






 本文介绍如何使用Python实现K近邻算法(KNN),并应用于CSV数据集的分类任务。通过详细代码示例,展示了距离计算、最近邻居选择及分类预测等关键步骤。此外,还涉及了算法参数调整以优化预测准确率。
本文介绍如何使用Python实现K近邻算法(KNN),并应用于CSV数据集的分类任务。通过详细代码示例,展示了距离计算、最近邻居选择及分类预测等关键步骤。此外,还涉及了算法参数调整以优化预测准确率。
目录:
1.从Qt中调用py脚本里的一个无参函数,功能:打印"hello python"
a)相关配置
b)踩过的一些坑
2.从Qt中调用py脚本里的一个有参函数并接收返回值 ,功能:实现 return a+b
4.在py中编写K近邻算法
继续上一篇利用Qt调用py脚本处理csv,接下来讲讲分类后的csv数据怎么利用呢?
直接先把py代码贴出来,由于有了前面几篇文章的基础,再加上我在重要的地方都加了注释,不懂的可以留言我,我看到了一定会回复的。
from math import sqrt class KNN: def __init__(self,k): self.k = k def fit(self,trainX,trainY): self.trainX=trainX self.trainY=trainY def distance(self,x,y): # 距离度量 res = 0.0 for i in range(len(x)): res += abs(int(x[i])-int(y[i]))**2 # print(i)#测试 res = sqrt(res) return res def findKN(self,dist): # 找到距离最近的K个节点 def fun(a): return a[1] indexed_dist = [ [v,k] for v,k in enumerate(dist)] new_dist = sorted(indexed_dist,key=fun) res = [] # 如果训练数据数量小于k的处理 if len(new_dist) > self.k: for i in range(self.k): res.append(new_dist[i][0]) else: for i in new_dist: res.append(i[0]) return res def predicate(self,testX): label = [] for test in testX: dist = [] # 计算当前节点到所有节点的距离 for k,v in enumerate(self.trainX): dist.append(self.distance(v,test)) # 找到最近的K个节点 kn = self.findKN(dist) nnl = [] for i in kn: nnl.append(self.trainY[i]) nnl.sort() res = [ 1 ,nnl[0]] # 找到出现次数最多的类别 for i in range(1,len(nnl)): if nnl[i] == res[1]: res[0]+=1 else: res[0] -= 1 if res[0] <= 0: res[0] = 0 res[1] = nnl[i] label.append(res[1]) return label def func2():import string import csv #加载csv包便于读取csv文件 csv_file=open("10.csv") #打开csv文件 csv_reader_lines = csv.reader(csv_file) #逐行读取csv文件 data=[] #创建列表准备接收csv各行数据 label=[] #标签 renshu = 0 for one_line in csv_reader_lines: data.append(one_line[1:4])#切片 1-3列 label.append(one_line[4:5])#切片 第四列 # print(data)#测试 x y z是否放入 # print(label)#测试 类别是否放入 knn = KNN(8) knn.fit(data,label) # 测试数据 testX = [[1700,1847,1887],[1787,2295,1887],[2047,2038,1658]]#8.csv中的数据 7 4 1 res = knn.predicate(testX) print(res)
main.cpp基本不怎么改,就用打印hello的那个,注意这里我的函数名变了,不要直接复制了。
qmake 编译 运行
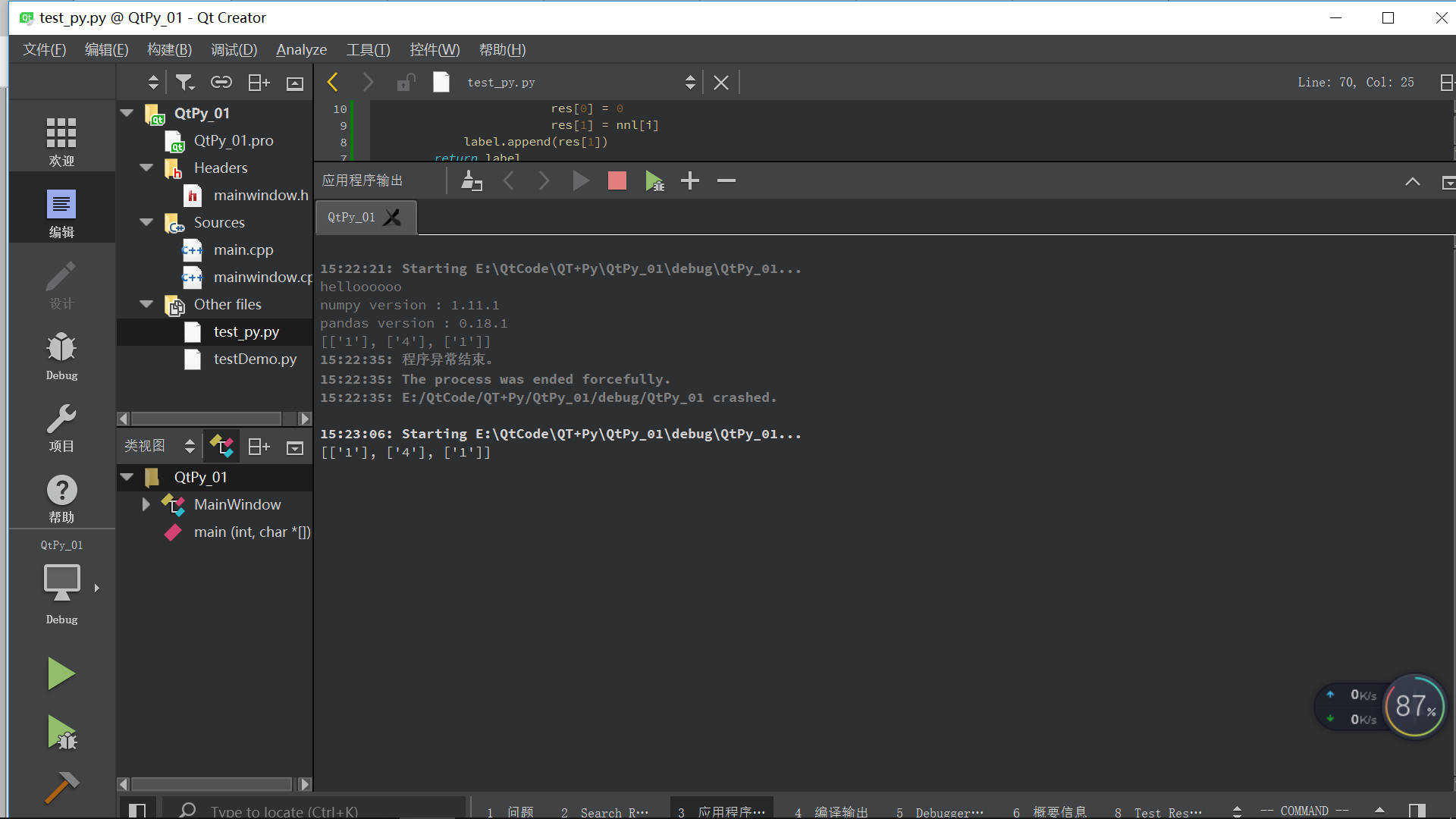
我用的是10.csv中的一万多条数据作为样本集,用8.csv中的几条数据作为测试集,发现后面两个预测对了,第一个不对,应该再去调一下k的参数,把错误率降到最低,或者是使用更加完善的K近邻算法。

















 1947
1947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









