



 博客介绍了XML的两种解析方式。DOM解析形成树结构,保存在内存中,便于理解和修改;其解析步骤包括创建相关对象、获取节点列表等。SAX是事件驱动的解析方式,边扫描边解析,速度快、占用内存少,解析步骤有创建工厂、解析器等。
博客介绍了XML的两种解析方式。DOM解析形成树结构,保存在内存中,便于理解和修改;其解析步骤包括创建相关对象、获取节点列表等。SAX是事件驱动的解析方式,边扫描边解析,速度快、占用内存少,解析步骤有创建工厂、解析器等。
1、什么是DOM?
DOM:Document Object Model,文档对象模型,DOM解析形成了树结构,有助于更好的理解、且代码容易编写。解析过程中,树结构保存在内存中,方便修改。
2、DOM解析XML的步骤?
1、创建一个DocumentBuilderFactory的对象
2、创建一个DocumentBuilder对象
3、通过DocumentBuilder的parse(...)方法得到Document对象
4、通过getElementsByTagName(...)方法获取到节点的列表
5、通过for循环遍历每一个节点
6、得到每个节点的属性和属性值
7、得到每个节点的节点名和节点值。
3.DOM解析具体案例?
book.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- DTD -->
<!-- <!DOCTYPE books [
<!ELEMENT books (book*)>
<!ELEMENT book (name,author,price)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ATTLIST book id CDATA #REQUIRED>
]>
-->
<books xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="{book.xsd}">
<book id="1001">
<name>java开发实战</name>
<author>张小三</author>
<price>98.5</price>
</book>
<book id="1002">
<name>mysql从删库到跑路</name>
<author>飞毛腿</author>
<price>1000</price>
</book>
</books>TestDOMParser.java
package com.bjsxt.schema;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class TestDOMParse {
public static void main(String[] args) throws SAXException, IOException, ParserConfigurationException {
//1、创建一个DocumentBuilderFactory的对象
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
//2、创建一个DocumentBuilder对象
DocumentBuilder db=dbf.newDocumentBuilder();
//3、通过DocumentBuilder的parse(...)方法得到Document对象
Document doc=db.parse("book.xml");
//4、通过getElementsByTagName(...)方法获取到节点的列表
NodeList booklist=doc.getElementsByTagName("book");
System.out.println(booklist.getLength());
//5、通过for循环遍历每一个节点
for(int i=0;i<booklist.getLength();++i){
//6、得到每个节点的属性和属性值
Node book=booklist.item(i);
NamedNodeMap attrs=book.getAttributes();//得到属性的集合
//循环遍历每一个属性
for(int j=0;j<attrs.getLength();j++){
//得到每一个属性
Node id=attrs.item(j);
System.out.println("属性的名称:"+id.getNodeName()+"t"+id.getNodeValue());
}
}
System.out.println("n每个节点的名和节点的值");
//7、得到每个节点的节点名和节点值
for(int i=0;i<booklist.getLength();++i){
//得到每一个Book节点
Node book=booklist.item(i);
NodeList subNode=book.getChildNodes();
System.out.println("字节点的个数:"+subNode.getLength());
//使用for循环遍历每一个book 的子节点
for(int j=0;j<subNode.getLength();j++){
Node childNode=subNode.item(j);
// System.out.println(childNode.getNodeName());
short type=childNode.getNodeType();//获取节点的类型
if(type==Node.ELEMENT_NODE){
System.out.println("节点的名称:"+childNode.getNodeName()+"t"+childNode.getTextContent());
}
}
}
}
}
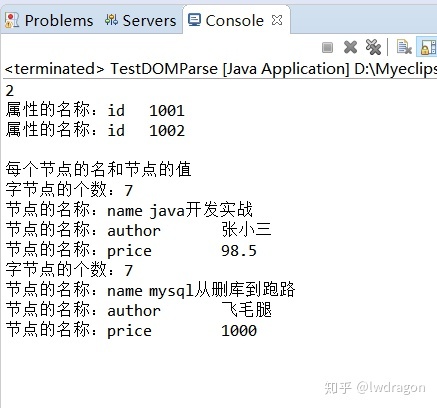
输出结果:
1、什么是SAX解析方式?
SAX,全称是Simple API for XML,是一种以事件驱动的XML API,SAX与DOM不同的是它边扫描边解析,自顶向下依次解析,由于边扫描边解析,所以它解析XML具有快,占用内存少的优点。
2、SAX解析XML的步骤?
1、创建SAXParseFactory的对象
2、创建SAXParse对象(解析器)
3、创建一个DefaultHandler的子类
4、调用parse方法
3、SAX解析方式的具体案例?
book.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- DTD -->
<!-- <!DOCTYPE books [
<!ELEMENT books (book*)>
<!ELEMENT book (name,author,price)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ATTLIST book id CDATA #REQUIRED>
]>
-->
<books xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="{book.xsd}">
<book id="1001">
<name>java开发实战</name>
<author>张小三</author>
<price>98.5</price>
</book>
<book id="1002">
<name>mysql从删库到跑路</name>
<author>飞毛腿</author>
<price>1000</price>
</book>
</books>TestSAXParser.java:
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.SAXException;
public class TestSAXParse {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1、创建SAXParseFactory的对象
SAXParserFactory spf=SAXParserFactory.newInstance();
//2、创建SAXParse对象(解析器)
SAXParser parser=spf.newSAXParser();
//3、创建一个DefaultHandler的子类
BookDefaultHandeler bdh = new BookDefaultHandeler();
//4、调用parse方法
parser.parse("book.xml",bdh);
}
}
BookDefaultHandeler.java:
package com.bjsxt.schema;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class BookDefaultHandeler extends DefaultHandler{
//重写第一个方法
/**解析xml文档开始时调用*/
@Override
public void startDocument() throws SAXException {
super.startDocument();
System.out.println("解析XML文档开始");
}
/**解析xml文档结束时调用*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("解析XML文档结束");
}
/**解析XML文档中的节点时调用*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
System.out.println("解析xml文档中节点时调用");
/**判断,如果是book节点,获取节点的属性和属性值*/
if("book".equals(qName)){
//获取所有的属性
int count=attributes.getLength();//属性的个数
//循环获取每个属性
for(int i=0;i<count;i++){
String attName=attributes.getQName(i);//属性名称
String attValue=attributes.getValue(i);//属性值
System.out.println("属性名称:"+attName+"t属性值为:"+attValue);
}
}else if(!"books".equals(qName)&&!"book".equals(qName)){
System.out.print("节点的名称:"+qName+"t");
}
}
//获取节点文本
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
String value=new String(ch,start,length);
if(!"".equals(value.trim())){
System.out.println(value);
}
}
/**解析XML文档的节点结束时调用*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
System.out.println("解析xml文档中的节点结束时调用");
}
}输出结果:

--------------------------------百战卓越058天---------------------------------------------------------------------------------------

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









