






 本文详细介绍了如何使用mmaction和tsn-pytorch对UCF101数据集进行预处理,包括视频提帧、生成file_list,以及如何利用这些帧进行特征提取。重点步骤包括创建文件夹结构、运行build_rawframes.py脚本和使用build_file_list.py划分训练集和测试集。最后,展示了模型保存与加载的方法。
本文详细介绍了如何使用mmaction和tsn-pytorch对UCF101数据集进行预处理,包括视频提帧、生成file_list,以及如何利用这些帧进行特征提取。重点步骤包括创建文件夹结构、运行build_rawframes.py脚本和使用build_file_list.py划分训练集和测试集。最后,展示了模型保存与加载的方法。
TSN
1.如何提帧
1.1数据集准备
下载网址:http://crcv.ucf.edu/data/UCF101/UCF101.rar
下载成功后的UCF文件夹如下所示:
该文件夹下是各种动作的视频文件,共有101种类别
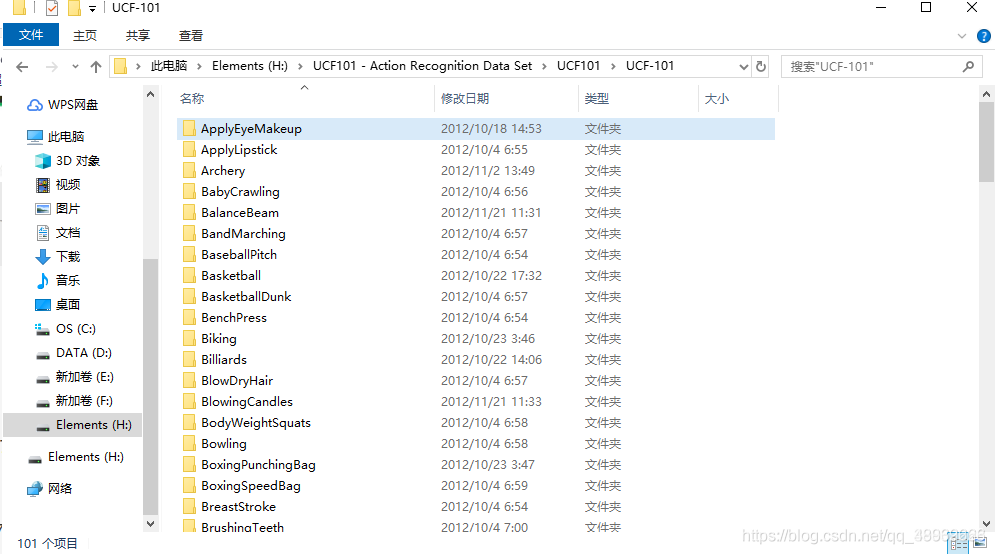
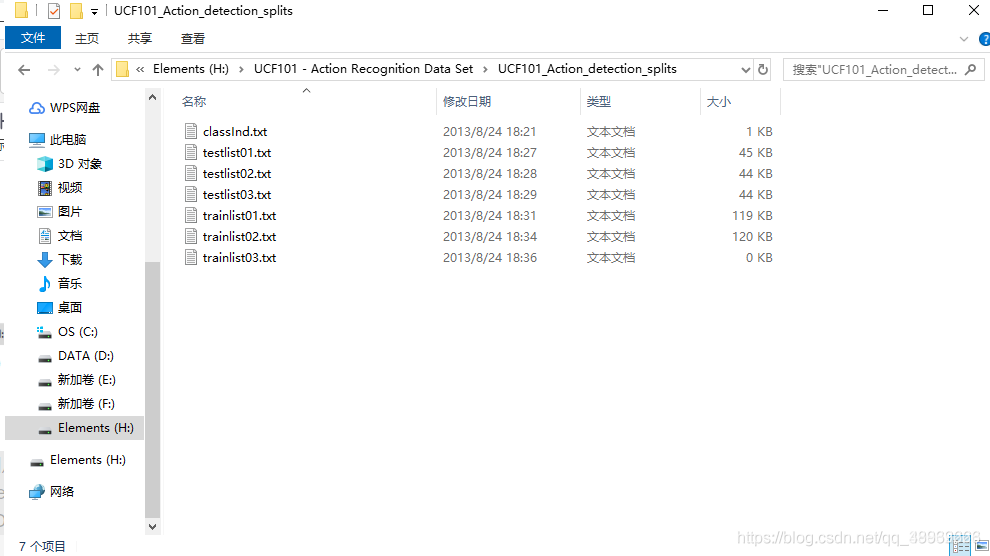
下图是UCF101在进行训练和测试时,分割的依据文件
1.2源码准备
在实验过程中,我们需要使用tsn-pytorch和mmaction的一些代码文件,所以我们提前从Git上获得存储在本地。
下载mmaction:
git clone --recursive https://github.com/open-mmlab/mmaction.git
下载tsn-pytorch:
git clone --recursive https://github.com/yjxiong/tsn-pytorch
1.3提帧
在我们下载好的UCF101数据集中,视频大多是长时间的,很难对其进行动作识别,所以需要进行提帧操作。
首先在mmaction的data/ucf101中创建rawframes、videos、annotations文件夹。
rawframes:视频提帧后存放的文件目录
videos:拷贝ucf101数据集中的101个文件目录,放置其中
annotations:ucf101之后进行分割训练集、测试集的依据文件
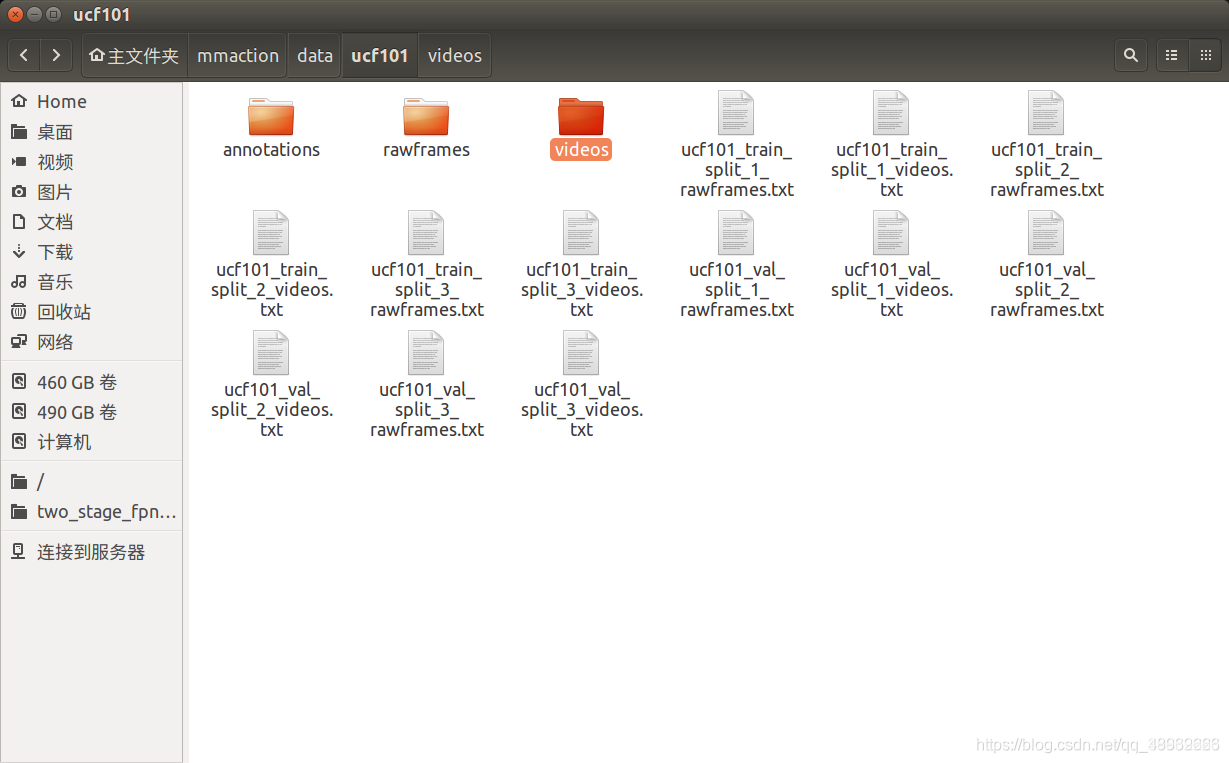
然后在mmaction/data_tools/build_rawframes.py的同级目录下进行视频提帧的代码文件,输入命令如下所示:
python build_rawframes.py ../data/ucf101/videos ../data/ucf101/rawframes/ --level 2 --ext avi
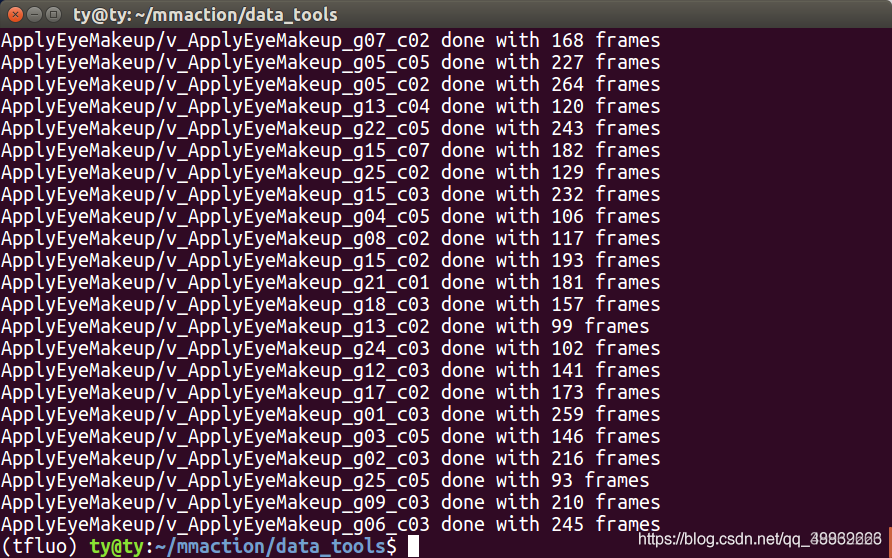
生成的文件目录形式如下所示:
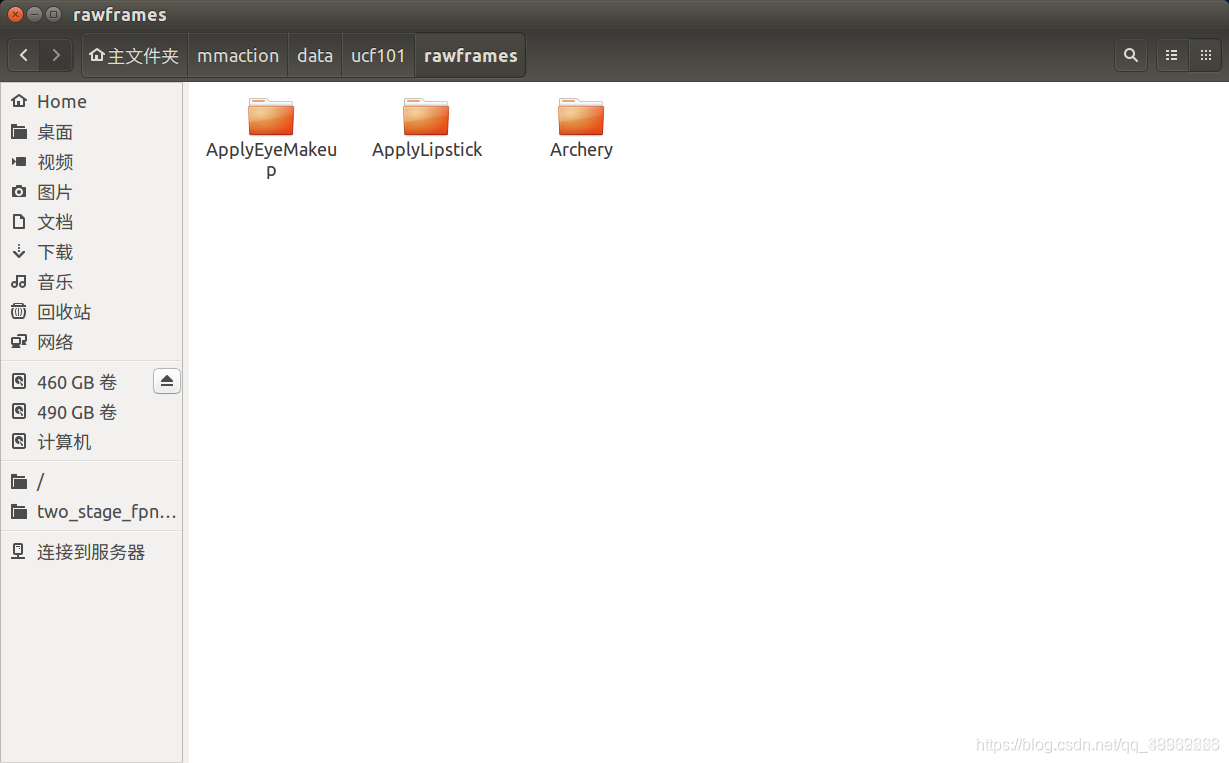
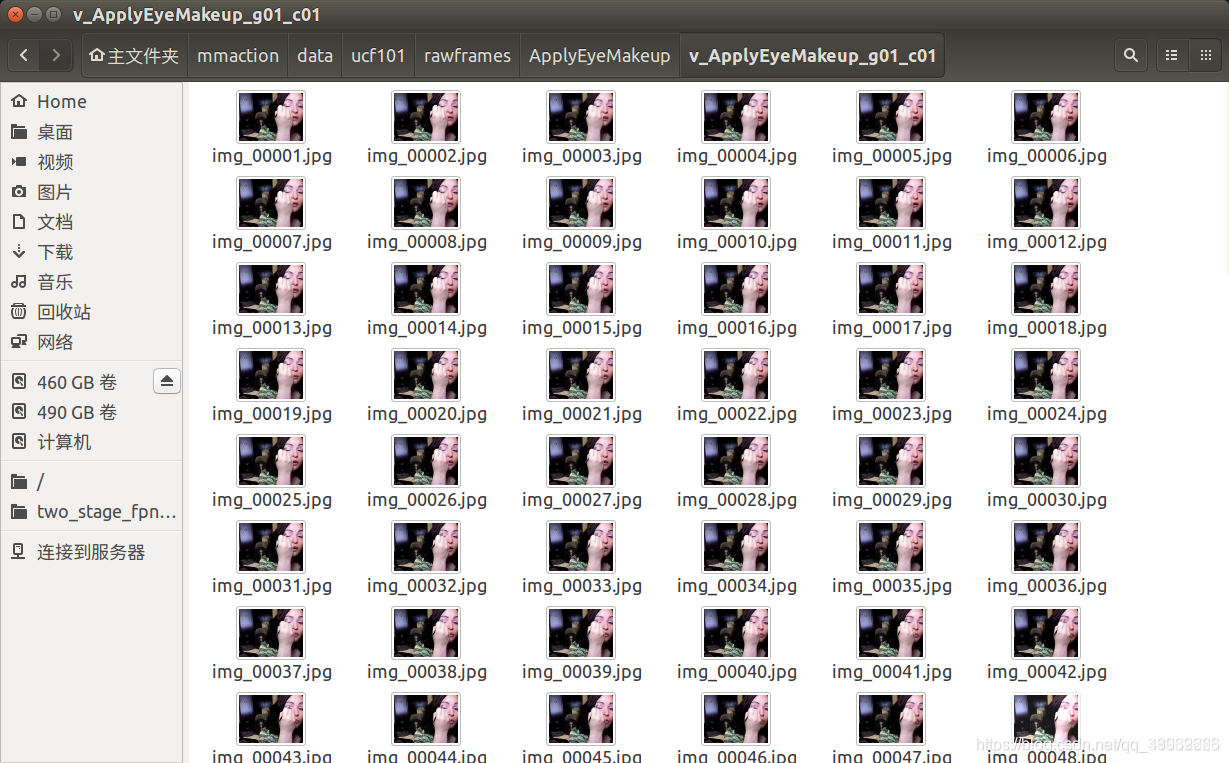
在这里插入图片描述
运行完成后,将每一个视频的每一帧提取出来,放在特定名称的文件夹中。
1.4生成file_list
在tsn-pytorch的readme文件中可以看到,训练过程中需要和,所以生成这两个list文件是必需的。使用mmaction/data_tools/buid_file_list.py即可对ucf101生成的帧进行训练集和测试集的划分。输入命令如下所示:
python data_tools/build_file_list.py ucf101 data/ucf101/rawframes/ --level 2 --format rawframes --shuffle
也可在mmaction/data_tools/ucf101/中输入
bash generate_filelist.sh
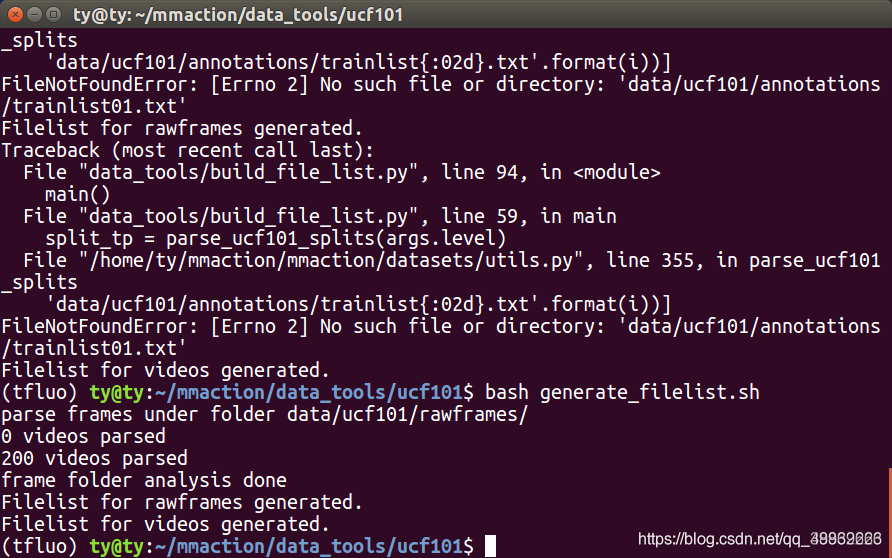
生成的filelist在data/ucf101目录下,形式如下:
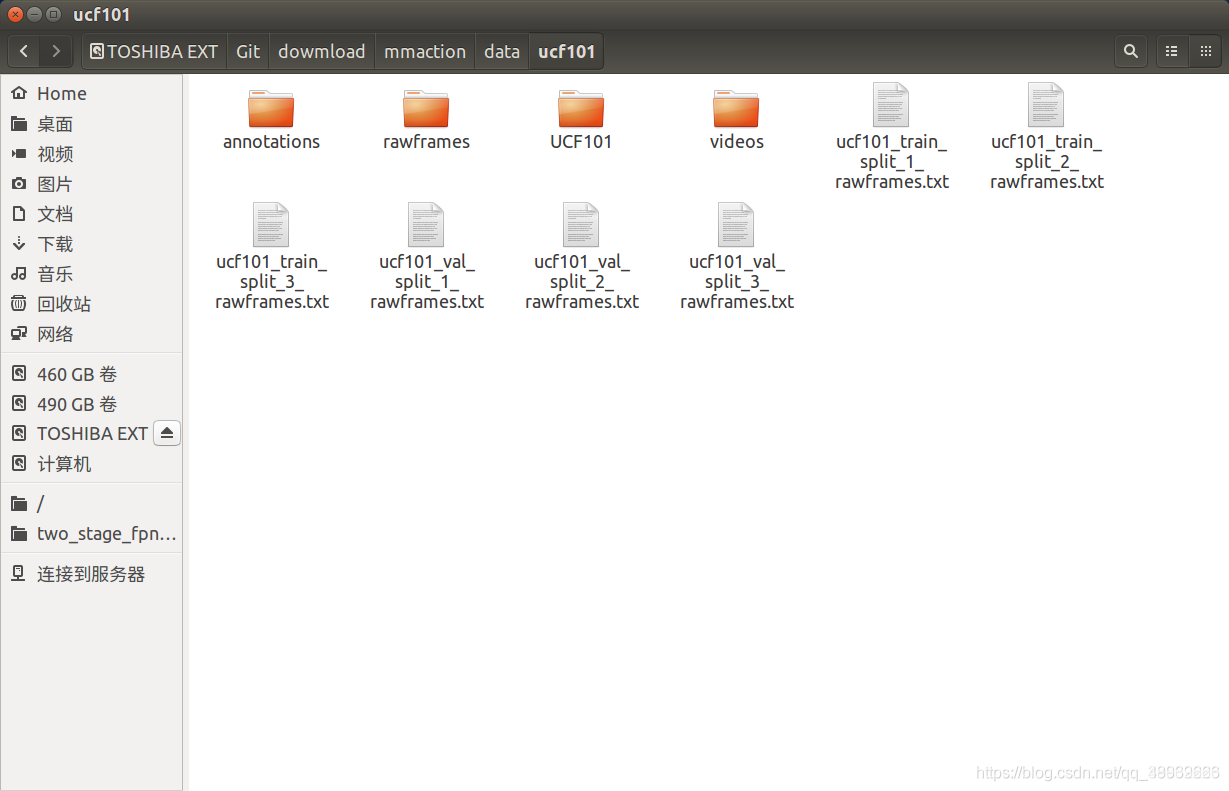
file_list的内容如下所示:
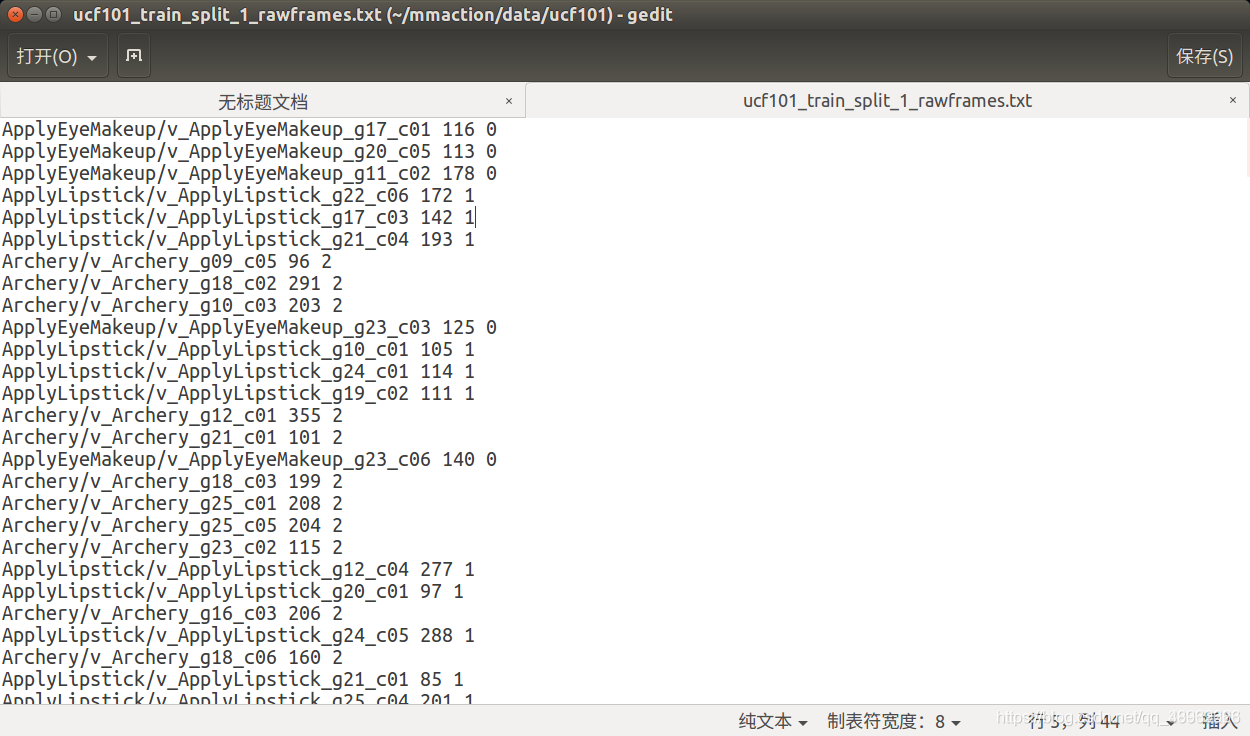
file_list中有三列,第一列代表文件的地址,第二列代表视频的帧数,第三列代表视频的类别。这里仅仅使用ucf101的3个文件夹,所以类别只有0 1 2。
2.如何feed帧出特征
代码修改部分参考 https://blog.youkuaiyun.com/qq_39862223/article/details/108461526
2.1IPO
下图展示了,TSN如何将ucf101数据集提出的帧进行分类的过程,标明了每一个阶段的tensor大小
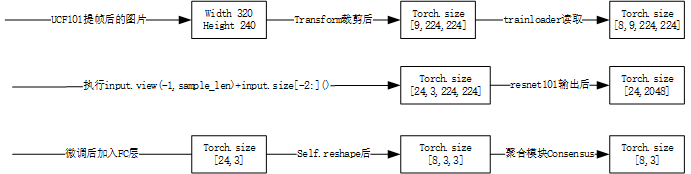
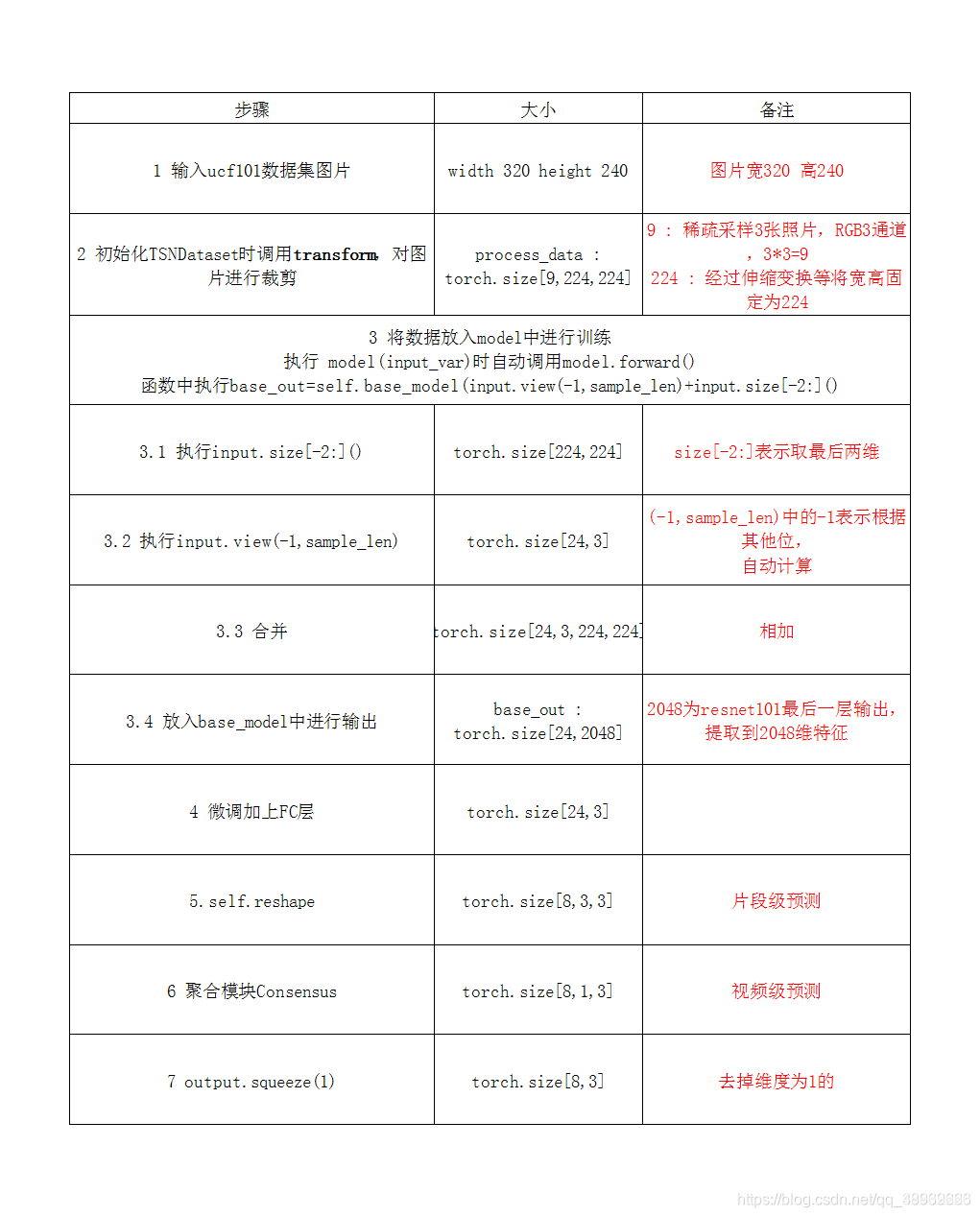
3.如何save,以便load
定义的保存模型以及参数信息的方法,该方法会在进行模型训练的时候得到调用。
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
filename = '_'.join((args.snapshot_pref, args.modality.lower(), filename)) # 用于保存模型以及参数信息的路径以及文件名
torch.save(state, filename) # 将模型以上述名称保存在该路径下
if is_best: # 如果准确率得到提高就进行模型的被备份
best_name = '_'.join((args.snapshot_pref, args.modality.lower(), 'model_best.pth.tar')) # 备份路径以及文件名称
shutil.copyfile(filename, best_name) # 进行文件复制
对该方法的调用,通过该方法保存模型,准确率,模型参数并判断是否进行模型复制
best_prec1 = max(prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
}, is_best)
加载保存的参数
if args.resume: # args.resume是保存模型的路径
if os.path.isfile(args.resume): # 判断该绝对路径下是否是文件,也就是保存模型方法中的绝对路径
print(("=> loading checkpoint '{}'".format(args.resume)))
checkpoint = torch.load(args.resume) # 进行加载checkpoint 字典的形式,里面包括epoch,arch,state_dict,best_prec1
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
print(("=> loaded checkpoint '{}' (epoch {})"
.format(args.evaluate, checkpoint['epoch'])))
else:
print(("=> no checkpoint found at '{}'".format(args.resume)))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









