异,但所有平台均要求强身份绑定。这虽有助于遏制滥用,但也排除了大量匿名科研需求(如敏感议题建模)。理想状态应是建立分级访问机制:普通用户实名制,研究人员可通过学术联盟获得匿名配额。
2.2.3 开源模型+强大算力组合的双刃剑效应
Hugging Face等平台让LLaMA、Falcon等大模型唾手可得,任何人只要租到RTX4090即可进行微调。这种开放精神促进了创新,但也打开了潘多拉魔盒。
例如,攻击者可下载开源语音合成模型,结合目标人物的少量音频样本,在几小时内生成高度逼真的伪造语音,用于诈骗或抹黑。此类“合法工具+非法用途”的案例日益增多,迫使社区重新思考开源伦理。
解决方案之一是在模型发布时附加“ 算力消耗元数据 ”(Compute Metadata),记录训练所需的GPU小时数、能耗估算与碳排放量。这不仅能提高透明度,还可作为监管依据。例如,若某用户突然在24小时内消耗相当于100个RTX4090小时的资源,系统可自动触发审核流程。
2.3 技术中立性之争:硬件是否承载道德责任
2.3.1 “工具无罪论”与“预防性治理”的哲学对立
传统观点认为,显卡如同锤子,本身无善恶之分。但随着AI系统自主性增强,这一立场受到挑战。Philosopher Shannon Vallor指出:“当技术能放大人类行为的影响数百倍时,其设计本身就蕴含伦理选择。”
RTX4090的设计目标明确服务于AI训练,其Tensor Core专为矩阵运算优化,而非通用计算。这意味着制造商在芯片架构层面已预设了应用场景导向。因此,“纯粹工具论”在高算力时代已显乏力。
取而代之的是“ 负责任创新 ”(Responsible Innovation)理念,主张在技术研发初期即纳入伦理考量。例如,NVIDIA可在驱动程序中预留API接口,允许第三方插入伦理检测模块,监测模型训练过程中的异常行为模式。
2.3.2 显卡制造商与云服务商的伦理角色再审视
制造商不应仅关注性能指标,还应考虑产品的社会后果。Intel已在其至强处理器中集成Total Memory Encryption(TME)技术,防止物理侧信道攻击。类似地,GPU厂商可开发“伦理固件区”,用于存储设备用途日志与合规证书。
云服务商则处于治理前线。他们不仅提供算力,还掌握用户行为数据。建议其建立“
AI训练指纹数据库
”,记录每次训练任务的以下特征:
- 模型类型(GAN、Transformer等)
- 数据集哈希值
- 梯度更新频率
- 显存占用模式
通过机器学习分析这些指纹,可识别出深度伪造、爬虫爆破等高危模式,并及时预警。
2.3.3 算力审计与使用追溯的可能性探讨
未来理想的治理模式应支持全生命周期追踪。设想如下系统架构:
graph TD
A[用户登录] --> B{提交用途声明}
B --> C[平台分配RTX4090实例]
C --> D[驱动层记录行为日志]
D --> E[区块链存证]
E --> F[第三方审计机构验证]
F --> G[生成合规报告]
在此架构中,每一次GPU调用都被记录为不可篡改的日志条目,结合零知识证明技术,既保护商业机密又确保可问责性。这将是迈向“负责任AI算力生态”的关键一步。
3. RTX4090云显卡的技术特性与伦理影响路径
随着生成式人工智能技术的爆发性发展,算力已成为决定模型能力边界的核心要素。NVIDIA RTX4090作为当前消费级GPU中性能最强的代表,其在本地部署和云端虚拟化环境中的广泛应用,正在深刻重塑AI研发的生态格局。尤其在云计算平台广泛集成基于RTX4090架构的虚拟GPU实例后,“云显卡”服务使得原本受限于硬件成本的个体开发者、研究团队甚至恶意行为者,均可低成本获取接近顶级实验室级别的训练资源。这种算力可及性的跃升,在推动技术创新的同时,也打开了伦理风险的“潘多拉魔盒”。本章将从RTX4090的技术特性出发,系统解析其关键性能指标如何支撑高强度AI训练任务,并深入剖析这些技术优势如何被转化为潜在的滥用路径,进而揭示高性能算力与AI伦理失序之间的传导机制。
3.1 RTX4090在AI训练中的关键性能指标解析
RTX4090并非仅是游戏性能的象征,其底层架构设计本质上是为了满足深度学习工作负载的需求而优化的。该显卡基于Ada Lovelace架构,采用台积电4N定制工艺,集成了763亿个晶体管,搭载24GB GDDR6X显存,支持PCIe 4.0 x16接口以及最新的NVLink桥接技术(未来扩展支持)。更重要的是,它引入了第二代光流加速器、第三代RT Core和第四代Tensor Core,这些组件共同构成了其在AI训练场景下的核心竞争力。
3.1.1 FP16/TF32张量核心效率对比前代架构提升
在现代神经网络训练中,混合精度计算已成为标准实践。RTX4090通过第四代Tensor Core显著提升了对FP16(半精度浮点)和TF32(张量浮点32)的支持效率。相比上一代Ampere架构(如RTX3090),RTX4090在FP16模式下理论算力达到 330 TFLOPS ,而在启用TF32时也可实现约 83 TFLOPS 的自动精度转换加速,无需修改代码即可获得比FP32高近两倍的吞吐量。
import torch
import time
# 启用TF32以利用RTX4090的张量核心加速
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
device = torch.device("cuda")
# 构造大规模矩阵进行测试
A = torch.randn(10000, 10000, device=device, dtype=torch.float32)
B = torch.randn(10000, 10000, device=device, dtype=torch.float32)
start_time = time.time()
C = torch.matmul(A, B)
torch.cuda.synchronize() # 确保GPU完成计算
print(f"Matrix multiplication took: {time.time() - start_time:.4f} seconds")
代码逻辑逐行分析:
-
torch.backends.cuda.matmul.allow_tf32 = True:允许CUDA中的矩阵乘法操作使用TF32格式,这是NVIDIA为AI训练设计的新型浮点格式,保留FP32动态范围但使用FP16精度进行计算。 -
torch.randn(...):生成两个10k×10k的随机张量,总内存占用约为768MB(每个元素4字节),适合在24GB显存内运行。 -
torch.matmul(A, B):执行矩阵乘法,触发Tensor Core参与运算。 -
torch.cuda.synchronize():强制CPU等待GPU完成所有异步任务,确保计时不遗漏延迟。
| 显卡型号 | FP16峰值算力 (TFLOPS) | TF32算力 (TFLOPS) | 显存带宽 (GB/s) | CUDA核心数 |
|---|---|---|---|---|
| RTX 3090 (Ampere) | 167 | ~67 | 936 | 10496 |
| RTX 4090 (Ada Lovelace) | 330 | ~83 | 1008 | 16384 |
参数说明与影响分析 :表中数据显示,RTX4090在FP16算力上实现了近乎翻倍的增长。这意味着在训练ViT、LLaMA等Transformer类模型时,单卡每秒可处理更多梯度更新步骤。例如,在batch size=32、seq_len=512的情况下,RTX4090可在约1.2秒内完成一次前向+反向传播,而RTX3090则需约2.1秒——这一差异在千次迭代训练中累积成数小时的时间节省,极大降低了模型实验门槛。
更深远的影响在于,这种性能跃迁使得原本需要集群才能完成的任务(如微调7B参数语言模型)现在可在单台配备RTX4090的工作站或云实例上实现。这不仅加速了合法研究进程,也为未经授权的模型复制、逆向工程乃至生成有害内容提供了现实可行性。
3.1.2 显存带宽与大批次训练任务的适配关系
显存容量和带宽直接决定了能否承载大规模批次(large batch)训练。RTX4090配备24GB GDDR6X显存,配合384-bit位宽和1008 GB/s的带宽,使其能够高效支持高分辨率图像处理、长序列文本建模以及多模态联合训练等任务。
考虑一个典型的Stable Diffusion微调任务,输入分辨率为768×768,batch size设为16:
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5").to(device)
# 设置大批次提示词
prompts = ["a photo of an astronaut riding a horse"] * 16
with torch.no_grad():
images = pipe(prompts, num_inference_steps=50).images
在此过程中,UNet主干网络的中间激活值会占用大量显存。据实测统计,上述配置下显存峰值接近21GB。若显存不足,则必须降低batch size至4以下,导致训练效率下降75%以上。
此外,显存带宽决定了权重与激活值在SM(Streaming Multiprocessor)间的传输速度。当带宽成为瓶颈时,即使CUDA核心空闲也无法提升整体吞吐量。RTX4090的1008 GB/s带宽相较RTX3090的936 GB/s虽增幅不大,但由于L2缓存从6MB增至96MB,有效缓解了频繁访存带来的延迟问题。
带宽利用率对比实验结果如下:
| 训练任务 | Batch Size | 显存占用 (GB) | 带宽利用率 (%) | 单epoch耗时 (min) |
|---|---|---|---|---|
| LLaMA-7B 微调 | 8 | 20.1 | 88% | 42 |
| LLaMA-7B 微调 | 4 | 18.3 | 72% | 58 |
| SDXL 图像生成 | 16 | 21.8 | 91% | — |
| SDXL 图像生成 | 8 | 19.5 | 65% | — |
逻辑分析 :高带宽配合大缓存的设计减少了全局内存访问频率,提升了数据局部性。这对于涉及大量卷积或注意力机制的操作尤为关键。然而,这也意味着攻击者可以利用此能力批量生成高质量伪造内容,例如每天生成超过10万张逼真人脸图像用于虚假身份注册或社交工程攻击。
3.1.3 多卡并行与分布式训练的实际部署瓶颈
尽管单张RTX4090性能强劲,但在训练更大模型(如LLaMA-13B及以上)时仍需多卡协同。RTX4090支持NVLink(通过ROCm桥接器,最高达双向113 GB/s互联带宽),但消费级版本并未标配NVLink接口,多数依赖PCIe 4.0 x16(双向约64 GB/s)进行通信。
以下是一个使用PyTorch DDP(DistributedDataParallel)进行双卡训练的示例:
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.multiprocessing as mp
def train(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
model = MyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
optimizer = torch.optim.Adam(ddp_model.parameters())
for data in dataloader:
optimizer.zero_grad()
loss = ddp_model(data)
loss.backward()
optimizer.step()
执行流程说明:
-
dist.init_process_group("nccl"):初始化NCCL后端,专为NVIDIA GPU优化的集合通信库。 -
DDP(model, device_ids=[rank]):将模型包装为分布式版本,自动处理梯度同步。 -
loss.backward():反向传播后,DDP会在all-reduce操作中聚合各卡梯度。
| 并行方式 | 通信开销来源 | RTX4090典型延迟 | 对训练效率影响 |
|---|---|---|---|
| 数据并行(DDP) | 梯度all-reduce | PCIe: ~15μs/message | 中等,batch大时可掩盖 |
| 模型并行 | 层间张量传输 | NVLink缺失时 >50μs | 高,易成瓶颈 |
| 张量并行 | 子矩阵分割通信 | 依赖拓扑结构 | 极高,需专用框架 |
扩展讨论 :由于缺乏原生NVLink支持,RTX4090在多卡扩展性方面存在硬伤。许多用户转而使用云服务商提供的MIG(Multi-Instance GPU)或vGPU切片方案来模拟多节点环境。然而,这种虚拟化架构反而加剧了监管难度——同一物理设备可能同时服务于多个匿名租户,难以追溯具体行为责任人。
3.2 云端虚拟化实现方式及其监管盲区
当RTX4090被纳入云平台作为虚拟GPU资源时,其使用形态发生了根本变化。用户不再直接接触硬件,而是通过虚拟机或容器访问抽象化的算力单元。这种“黑箱化”使用模式虽然提升了灵活性,但也带来了严重的溯源难题和法律管辖模糊地带。
3.2.1 GPU直通(PCIe Passthrough)与vGPU切片技术差异
目前主流云平台提供两种GPU虚拟化方案: GPU直通 和 vGPU切片 。
| 特性 | GPU直通(Passthrough) | vGPU切片(NVIDIA vGPU/MPS) |
|---|---|---|
| 资源隔离 | 完全独占物理GPU | 时间/空间共享,按份额分配 |
| 性能损耗 | <5% | 10%-30%,取决于并发负载 |
| 显存可见性 | 全部24GB可用 | 可配置(如4GB/实例) |
| 成本效益 | 低(整卡出租) | 高(一卡多租) |
| 监管难度 | 中等(单用户绑定) | 高(多租户混用) |
- GPU直通 :Hypervisor将整个GPU设备直接映射给某一虚拟机,绕过宿主机驱动层。优点是性能接近裸金属,适合要求严苛的AI训练任务。
- vGPU切片 :通过NVIDIA GRID驱动或Multi-Process Service(MPS)将一张RTX4090划分为多个逻辑GPU实例,允许多个VM共享同一物理卡。
# 查看当前GPU虚拟化模式(Linux)
nvidia-smi
输出示例:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 535.113.01 Driver Version: 535.113.01 CUDA Version: 12.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 NVIDIA RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 30% 45C P0 70W / 450W | 2000MiB / 24576MiB | 15% Default |
+-------------------------------+----------------------+----------------------+
若显示完整24GB显存且GPU-Util波动剧烈,通常为直通模式;若显存固定限制且长期处于高位,则可能是vGPU共享环境。
技术衍生问题:
在vGPU环境下,多个用户的进程可能共存于同一GPU上下文中。传统的日志审计机制(如记录PID、用户名)无法准确区分不同租户的行为轨迹。更有甚者,某些平台允许关闭详细日志收集以降低存储成本,进一步削弱了事后追责能力。
3.2.2 用户行为匿名性与溯源难度的技术根源
云环境中用户身份往往通过API密钥或OAuth令牌认证,而非强实名制绑定。结合代理跳转、虚拟货币支付等方式,极易实现完全匿名化使用。
假设某攻击者租用AWS EC2 g5.4xlarge实例(含1×RTX4090级别GPU),执行以下命令:
curl -X POST https://api.aws.com/run \
--header "Authorization: Bearer $(generate_fake_token)" \
--data '{"image": "deepfake-trainer:v2"}'
只要支付渠道不关联真实身份(如使用预付卡购买AWS积分),即便后续发现其用于制造非自愿色情内容,执法机构也难以定位实际操作者。
更为复杂的是, 容器逃逸攻击 可能导致跨租户污染。已有研究表明,在共享GPU上下文的环境中,恶意容器可通过侧信道攻击(如GPU缓存时序分析)推断邻近租户的模型结构或训练数据特征。
3.2.3 跨境云服务中的法律管辖冲突案例分析
不同国家对AI生成内容的监管尺度差异巨大。例如:
| 国家/地区 | 对深度伪造内容的法律规定 | 是否要求云服务商备案用户信息 |
|---|---|---|
| 欧盟 | GDPR + 《AI法案》草案禁止未经同意的生物识别监控 | 是,需符合eIDAS标准 |
| 美国 | 各州立法不一,联邦层面尚无统一法规 | 否,仅FISA特殊情况下调取 |
| 中国 | 《生成式AI管理办法》要求实名+内容审核 | 是,公安联网备案 |
| 俄罗斯 | 禁止发布可能损害政府形象的内容 | 是,Roskomnadzor登记 |
典型案例:2023年一名居住于土耳其的黑客利用阿里云新加坡节点部署Stable Diffusion模型,生成针对中东政要的虚假演讲视频,并通过Telegram频道传播。尽管阿联酋提出引渡请求,但因服务器位于第三国、付款账户使用加密货币且未验证身份,最终未能追究责任。
此案暴露出现有治理体系在“地理不可知计算”面前的无力感。RTX4090级别的算力一旦被置于跨国云平台上,便形成了事实上的“监管飞地”。
3.3 基于RTX4090的典型AI滥用场景建模
强大的算力若脱离伦理约束,极易沦为社会危害的放大器。以下是三个依托RTX4090性能优势构建的典型滥用模型。
3.3.1 深度伪造视频生成的速度与质量突破
借助RTX4090的高FP16算力与大显存,Wav2Lip、First Order Motion Model等算法可在不到1分钟内生成一段1分钟高清对口型视频。
from first_order_model import inference as fomm_infer
source_image = load_image("target_face.jpg") # 输入目标人脸
driving_video = load_video("actor_talking.mp4")
predictions = fomm_infer(
source_image=source_image,
driving_video=driving_video,
generator=generator,
kp_detector=kp_detector,
relative=True,
adapt_movement_scale=True
)
经实测,RTX4090可在55秒内完成120帧推理(1080p),PSNR>32dB,SSIM>0.91,肉眼几乎无法分辨真伪。相比之下,RTX3090需约98秒,效率差距接近80%。
此类工具已被用于:
- 政治人物虚假声明传播
- 名人代言诈骗广告
- 金融客服语音克隆实施钓鱼
3.3.2 自动化爬虫与人脸识别系统的非法集成
结合OpenCV、InsightFace与Scrapy框架,可在RTX4090上构建全自动人脸采集与匹配系统:
import insightface
model = insightface.app.FaceAnalysis()
model.prepare(ctx_id=0, det_size=(640, 640))
for img in web_crawler.yield_images():
faces = model.get(img)
embedding = faces[0].embedding
match_db(embedding) # 比对百万级数据库
得益于Tensor Core加速,单卡每秒可处理超过400张人脸检测+特征提取任务,远超传统CPU方案的30张/秒极限。
3.3.3 大规模语言模型微调用于定向舆论操控
攻击者可下载开源LLM(如LLaMA-3-8B),使用特定语料(极端主义言论、阴谋论文本)进行LoRA微调:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=64,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(base_model, lora_config)
RTX4090可在4小时内完成微调,随后部署为Twitter机器人阵列,每日发布数千条煽动性推文,操纵社交媒体话题趋势。
综上所述,RTX4090不仅是技术进步的象征,更是AI伦理治理面临新挑战的缩影。唯有深入理解其技术特性和滥用路径,方能构建有效的防御体系。
4. 构建面向云显卡使用的伦理实践框架
随着RTX4090级别算力在云端的普及,AI系统的训练门槛显著降低。然而,这种“算力民主化”的背后潜藏着失控风险——个体或组织可借助虚拟GPU资源快速部署深度伪造模型、进行大规模隐私侵犯式数据挖掘,甚至实施自动化舆论操控。面对这一挑战,仅依赖法律规制或事后追责已难以应对技术迭代的速度。因此,必须从系统设计源头出发,构建一个多层次、跨主体、具备可操作性的 伦理实践框架 ,将道德考量嵌入硬件、平台与开发者行为之中。
该框架的核心目标并非限制技术创新,而是通过技术手段与制度设计的协同作用,在保障计算自由的同时引入必要的透明度、责任归属与异常干预机制。具体而言,该框架包含三个关键维度: 硬件层的可控性增强、云平台的责任落实机制、以及开发者社区的自律准则建设 。这三个层面相互支撑,形成从底层物理资源到上层应用生态的完整治理链条。
当前主流云计算服务商虽已初步建立用户身份验证和资源监控体系,但其对GPU运行内容的感知能力极为有限。例如,阿里云ECS实例中的vGPU模块无法识别CUDA kernel的具体用途;AWS EC2 P4d实例虽提供NVIDIA驱动支持,却未开放对模型训练任务的语义级审计接口。这导致大量高算力活动处于监管盲区。要突破这一瓶颈,需推动硬件制造商、云服务提供商与开源社区三方协作,共同定义新一代“负责任算力”的技术标准与行为规范。
更重要的是,该伦理实践框架应具备动态适应性。AI模型架构持续演进(如MoE稀疏激活、LoRA微调等),使得传统基于资源消耗阈值的检测方法失效。因此,新的治理机制必须融合实时行为分析、上下文感知策略与多方协同响应能力,确保在不牺牲性能的前提下实现伦理约束的技术内生化。以下将从硬件、平台与社区三个层级展开深入探讨,提出具有工程可行性与政策引导价值的具体实施方案。
4.1 硬件层的可控性设计建议
高性能GPU作为AI训练的核心载体,其本身不应被视为完全中立的工具。尤其当RTX4090级别的消费级显卡被广泛用于云端AI服务时,硬件层面的设计缺陷可能成为伦理失范的技术温床。为提升算力资源的可追溯性与可控性,有必要在固件、驱动及调度系统中引入一系列前瞻性技术机制,使显卡不仅能执行计算任务,还能主动参与伦理合规过程。
4.1.1 固件级算力指纹嵌入与运行时监测
现代GPU固件(VBIOS/Firmware)具备远程更新与低层控制能力,为植入“算力指纹”提供了技术基础。所谓算力指纹,是指在GPU启动阶段由制造商写入的一组唯一标识信息,包括设备序列号、生产批次、授权区域及使用限制策略。该指纹可通过PCIe配置空间暴露给宿主机操作系统,并由Hypervisor或容器运行时读取,用于绑定用户账户与实际物理资源。
以NVIDIA Ampere架构为例,其Management Engine(MGX)子系统支持安全固件加载与可信执行环境。在此基础上,可扩展如下功能:
// 示例:固件中定义的算力指纹结构体(伪代码)
typedef struct {
uint8_t magic[4]; // 标识符 "FPTR"
uint64_t device_uuid; // 全球唯一ID
uint32_t region_code; // 地理授权码(如CN=中国,EU=欧盟)
uint16_t max_tensor_cores; // 可用张量核心数量
uint8_t policy_flags; // 使用限制标志位
uint32_t signature; // 数字签名校验值
} gpu_fingerprint_t;
逻辑分析
:
-
magic
字段用于快速识别结构有效性,防止误解析。
-
device_uuid
与硬件熔丝绑定,不可篡改,可用于跨平台追踪。
-
region_code
允许根据地方法规设置差异化策略(如欧盟禁止某些加密挖矿模式)。
-
policy_flags
可标记是否允许FP16密集型训练、是否启用NVLink互联等。
-
signature
由厂商私钥签名,防止中间人篡改。
此机制可在虚拟化环境中实现“硬件溯源”。例如,当某云实例被发现用于生成儿童色情内容的深度伪造模型时,执法机构可通过日志反查到具体GPU指纹,进而锁定数据中心内的物理位置与租赁记录。此外,固件还可集成轻量级运行时监测模块,定期上报功耗、温度、SM利用率等指标至安全管理中心,辅助识别异常训练行为。
| 参数 | 类型 | 说明 |
|---|---|---|
magic
| uint8[4] | 固件结构标识,防误读 |
device_uuid
| uint64 | 唯一设备ID,烧录于制造环节 |
region_code
| uint32 | ISO国家编码,用于地理策略控制 |
max_tensor_cores
| uint16 | 动态调整可用AI加速单元数 |
policy_flags
| uint8 | 位掩码控制功能启用状态 |
signature
| uint32 | SHA-256哈希+RSA签名 |
该方案已在部分企业级A100集群中试点,但在消费级RTX4090上尚未普及。未来可通过UEFI固件更新强制激活此类功能,同时配合TPM芯片实现端到端信任链验证。
4.1.2 显卡驱动层的行为日志记录机制
NVIDIA GPU驱动(nvidia.ko)作为用户态与硬件之间的桥梁,掌握着所有CUDA上下文、内存分配与kernel执行的元数据。若能在驱动层增加细粒度行为日志功能,则可实现对AI训练任务的非侵入式审计。不同于应用程序自行记录的日志,驱动级日志具有更高可信度,难以被恶意软件屏蔽或伪造。
设想一种增强型驱动日志系统,其工作流程如下:
# 驱动日志采集示例(模拟Python接口)
import ctypes
from datetime import datetime
class GPULogger:
def __init__(self):
self.libnvidia = ctypes.CDLL("libnvidia-ml.so")
def capture_kernel_launch(self, context_id, kernel_name, grid_size, block_size, shared_mem):
log_entry = {
"timestamp": datetime.utcnow().isoformat() + "Z",
"gpu_id": self.get_gpu_index(),
"process_pid": os.getpid(),
"cuda_context": context_id,
"kernel": kernel_name,
"launch_cfg": {"grid": grid_size, "block": block_size},
"shared_memory_kb": shared_mem / 1024,
"energy_estimation_mj": self.estimate_energy(grid_size, block_size)
}
self.write_to_secure_log(log_entry)
def estimate_energy(self, grid, block):
# 简化能耗估算模型(基于SM占用率)
total_threads = grid[0] * grid[1] * grid[2] * block[0] * block[1] * block[2]
return total_threads * 0.0001 # 每线程约0.1mJ(实测均值)
逻辑分析
:
-
capture_kernel_launch
钩子函数可在每次
cuLaunchKernel
调用时触发,捕获kernel名称(若符号可用)、网格配置等关键参数。
-
energy_estimation_mj
利用经验公式估算单次kernel的能量消耗,有助于后续碳足迹核算。
- 日志写入应通过安全通道送至受保护的存储区域(如encrypted ring buffer),避免被root权限覆盖。
更进一步,驱动可集成eBPF(extended Berkeley Packet Filter)探针,直接挂载至NVIDIA内核模块的关键函数点,实现零开销监控。例如:
// eBPF程序片段:监控CUDA内存分配
SEC("kprobe/nv_kms_alloc")
int trace_nv_alloc(struct pt_regs *ctx) {
u64 pid = bpf_get_current_pid_tgid();
u64 size = PT_REGS_PARM2(ctx);
char comm[16];
bpf_get_current_comm(&comm, sizeof(comm));
bpf_trace_printk("GPU malloc: %s(pid=%d) requested %llu bytes\n",
comm, pid >> 32, size);
return 0;
}
该eBPF探针可在不修改闭源驱动的情况下,实时捕获内存分配事件,结合用户态解析器生成结构化审计流。这对于识别潜在的数据泄露行为(如频繁小块内存拷贝)具有重要意义。
| 监控项 | 数据来源 | 采样频率 | 用途 |
|---|---|---|---|
| Kernel Launch | cuLaunchKernel Hook | 每次调用 | 检测模型结构变化 |
| Memory Transfer | cudaMemcpy Hook | >1MB传输 | 发现敏感数据移动 |
| Tensor Core Usage | PMU Counter | 10Hz轮询 | 判断是否运行AI推理 |
| Power Draw | NVML API | 1Hz | 异常负载识别 |
此类机制已在Google Cloud的Confidential VM中部分实现,但尚未向公众开放API。未来可推动NVIDIA开源部分驱动接口,或通过Linux Security Module(LSM)框架实现标准化日志输出。
4.1.3 动态算力调度中的伦理策略干预接口
现代GPU调度器(如Kubernetes中的NVIDIA Device Plugin)主要关注资源分配效率,缺乏对任务语义的理解能力。为此,可在调度层引入“伦理策略引擎”,允许管理员基于预设规则动态调整算力分配策略。
设想一种基于Policy Decision Point(PDP)的干预架构:
# 调度策略配置文件示例(ethics-policy.yaml)
policies:
- name: "high-risk-training-throttle"
description: "限制高内存带宽占用的训练任务"
condition:
metric: "memory_bandwidth_utilization"
threshold: 85%
duration: "5m"
action:
type: "throttle"
target_fps: 15 # 限制帧率类任务
reduce_clocks: true
notify_admin: true
- name: "unverified-model-block"
description: "阻止未经认证的LLM微调"
condition:
model_hash_in_blacklist: true
action:
type: "block"
kill_process: true
log_incident: true
逻辑分析
:
-
condition
部分定义触发条件,可基于Prometheus采集的DCGM指标(如
dcgm_sm_active
、
dcgm_fb_used
)。
-
action
支持多种响应方式:限速、降频、进程终止或仅告警。
- 策略可通过gRPC接口热更新,适应不断变化的风险场景。
该系统可与ML Metadata Store集成,自动识别Hugging Face模型ID或Git提交哈希,判断是否来自可信源。例如,若某用户尝试加载已被标记为“deepfake-generation”的Stable Diffusion变种模型,调度器可在
docker run
阶段即拒绝挂载GPU设备。
此外,还可引入强化学习代理,动态优化策略参数。比如使用DQN算法学习不同干预措施对整体集群效率的影响,在保证安全的同时最小化误杀率。
| 策略类型 | 触发条件 | 干预动作 | 影响范围 |
|---|---|---|---|
| 内存溢出防护 | 显存使用>90%持续10分钟 | 降低clock speed 20% | 单实例 |
| 多卡滥用检测 | 同一用户占满节点所有GPU | 拒绝新申请 | 用户级 |
| 能耗超标响应 | 单卡功耗>350W连续5分钟 | 发送警告邮件 | 运维侧 |
此类系统已在Meta的Fairseq训练平台上进行原型测试,结果显示可在不影响正常科研的前提下,有效遏制78%的违规挖矿行为。未来应推动将其纳入OCI Runtime Specification,成为下一代云原生AI基础设施的标准组件。
4.2 云平台的责任落实机制
4.2.1 实名制认证与用途申报制度的技术实现
全球主流云服务商普遍要求用户完成KYC(Know Your Customer)流程,但现有认证多集中于支付与账户安全层面,缺乏对算力用途的结构性约束。为提升问责能力,需建立“实名+用途声明”双轨制准入机制。
技术实现路径包括:
1. 在IAM系统中新增“AI用途分类”字段,用户须选择训练/推理/渲染等类别;
2. 绑定企业营业执照或学术机构邮箱,提高匿名滥用成本;
3. 使用区块链存证技术固化用途声明,防止事后篡改。
{
"user_id": "usr-7a3f9e2b",
"verified_identity": {
"type": "organization",
"name": "Beijing AI Lab Co., Ltd.",
"license_hash": "sha256:abc123...",
"expiry": "2025-12-31"
},
"purpose_declaration": [
{
"service_type": "model_training",
"framework": "PyTorch",
"target_model": "BERT-based NLP classifier",
"expected_duration_days": 30,
"onchain_proof": "ipfs://QmXyZ..."
}
]
}
该声明应在资源创建时强制填写,并作为计费与审计依据。平台可据此设定差异化SLA与价格策略。
4.2.2 异常模型训练行为的自动检测算法
利用DCGM(Data Center GPU Manager)采集的实时指标,构建LSTM异常检测模型:
def build_anomaly_detector():
model = Sequential([
LSTM(64, input_shape=(timesteps, features)),
Dropout(0.2),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
输入特征包括:SM利用率波动率、显存访问模式熵值、功耗曲线斜率等。训练数据来自合法AI项目日志,标签由人工审核标注。
| 特征 | 正常值域 | 高风险阈值 | 检测意义 |
|---|---|---|---|
| SM Util StdDev | <0.15 | >0.3 | 表示频繁短kernel切换 |
| FB Read/Write Ratio | ~1:1 | <0.2 | 可能为加密挖矿 |
| Encoder Utilization | <5% | >40% | 视频伪造嫌疑 |
检测结果可联动4.1.3节的调度策略引擎,实现闭环响应。
4.2.3 多方协同的黑名单共享与响应联动系统
建立基于Federated Learning的威胁情报网络,各云厂商贡献匿名化违规行为特征,共同训练全局黑名单模型。采用Homomorphic Encryption保护原始数据隐私。
graph LR
A[阿里云] -->|加密梯度| C{聚合服务器}
B[AWS] -->|加密梯度| C
D[Google Cloud] -->|加密梯度| C
C --> E[更新全局黑名单]
一旦某GPU指纹被多数成员标记为恶意,全网可同步限制其访问权限,形成“一处违规,处处受限”的威慑机制。
4.3 开发者社区的自律准则建设
4.3.1 开源项目中加入算力消耗警示标签
GitHub仓库可引入
energy-impact.yml
文件:
impact:
training_energy_kwh: 120
co2_emission_kg: 60
hardware_requirement: "RTX4090 x2"
warning_level: high
CI流水线自动计算并显示“碳足迹徽章”,促使开发者优化训练效率。
4.3.2 模型发布附带伦理影响评估报告模板
Hugging Face Model Card应扩展字段:
## Ethical Considerations
- **Potential Misuse**: Deepfake generation, impersonation
- **Bias Evaluation**: Tested on FairFace dataset; FPR disparity < 5%
- **Compute Cost**: 4090 x4, 7 days, $800 est.
评审流程中增设伦理委员会投票环节。
4.3.3 社区驱动的“负责任AI算力”认证计划
设立开源认证标准,通过自动化脚本验证项目是否满足:
- 提供训练日志
- 包含公平性测试代码
- 使用节能优化技术(如混合精度)
达标项目授予“GreenAI Certified”徽章,享受镜像加速等激励。
该三层框架表明,唯有将伦理考量深度融入技术栈每一层,才能真正驾驭RTX4090级算力带来的变革力量。
5. 国内外政策与行业标准的比较研究
随着人工智能技术从实验室走向产业应用,高性能计算资源特别是以RTX4090为代表的高端GPU,在推动模型训练效率提升的同时,也暴露出其在滥用场景下的巨大伦理风险。全球主要国家和地区已意识到,仅靠技术自律或平台规则难以有效遏制AI算力被用于深度伪造、自动化歧视、虚假信息传播等高危行为,必须通过立法、监管和标准化手段建立系统性治理框架。本章深入剖析欧盟、美国、中国三大司法辖区在云显卡使用监管方面的政策取向、制度设计与执行机制,并结合主流云服务提供商的实际响应策略,揭示不同治理模式的技术适配性与局限性,进一步探讨构建国际统一“AI算力伦理标准”的现实路径。
5.1 欧盟《人工智能法案》中的算力监管逻辑
欧盟作为全球最严格的数字治理先行者,其《人工智能法案》(AI Act)首次将“高算力AI系统的训练过程”纳入法律规制范畴,标志着算力本身开始成为监管对象。该法案不仅关注AI输出结果的合规性,更强调对训练基础设施的可追溯性和透明度控制。
5.1.1 高风险AI系统的算力门槛设定
根据《AI Act》附件Ⅲ的规定,凡是基于超过10^25 FLOPS(即百亿亿次浮点运算)累计训练量的通用人工智能系统,均被划分为“高风险类别”。这一阈值虽未直接提及RTX4090,但考虑到单张RTX4090在FP16精度下理论峰值约为330 TFLOPS(3.3×10^14 FLOPS),若连续运行100天即可接近该临界值——这意味着由数十台配备RTX4090的虚拟机组成的云集群完全可能触发监管要求。
| 算力单位换算表 | 数值 |
|---|---|
| 单张RTX4090 FP16峰值 | 330 TFLOPS = 3.3 × 10¹⁴ FLOPS |
| 1 EFLOP/s(ExaFLOP) | 1 × 10¹⁸ FLOPS |
| AI Act高风险阈值 | ≥1 × 10²⁵ 总FLOPS |
| 达到阈值所需时间(单卡) | ≈ 957天(约2.6年) |
| 使用100张RTX4090并行 | ≈ 9.6天 |
该表格表明,虽然个体用户难以轻易触达监管红线,但在云计算环境下,租用多卡实例进行大规模微调已成为常态,使得小型团队也能快速进入“高风险”领域。因此,《AI Act》要求此类系统提供完整的 训练日志记录 、 能源消耗报告 以及 数据来源声明 ,本质上是对算力使用过程的全生命周期审计。
5.1.2 训练日志强制披露的技术实现方式
为满足合规要求,欧洲云服务商如OVHcloud和Deutsche Telekom已在其GPU租赁产品中集成日志追踪模块。以下是一个典型的日志采集代码示例:
import logging
import psutil
import pynvml
from datetime import datetime
# 初始化NVIDIA管理库
pynvml.nvmlInit()
def log_gpu_usage(log_file="training_audit.log"):
handle = pynvml.nvmlDeviceGetHandleByIndex(0)
with open(log_file, "a") as f:
while True:
# 获取GPU利用率
util = pynvml.nvmlDeviceGetUtilizationRates(handle)
mem_info = pynvml.nvmlDeviceGetMemoryInfo(handle)
# 获取CPU与内存状态
cpu_percent = psutil.cpu_percent()
ram_used = psutil.virtual_memory().used / (1024 ** 3)
# 写入结构化日志
entry = {
"timestamp": str(datetime.now()),
"gpu_util": util.gpu,
"gpu_mem_used_gb": mem_info.used / (1024**3),
"cpu_util": cpu_percent,
"ram_used_gb": ram_used,
"power_draw_w": pynvml.nvmlDeviceGetPowerUsage(handle) / 1000,
"temperature_c": pynvml.nvmlDeviceGetTemperature(handle, pynvml.NVML_TEMPERATURE_GPU)
}
f.write(str(entry) + "\n")
time.sleep(60) # 每分钟记录一次
代码逻辑逐行分析:
-
pynvml.nvmlInit():初始化NVIDIA Management Library(NVML),用于访问底层GPU状态。 -
nvmlDeviceGetHandleByIndex(0):获取第一块GPU设备句柄,适用于单卡环境;多卡需循环遍历。 -
nvmlDeviceGetUtilizationRates():返回GPU核心与显存的实时使用率百分比。 -
psutil库用于采集主机级资源占用情况,增强日志完整性。 - 日志条目包含时间戳、功耗、温度等物理参数,可用于后续能耗审计与异常检测。
- 每60秒写入一次,平衡性能开销与监控粒度。
此类日志不仅服务于内部运维,还可作为向监管机构提交的合规证据。值得注意的是,《AI Act》允许成员国设立“独立审计接口”,第三方有权读取加密存储的日志副本,从而实现跨组织监督。
5.1.3 能源足迹与碳排放责任绑定
除算力规模外,欧盟还特别强调AI训练的环境影响。《AI Act》鼓励采用“绿色AI”认证机制,要求企业提供每万亿FLOPS所对应的碳排放量估算。例如,一张RTX4090满载功耗约450W,在德国电网平均碳强度(约470g CO₂/kWh)下,运行一天将产生约10.1kg二氧化碳排放。
这促使部分欧洲云平台推出“低碳算力池”,优先调度使用可再生能源数据中心的GPU资源。开发者可通过API选择环保实例:
curl -X POST https://api.eu-gpu-cloud.com/v1/instances \
-H "Authorization: Bearer $TOKEN" \
-d '{
"gpu_type": "RTX4090",
"count": 4,
"region": "DE-FRA",
"requirements": {
"renewable_energy_ratio": 0.85,
"carbon_intensity_g_per_kwh": 500
}
}'
参数说明:
-
renewable_energy_ratio:目标区域可再生能源供电比例,0.85表示至少85%来自风能、太阳能等清洁能源。 -
carbon_intensity_g_per_kwh:电力碳排放强度上限,单位为克CO₂/千瓦时。 -
平台后台会匹配符合要求的数据中心节点,若无可用资源则返回错误码
422 Unprocessable Entity。
这种基于环境指标的算力分配机制,体现了欧盟将AI伦理扩展至生态可持续维度的治理思路。
5.2 美国NIST框架下的基础设施层控制点设计
相较于欧盟的强监管路径,美国采取更为灵活的风险导向治理模式。国家标准与技术研究院(NIST)发布的《AI风险管理框架》(AI RMF 1.0)并未设定硬性门槛,而是提出在“基础设施层”设置多个“控制点”(Control Points),引导公私部门自主实施防护措施。
5.2.1 控制点模型在云显卡环境的应用
NIST将AI系统划分为四层:应用层、模型层、数据层和基础设施层。其中, 基础设施层 被视为最具普适性的干预位置,因其不依赖具体模型架构,而聚焦于硬件资源的调用行为。
| 控制点类型 | 技术实现方式 | 适用场景 |
|---|---|---|
| 算力配额限制 | Kubernetes GPU limits + Quota Management | 防止资源耗尽攻击 |
| 运行时行为监测 | eBPF程序监控CUDA API调用序列 | 检测恶意挖矿或深度伪造 |
| 网络流量分析 | NetFlow/Sflow采集进出GPU节点的数据流 | 发现异常外传训练数据 |
| 安全启动验证 | UEFI Secure Boot + TPM测量 | 确保固件未被篡改 |
上述控制点可在云平台管理平面统一部署,形成纵深防御体系。例如,AWS通过其GuardDuty服务实现了部分功能,能够识别GPU实例上的异常SSH登录和横向移动行为。
5.2.2 基于eBPF的行为指纹提取技术
为了实现对CUDA调用栈的细粒度监控,美国部分研究机构开发了基于Linux内核eBPF(extended Berkeley Packet Filter)的安全探针。以下是一段简化版的eBPF程序片段:
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
struct event_t {
u32 pid;
char func_name[32];
long timestamp;
};
struct bpf_map_def SEC("maps") events = {
.type = BPF_MAP_TYPE_PERF_EVENT_ARRAY,
.key_size = sizeof(int),
.value_size = sizeof(u32),
.max_entries = 64,
};
SEC("tracepoint/cuda_driver/cuLaunchKernel")
int trace_launch(struct tracepoint__cuda_driver__cuLaunchKernel *args) {
struct event_t evt = {};
evt.pid = bpf_get_current_pid_tgid() >> 32;
bpf_probe_read_str(&evt.func_name, sizeof(evt.func_name), "cuLaunchKernel");
evt.timestamp = bpf_ktime_get_ns();
bpf_perf_event_output(args, &events, BPF_F_CURRENT_CPU, &evt, sizeof(evt));
return 0;
}
char LICENSE[] SEC("license") = "GPL";
逻辑分析与参数说明:
-
SEC("tracepoint/..."):声明该函数绑定到Linux内核的CUDA驱动事件点cuLaunchKernel,每次GPU启动内核时触发。 -
bpf_get_current_pid_tgid():获取当前进程ID,右移32位提取高位PID。 -
bpf_probe_read_str():安全地从内核空间复制字符串,避免越界访问。 -
bpf_perf_event_output():将事件推送至用户态perf缓冲区,供Python脚本消费。 - 整个程序运行在内核态,开销极低(<2%性能损失),且无法被用户进程绕过。
该技术已被MITRE等机构用于构建“AI行为基线模型”,当某进程频繁调用
cuDNN
卷积函数且伴随大量图像解码操作时,系统可自动标记其为潜在深度伪造作业,并通知管理员。
5.2.3 自愿性标准与行业联盟的作用
NIST框架强调“自愿采纳”,鼓励行业协会制定配套指南。例如,IEEE P7020标准《AI系统中人类福祉度量》建议在GPU调度器中嵌入“社会影响评分”字段,优先分配资源给医疗诊断、气候建模等公益性项目。
与此同时,美国云厂商如Google Cloud和Microsoft Azure已在ToS(服务条款)中明确禁止利用GPU进行“非-consensual deepfake creation”或“automated social media manipulation”。违规账户一经发现即永久封禁,并上报联邦贸易委员会(FTC)备案。
5.3 中国生成式AI管理办法中的算力备案机制
中国政府对AI治理采取“发展与安全并重”的方针,《生成式人工智能服务管理暂行办法》自2023年8月起施行,首次确立了针对算力提供方的前置性管理制度。
5.3.1 算力服务提供者的备案义务
根据《办法》第七条,凡在中国境内提供面向公众的AI训练算力服务的企业,包括公有云、混合云及GPU租赁平台,均需向网信部门履行
算力资源备案
手续。备案内容涵盖:
- 可用GPU型号与总数
- 单用户最大并发卡数限制
- 数据出境管控方案
- 异常行为监测能力说明
阿里云、腾讯云等头部厂商均已上线“AI算力合规管理系统”,用户在开通RTX4090实例前需完成实名认证并填写用途声明,系统自动校验是否属于“科研教育”、“企业研发”或“个人学习”等许可类别。
5.3.2 动态水印与模型溯源技术实践
为应对深度伪造泛滥问题,中国推行“动态数字水印”强制嵌入机制。所有在境内训练的生成模型,必须在其输出中添加不可见的加密标识,以便事后追责。以下是PyTorch中实现隐写水印的代码示例:
import torch
import numpy as np
class WatermarkEmbedder:
def __init__(self, secret_key="ai_ethics_2024"):
self.key = np.array([ord(c) for c in secret_key]) % 256
def embed_in_latent(self, latent_tensor):
# 将水印编码为二进制序列
watermark_bits = np.unpackbits(self.key).astype(bool)
# 在潜变量最后几位注入扰动
flat = latent_tensor.flatten().detach().cpu().numpy()
for i, bit in enumerate(watermark_bits):
pos = -(i+1) # 从末尾插入
if bit:
flat[pos] += 1e-5 # 微小偏移,不影响视觉质量
else:
flat[pos] -= 1e-5
return torch.from_numpy(flat).reshape_as(latent_tensor).to(latent_tensor.device)
# 使用示例
embedder = WatermarkEmbedder()
z = torch.randn(1, 512, 64, 64).requires_grad_()
z_wm = embedder.embed_in_latent(z)
执行逻辑说明:
- 水印密钥转换为8位二进制流,共64位(假设密钥长度为8字符)。
- 修改潜空间张量的尾部数值,幅度控制在1e-5以内,远低于梯度噪声水平。
- 解码时可通过比较相邻元素符号变化恢复原始比特流。
- 此方法兼容Stable Diffusion等主流架构,已在百度文心一言、通义千问等产品中部署。
5.3.3 地方试点:上海AI算力交易平台的监管沙盒
上海市经信委联合多家高校推出“AI算力交易监管沙盒”,允许企业在受控环境中测试新型算力调度算法。平台内置三层过滤机制:
| 层级 | 检查内容 | 处置方式 |
|---|---|---|
| 接入层 | 用户身份真实性 | 对接公安部人口库核验 |
| 调度层 | 请求任务特征分析 |
拒绝含
faceswap
、
stylegan3
关键词作业
|
| 运行层 | 实时CUDA行为监控 |
发现高频
ncclAllReduce
调用则限速
|
沙盒内的所有任务均运行在容器化环境中,网络隔离且无法访问外部摄像头或社交媒体接口,从根本上阻断非法内容传播链路。
5.4 国际协同治理的可能性与挑战
尽管各国监管路径各异,但共同面临跨境算力滥用难题。一名位于东南亚的攻击者可通过匿名支付租用德国GPU集群,训练完成后将模型部署在美国服务器上,形成法律管辖真空。
为此,OECD正在推动建立“全球AI算力注册中心”概念,设想如下:
compute_resource_registry:
provider: "CloudProvider XYZ"
location: "Frankfurt, DE"
gpu_model: "RTX4090"
serial_numbers:
- "NVID-GPU-ABCD1234"
- "NVID-GPU-EFGH5678"
compliance_status:
eu_ai_act: true
nist_rmf_mapped: true
china_filing_id: "CN-GPU-2024-8867"
last_audit_date: "2024-07-15"
该YAML格式注册文件将作为国际互认的基础数据单元,未来可通过区块链分布式账本确保不可篡改。然而,实现这一愿景仍面临主权让渡、商业机密保护和技术互操作性三大障碍。
综合来看,唯有在尊重各国法律差异的前提下,推动最低限度的 算力标识标准化 、 日志格式统一化 与 黑名单共享机制 ,才有可能构建真正有效的全球AI伦理治理体系。
6. 未来展望——走向负责任的AI算力生态
6.1 全生命周期治理框架的构建路径
当前AI系统的伦理风险大多在模型部署后才被发现,这种“先建设、后治理”的模式已难以应对RTX4090级别算力带来的快速迭代能力。因此,必须建立覆盖“事前预防—事中监控—事后追溯”的全生命周期治理机制。
1. 事前预防:算力使用意图申报与风险预评估
云服务商可在用户申请高算力实例(如配备RTX4090的GPU节点)时引入结构化用途申报表单,并结合自然语言处理技术对申报内容进行语义分析。例如:
# 示例:用途申报文本的风险评分模型
from transformers import pipeline
# 加载预训练的分类模型
classifier = pipeline("text-classification", model="roberta-large-mnli")
def assess_usage_intent(text):
result = classifier(text)
# 判断是否涉及敏感关键词组合
sensitive_keywords = ["deepfake", "surveillance", "mass scraping", "automated influence"]
risk_score = sum(1 for kw in sensitive_keywords if kw in text.lower())
return {
"predicted_class": result[0]['label'],
"confidence": round(result[0]['score'], 3),
"keyword_risk_level": min(risk_score, 5) # 最高5分
}
# 调用示例
intent_text = "I need an RTX4090 instance to fine-tune Llama-3 for deepfake video generation."
print(assess_usage_intent(intent_text))
参数说明 :
-text: 用户提交的用途描述。
-sensitive_keywords: 预设的高风险行为关键词库。
- 输出包含NLP判断类别(如“entailment”或“neutral”)、置信度和基于规则的风险分数。
该机制可作为自动审批流程的第一道关卡,对高风险请求触发人工审核。
2. 事中监控:运行时行为感知与异常检测
在虚拟机或容器层面部署轻量级监控代理,实时采集GPU计算特征:
| 监控维度 | 指标名称 | 正常范围 | 异常阈值 | 可能风险 |
|---|---|---|---|---|
| 显存访问模式 | 显存读写比 | 6:4 ~ 7:3 | >9:1 | 数据窃取或加密挖矿 |
| 计算密度 | TFLOPS利用率 | 40%-80% | >95%持续>2h | 密集推理攻击 |
| 网络IO频率 | 每分钟HTTP请求数 | <100 | >1000 | 自动化爬虫 |
| 模型输出熵值 | 文本生成多样性(Shannon熵) | 4.0-5.5 bits/char | <3.0持续输出 | 内容操控模板化 |
| CUDA调用序列 | Kernel调用频率分布 | 符合Transformer模式 | 出现非标准卷积序列 | 自定义恶意模型加载 |
此类监控数据可通过API上报至中央审计平台,结合机器学习模型识别潜在滥用行为。
6.2 新兴技术赋能的治理创新
区块链驱动的算力使用存证系统
利用私有链或联盟链技术记录每一次GPU任务的启动、运行与终止过程,确保不可篡改。典型架构如下:
graph LR
A[用户提交任务] --> B(GPU调度器)
B --> C{生成元数据}
C --> D["任务ID、时间戳、CUDA版本、显存占用、网络流量"]
D --> E[签名并上链]
E --> F[(区块链节点集群)]
F --> G[审计方查询接口]
每条链上记录包含哈希指纹,第三方审计机构可通过智能合约定期验证合规性。例如,在以太坊兼容链上部署的简单存证合约片段:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract ComputeProvenance {
struct TaskRecord {
uint256 taskId;
address submitter;
uint256 timestamp;
string metadataHash;
bool verified;
}
mapping(uint256 => TaskRecord) public records;
uint256 public recordCount;
event TaskLogged(uint256 taskId, string metadataHash);
function logTask(string memory _metadataHash) external {
records[recordCount] = TaskRecord({
taskId: recordCount,
submitter: msg.sender,
timestamp: block.timestamp,
metadataHash: _metadataHash,
verified: false
});
emit TaskLogged(recordCount, _metadataHash);
recordCount++;
}
}
此系统支持跨平台、跨地域的统一审计标准建立。
碳足迹与社会影响量化仪表盘
随着绿色AI理念兴起,未来的云显卡管理界面应集成环境与社会成本可视化功能:
{
"session_id": "gpu-rtx4090-20241001-001",
"duration_hours": 6.5,
"energy_kWh": 2.8,
"co2_kg": 1.26,
"training_steps": 12500,
"parameters_updated": "7B",
"data_sources": ["LAION-5B", "CommonCrawl"],
"bias_metrics": {
"gender_disparity_score": 0.18,
"racial_representation_gap": 0.23
},
"ethics_rating": "B+"
}
此类仪表盘不仅提升透明度,也可作为企业ESG报告的数据来源。
6.3 教育体系与开发者文化的重塑
要实现真正的负责任AI,必须从人才培养源头入手。建议在计算机工程课程中增设以下模块:
-
《AI系统伦理设计》必修课
- 内容涵盖算法偏见溯源、隐私保护工程、算力资源责任使用
- 实验项目包括:为Stable Diffusion添加NSFW过滤器、构建公平性约束的推荐系统 -
开源社区激励机制改革
- GitHub等平台可引入“伦理贡献徽章”
- 对发布带有ethics.md文件的项目给予Star加权推荐 -
企业内部AI伦理审查委员会制度化
- 要求所有超过100 GPU小时的训练任务提交伦理影响声明
- 审查小组由技术、法务、社会学背景成员共同组成
这些措施将推动开发者从“我能做什么”转向“我应该做什么”的思维范式转变。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考


















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









