



 本文介绍了一个具体的爬虫应用案例,通过Python的requests和BeautifulSoup库抓取校园新闻首页上的新闻标题、链接、正文等内容,并进一步解析了新闻的发布时间、作者、来源等信息。此外,还介绍了如何利用正则表达式获取新闻编号及点击次数。
本文介绍了一个具体的爬虫应用案例,通过Python的requests和BeautifulSoup库抓取校园新闻首页上的新闻标题、链接、正文等内容,并进一步解析了新闻的发布时间、作者、来源等信息。此外,还介绍了如何利用正则表达式获取新闻编号及点击次数。
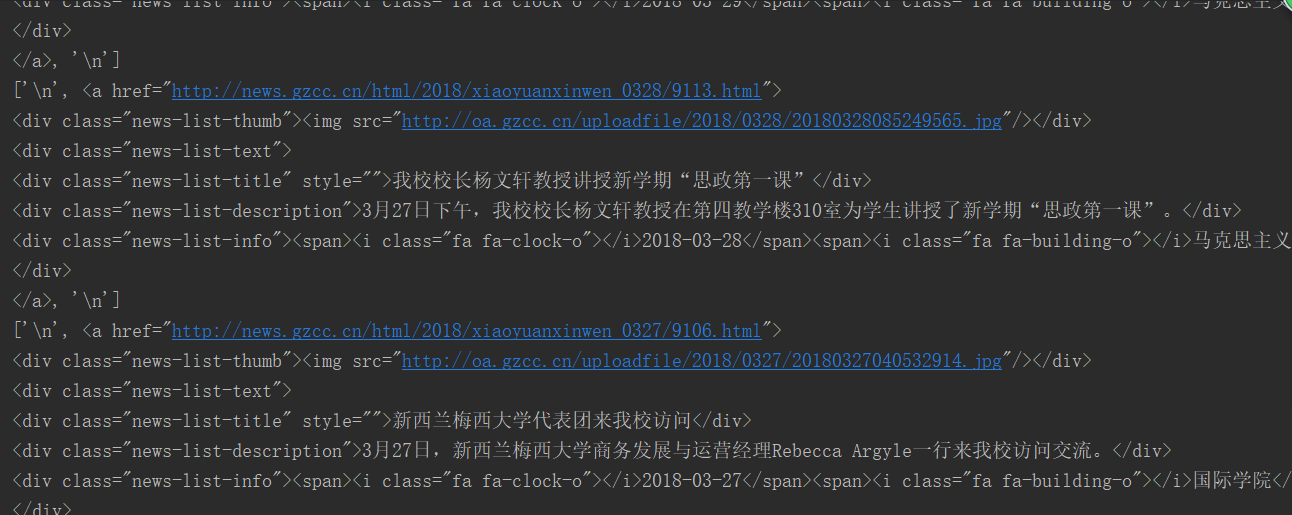
1. 用requests库和BeautifulSoup库,爬取校园新闻首页新闻的标题、链接、正文、show-info。
2. 分析info字符串,获取每篇新闻的发布时间,作者,来源,摄影等信息。
3. 将字符串格式的发布时间转换成datetime类型
4. 使用正则表达式取得新闻编号
5. 生成点击次数的Request URL
6. 获取点击次数
7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
9. 尝试用使用正则表达式分析show info字符串,点击次数字符串。
import requests
from bs4 import BeautifulSoup
import re
from datetime import datetime
def soup1(url):
req = requests.get(url)
req.encoding = 'utf-8'
soup = BeautifulSoup(req.text, 'html.parser')
return soup
def getNum(urls):
html_id = list()
j = 0
for i in urls:
html_id.append(re.search('http://news.gzcc.cn/html/2018/xiaoyuanxinwen_(.*).html', i).group(1).split('/')[-1])
down_url = 'http://oa.gzcc.cn/api.php?op=count&id=' + html_id[j] + '&modelid=80'
reqd = requests.get(down_url)
down_num.append(re.search("\('#hits'\).html\('(.*)'\);", reqd.text).group(1))
j = j + 1
return down_num
soup = soup1('http://news.gzcc.cn/html/xiaoyuanxinwen')
li_list = soup.select('li')
title = list()
a = list()
for new in li_list:
if (len(new.select('.news-list-text')) > 0):
title.append(new.select('.news-list-text')[0].select('.news-list-title')[0].text)
a.append(new.a.attrs['href'])
info_list = list()
con_list = list()
for curl in a:
con_soup = soup1(curl)
con_list.append(con_soup.select('#content')[0].text)
info_list.append(con_soup.select('.show-info')[0].text.split("\xa0\xa0"))
cs = list()
for i in range(len(con_list)):
cs.append(''.join(con_list[0]))
down_num = list()
down_num = getNum(a)
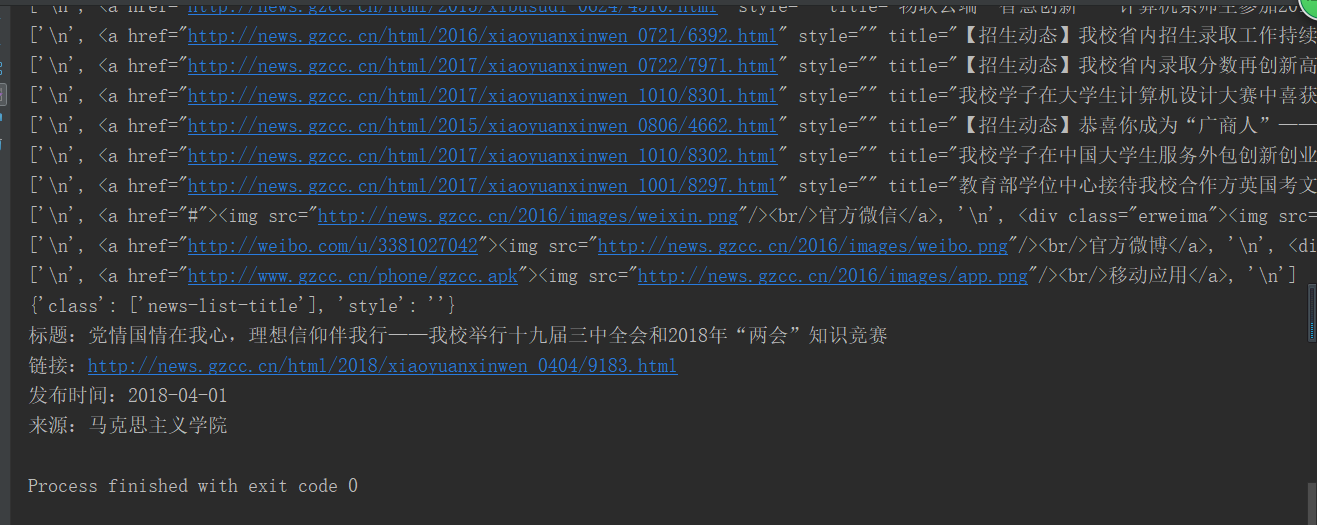
for i in range(len(info_list)):
print('标题:' + title[i])
print('链接:' + a[i])
for j in range(len(info_list[i])):
if (len(info_list[i][j]) > 0 and info_list[i][j] != ' '):
if (j != len(info_list[i]) - 1):
print(info_list[i][j])
else:
print(info_list[i][j].rstrip('次'), down_num[i], '次')
print(cs[i])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









