






Avro是个支持多语言的数据序列化框架,支持c,c++,c#,python,java,php,ruby,java。他的诞生主要是为了弥补Writable只支持java语言的缺陷。
1AVRO简介
很多人会问类似的框架还有Thrift和Protocol,那为什么不使用这些框架,而要重新建一个框架呢,或者说Avro有哪些不同。首先,Avro和其他框架一样,数据是用与语言无关的schema描述的,不同的是Avro的代码生成是可选的,schema和数据存放在一起,而schema使得整个数据的处理过程并不生成代码、静态数据类型等,为了实现这些,需要假设读取数据的时候模式是已知的,这样就会产生紧耦合的编码,不再需要用户指定字段标识。
Avro的schema是JSON格式的,而编码后的数据是二进制格式(当然还有其他可选项)的,这样对于已经拥有JSON库的语言可以容易实现。
Avro还支持扩展,写的schema和读的schema不一定要是同一个,也就是说兼容新旧schema和新旧客户端的读取,比如新的schema增加了一个字段,新旧客户端都能读旧的数据,新客户端按新的schema去写数据,当旧的客户端读到新的数据时可以忽略新增的字段。
Avro还支持datafile文件,schema写在文件开头的元数据描述符里,Avro datafile支持压缩和分割,这就意味着可以做Mapreduce的输入。
2 Avro Schemas
2.1 Schema定义
Schema是JSON格式的,包括下面三种形式:
1.JSON string类型,主要是原生类型
2.JSON数组,主要是union
3.JSON对象,格式:
{"type": "typeName" ...attributes...}
包括除原生类型和union以外的其他类型,attributes可以包括avro未定义的属性,这些属性并不会影响数据的序列化。
2.2原生类型
总共8种原生类型null,boolean,int,long,float,double,bytes,strings.
1.原生类型不需要attributes
2.可以通过type指定“string” 和 {"type":"string"}是等同的
3.不同语言的实现是不同的,比如double类型,在C,C++和java里就是double,而在Python里是float,在Ruby里是Float.
2.3复合类型
1、records
records一般是序列化数据的最终展现单元,而且可以自己嵌套。{
"type":"record",
"name":"LongList",
"aliases":["LinkedLongs"],
"fields" : [
{"name":"value", "type": "long"},
{"name":"next", "type": ["LongList", "null"]}
]
}
2、enums,枚举。{ "type": "enum",
"name":"Suit",
"symbols" :["SPADES", "HEARTS", "DIAMONDS","CLUBS"]
}
3、arrays,数组。{"type": "array", "items":"string"}
4、maps
map,keys必须是string,所以这里只指定了values的类型{"type": "map", "values": "long"}
5、unions
不能包含两个或者两个以上没有name属性的相同类型["string", "null"]
6、fixed
size指定每个值占用多少个字节{"type": "fixed", "size": 16,"name": "md5"}
2.4三种mapping
generic mapping
针对一种语言来说可能有不同的mapping,但是所有语言必须支持动态mapping,在处理之前并不知道schema
specific mapping
java和C++都可以事先生成源代码,比generic mapping有更多domain-oriented的api
reflect mapping
使用反射将avro类型转换成java类型,但这种mapping比前两种都慢,故弃用。
3 Avro序列化与反序列化
3.1准备工作
将一下schema保存成文件StringPair.avsc,放在src/test/resources目录下。{
"type":"record",
"name":"StringPair",
"doc":"A pair ofstrings",
"fields":[
{"name":"left","type":"string"},
{"name":"right","type":"string"}
]
}
引入最新版本的avro时要主要,最新的avro包为1.7.4,依赖org.codehaus.jackson:jackson-core-asl:1.8.8包,但是maven库中已经没有该版本,所以要换成其他版本。
org.codehaus.jackson
jackson-core-asl
1.9.9
如果你用的是1.0.4版本的hadoop(或者其他版本),依赖于jackson-mapper-asl,如果与jackson-core-asl版本不一致就会产生找不到方法等异常你需要入引入相同版本。
org.codehaus.jackson
jackson-mapper-asl
1.9.9
3.2 generic方式package com.sweetop.styhadoop;
import junit.framework.Assert;
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumReader;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.*;
import org.junit.Test;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-8-5
* Time: 下午7:59
* To change this template use File| Settings | File Templates.
*/
public class TestGenericMapping {
@Test
public void test() throwsIOException {
//将schema从StringPair.avsc文件中加载
Schema.Parser parser = newSchema.Parser();
Schema schema =parser.parse(getClass().getResourceAsStream("/StringPair.avsc"));
//根据schema创建一个record示例
GenericRecord datum = newGenericData.Record(schema);
datum.put("left","L");
datum.put("right","R");
ByteArrayOutputStream out =new ByteArrayOutputStream();
//DatumWriter可以将GenericRecord变成edncoder可以理解的类型
DatumWriter writer = newGenericDatumWriter(schema);
//encoder可以将数据写入流中,binaryEncoder第二个参数是重用的encoder,这里不重用,所用传空
Encoder encoder =EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum,encoder);
encoder.flush();
out.close();
DatumReader reader=newGenericDatumReader(schema);
Decoderdecoder=DecoderFactory.get().binaryDecoder(out.toByteArray(),null);
GenericRecordresult=reader.read(null,decoder);
Assert.assertEquals("L",result.get("left").toString());
Assert.assertEquals("R",result.get("right").toString());
}
}
result.get返回的是utf-8格式,需要调用toString方法,才能和字符串一致。
3.3 specific方式
首先使用avro-maven-plugin生成代码,pom的配置。
org.apache.avro
avro-maven-plugin
1.7.0
schemas
generate-sources
schema
StringPair.avsc
src/test/resources ${project.build.directory}/generated-sources/java
avro-maven-plugin插件绑定在generate-sources阶段,调用mvn generate-sources即可生成源代码,我们来看下生成的源代码:package com.sweetop.styhadoop;
/**
* Autogenerated by Avro
*
* DO NOT EDIT DIRECTLY
*/
@SuppressWarnings("all")
/** A pair of strings */
public class StringPair extendsorg.apache.avro.specific.SpecificRecordBase implementsorg.apache.avro.specific.SpecificRecord {
public static finalorg.apache.avro.Schema SCHEMA$ = new org.apache.avro.Schema.Parser().parse("{\"type\":\"record\",\"name\":\"StringPair\",\"doc\":\"Apair ofstrings\",\"fields\":[{\"name\":\"left\",\"type\":\"string\",\"avro.java.string\":\"String\"},{\"name\":\"right\",\"type\":\"string\"}]}");
@Deprecated
public java.lang.CharSequence left;
@Deprecated
public java.lang.CharSequenceright;
public org.apache.avro.SchemagetSchema() {
return SCHEMA$;
}
// Used by DatumWriter. Applications should not call.
public java.lang.Object get(intfield$) {
switch (field$) {
case 0:
return left;
case 1:
return right;
default:
throw neworg.apache.avro.AvroRuntimeException("Bad index");
}
}
// Used by DatumReader. Applications should not call.
@SuppressWarnings(value ="unchecked")
public void put(int field$,java.lang.Object value$) {
switch (field$) {
case 0:
left =(java.lang.CharSequence) value$;
break;
case 1:
right =(java.lang.CharSequence) value$;
break;
default:
throw neworg.apache.avro.AvroRuntimeException("Bad index");
}
}
/**
* Gets the value of the 'left'field.
*/
public java.lang.CharSequencegetLeft() {
return left;
}
/**
* Sets the value of the 'left'field.
*
* @param value the value toset.
*/
public voidsetLeft(java.lang.CharSequence value) {
this.left = value;
}
/**
* Gets the value of the 'right'field.
*/
public java.lang.CharSequencegetRight() {
return right;
}
/**
* Sets the value of the 'right'field.
*
* @param value the value toset.
*/
public voidsetRight(java.lang.CharSequence value) {
this.right = value;
}
}
为了兼容之前的版本生成了一组get,put方法,1.6.0后生成添加了getter/setter方法,还有一个与Builder的类,没什么用已经被我删掉
schama里的name里可以使用命名空间,如com.sweetop.styhadoop.StringPair,这样生成的源代码才会是带package的。
那我们来看如果使用这个生成的类,和generic方式有什么不同:package com.sweetop.styhadoop;
import junit.framework.Assert;
import org.apache.avro.Schema;
import org.apache.avro.io.*;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;
import org.junit.Test;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-8-6
* Time: 下午2:19
* To change this template use File| Settings | File Templates.
*/
public class TestSprecificMapping {
@Test
public void test() throwsIOException {
//因为已经生成StringPair的源代码,所以不再使用schema了,直接调用setter和getter即可
StringPair datum=newStringPair();
datum.setLeft("L");
datum.setRight("R");
ByteArrayOutputStreamout=new ByteArrayOutputStream();
//不再需要传schema了,直接用StringPair作为范型和参数,
DatumWriter writer=newSpecificDatumWriter(StringPair.class);
Encoder encoder=EncoderFactory.get().binaryEncoder(out,null);
writer.write(datum,encoder);
encoder.flush();
out.close();
DatumReader reader=newSpecificDatumReader(StringPair.class);
Decoder decoder=DecoderFactory.get().binaryDecoder(out.toByteArray(),null);
StringPairresult=reader.read(null,decoder);
Assert.assertEquals("L",result.getLeft().toString());
Assert.assertEquals("R",result.getRight().toString());
}
}
同点总结一下:
schema->StringPair.class, GenericRecord->StringPair。
4 AvroDatafile
4.1 datafile组成
datafile的组成如下图:
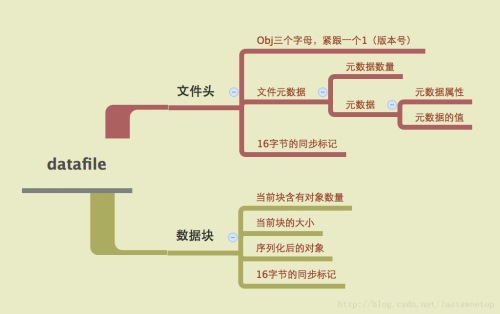
datafile分为文件头是数据块,如果看图还是不明白,那么看这个应该会很清楚,datafile文件头的schema:{"type": "record", "name":"org.apache.avro.file.Header",
"fields" : [
{"name":"magic", "type": {"type": "fixed","name": "Magic", "size": 4}},
{"name":"meta", "type": {"type": "map","values": "bytes"}},
{"name":"sync", "type": {"type": "fixed","name": "Sync", "size": 16}},
]
}
要注意的是16字节的同步标记,这个标记意味着datafile支持随机读,并且可以做分割,也意味着可以作为mapreduce的输入。
DataFileReader可以通过同步标记去随机读datafile文件。void seek(long position)
Move to a specific, known synchronization point, one returned fromDataFileWriter.sync() while writing.
void sync(long position)
Move to the next synchronization point after a position.
4.2 datafile写操作
以代码注释的方式进行讲解://首先创建一个扩展名为avro的文件(扩展名随意,这里只是为了容易分辨)
File file = new File("data.avro");
//这行和前篇文章的代码一致,创建一个Generic Record的datum写入类
DatumWriter writer = newGenericDatumWriter(schema);
//和Encoder不同,DataFileWriter可以将avro数据写入到文件中
DataFileWriterdataFileWriter = new DataFileWriter(writer);
//创建文件,并且写入头信息
dataFileWriter.create(schema,file);
//写datum数据
dataFileWriter.append(datum);
dataFileWriter.append(datum);
dataFileWriter.close();
4.3 datafile读操作
以代码注释的方式进行讲解:
//这行也和前篇文章相同,Generic Record的datum读取类,有点不一样的就是这里不需要再传入schema,因为schema已经包含在datafile的头信息里:DatumReader reader=newGenericDatumReader();
//datafile文件的读取类,指定文件和datumreader
DataFileReaderdataFileReader=new DataFileReader(file,reader);
//测试下读写的schema是否一致
Assert.assertEquals(schema,dataFileReader.getSchema());
//遍历GenericRecord
for (GenericRecord record : dataFileReader){
System.out.println("left="+record.get("left")+",right="+record.get("right"));
}
5 Avro schema兼容
5.1兼容条件
在实际的应用中,因为应用版本的问题经常遇到读和写的schema不相同的情况,幸运的是avro已经提供了相关的解决方案。
下面图示说明:

5.2 Record兼容
在hadoop的实际应用中,更多是以record的形式进行交互,接下来我们重点讲解下record的兼容。
首先从读写schema的角度取考虑,读写schema的不同无外乎就两种,读的schema比写的schema多了一个field,读的schema比写的schema少了一个field,这两种情况处理起来都很简单。
先看下写的schema:{
"type":"record",
"name":"com.sweetop.styhadoop.StringPair",
"doc":"A pair ofstrings",
"fields":[
{"name":"left","type":"string"},
{"name":"right","type":"string"}
]
}
1、增加了field的情况
增加了field后的schema:{
"type":"record",
"name":"com.sweetop.styhadoop.StringPair",
"doc":"A pair ofstrings",
"fields":[
{"name":"left","type":"string"},
{"name":"right","type":"string"},
{"name":"description","type":"string","default":""}
]
}
用增加了field的schema取读数据。
new GenericDatumReader(null, newSchema),第一个参数为写的schema,第二个参数为读的schema,
由于读的是avro datafile,schema已经在文件的头部指定,所以写的schema可以忽略掉。@Test
public void testAddField()throws IOException {
//将schema从newStringPair.avsc文件中加载
Schema.Parser parser = newSchema.Parser();
Schema newSchema =parser.parse(getClass().getResourceAsStream("/addStringPair.avsc"));
File file = new File("data.avro");
DatumReader reader = newGenericDatumReader(null, newSchema);
DataFileReader dataFileReader = newDataFileReader(file, reader);
for (GenericRecord record :dataFileReader) {
System.out.println("left=" + record.get("left") +",right=" + record.get("right") + ",description="
+record.get("description"));
}
}
输出结果为:left=L,right=R,description=
left=L,right=R,description=
description用默认值空字符串代替。
2、减少了field的情况
减少了field的schema:{
"type":"record",
"name":"com.sweetop.styhadoop.StringPair",
"doc":"A pair ofstrings",
"fields":[
{"name":"left","type":"string"}
]
}
用减少了field的schema取读取:@Test
public void testRemoveField()throws IOException {
//将schema从StringPair.avsc文件中加载
Schema.Parser parser = newSchema.Parser();
Schema newSchema = parser.parse(getClass().getResourceAsStream("/removeStringPair.avsc"));
File file = newFile("data.avro");
DatumReader reader = newGenericDatumReader(null, newSchema);
DataFileReader dataFileReader = newDataFileReader(file, reader);
for (GenericRecord record :dataFileReader) {
System.out.println("left=" + record.get("left"));
}
}
输出结果为:left=L
left=L
删除的field被忽略掉。
3、新旧版本schema
如果从新旧版本的角度取考虑。
新版本schema比旧版本schema增加了一个字段
1.新版本取读旧版本的数据,使用新版本schema里新增field的默认值
2.旧版本读新版本的数据,新版本schema里新增field被旧版本的忽略掉
新版本schema比旧版半schema较少了一个字段
1.新版本读旧版本的数据,减少的field被新版本忽略掉
2.旧版本读新版本的数据,旧版本的schema使用起被删除field的默认值,如果没有就会报错,那么升级旧版本。
5.3别名
别名是另一个用于schema兼容的方法,可以将写的schema的field名字转换成读的schema的field,记住并不是加了aliases字段。
而是将写的filed的name属性变为aliases,读的时候只认name属性。
来看下加了别名的schema:{
"type":"record",
"name":"com.sweetop.styhadoop.StringPair",
"doc":"A pair ofstrings",
"fields":[
{"name":"first","type":"string","aliases":["left"]},
{"name":"second","type":"string","aliases":["right"]}
]
}
使用别名schema去读数据,这里不能再用left,right,而要用first,second:@Test
public void testAliasesField()throws IOException {
//将schema从StringPair.avsc文件中加载
Schema.Parser parser = newSchema.Parser();
Schema newSchema =parser.parse(getClass().getResourceAsStream("/aliasesStringPair.avsc"));
File file = newFile("data.avro");
DatumReader reader = newGenericDatumReader(null, newSchema);
DataFileReaderdataFileReader = new DataFileReader(file, reader);
for (GenericRecord record :dataFileReader) {
System.out.println("first=" +record.get("first")+",second="+record.get("second"));
}
}
输出结果为:first=L,second=R
first=L,second=R

















 2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









