






 本文详细介绍了Python中类的定义与使用,包括构造函数、析构函数、私有成员、装饰器及不同类型的类方法。此外,还探讨了多线程的基本概念、实现方法及其在实际应用中的注意事项。
本文详细介绍了Python中类的定义与使用,包括构造函数、析构函数、私有成员、装饰器及不同类型的类方法。此外,还探讨了多线程的基本概念、实现方法及其在实际应用中的注意事项。
析构函数
1 class My:#类 2 def __init__(self): 3 print('构造函数,类在实例化时,会自动执行它') 4 # self.client = pymongo.MongoClient(host='',port=27017) 5 def __del__(self):#析构函数,这个实例被销毁的时候自动执行 6 print('什么时候执行我呢') 7 # self.client.close()#自动关闭数据库和文件
析构函数在实例化后执行完所有程序会执行,但是可以选择在什么时候让它结束
m=My()
del m
私有的类和变量
1 class My:#类 2 3 def __say(self):#安全性更高 4 #函数名或变量名前面加__,这个函数或变量就是私有的,只能在类里面用,类外无法使用 5 print('3') 6 def cry(self):#带self实例方法 7 self.__say() 8 print('4')
私有防止多人写一个项目重复给一个变量赋值,导致原来的被覆盖
装饰器
装饰器,不改变原来的函数,给函数添加新功能,可以自己写,也有写好的
1 def timer(func): 2 def war(*args,**kwargs): 3 start= time.time() 4 res = func(*args,**kwargs) 5 end_time = time.time() 6 print('运行时间是%s'%(end_time-start)) 7 return res 8 return war
用装饰器下载下图的图片
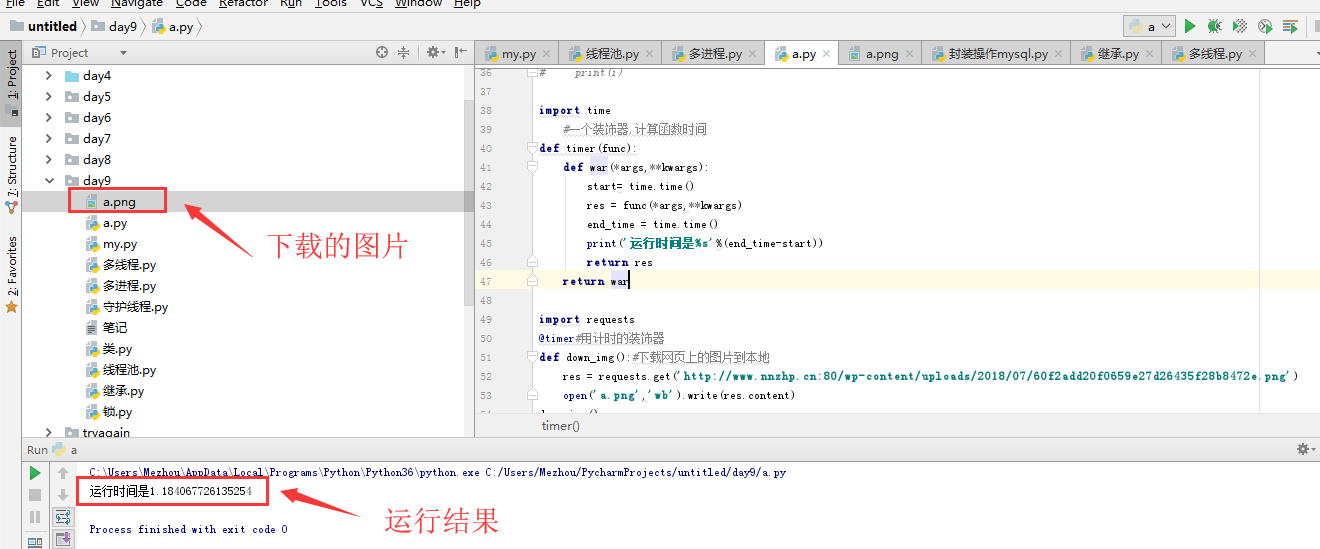
1 import requests 2 @timer#用计时的装饰器 3 def down_img():#下载网页上的图片到本地 4 res = requests.get('http://www.nnzhp.cn:80/wp-content/uploads/2018/07/60f2add20f0659e27d26435f28b8472e.png') 5 open('a.png','wb').write(res.content) 6 down_img()
运行结果:
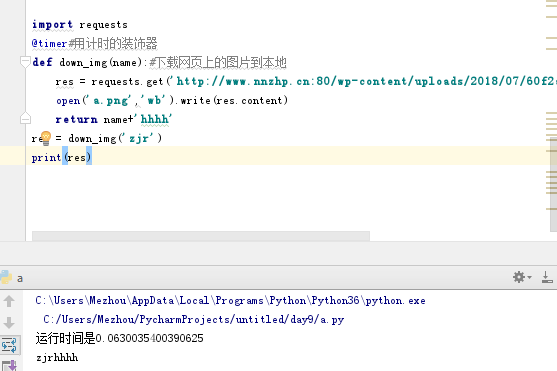
也可以传参有返回值

实例方法:
1 def cry(self):#带self是实例方法 2 self.__say() 3 print('4')
先实例化:m=My() 再调用:m.cry()
类方法:
1 @classmethod#装饰器,不改变原来的函数,给函数添加新功能 2 def eat(cls):#class 类方法 3 print(cls.country) 4 print('吃饭')
直接用类名调用:My.eat()
静态方法:
1 @staticmethod 2 def run(): 3 pass
直接用类名调用:My.run()
属性方法:
@property #属性方法 def red_pag(self): return 100 #调用时直接当做一个变量用,获取返回值
先实例化:m=My()
直接打印返回值:print(m.red_pag)
怎么搭建测试环境
第一次搭建
1、安装依赖软件 mysql、redis、tomcat、nginx、jdk
数据库、中间件等等
2、获取代码 svn git
3、编译(java c c##)
4、导入基础数据
5、修改配置文件
6、启动项目
日常部署
1、获取最新代码
2、编译(java c c##)
3、执行sql(如果数据库有改变的话)
4、修改配置文件
5、重启项目
继 承
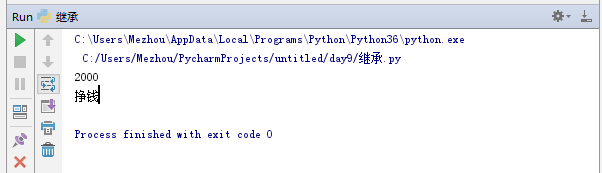
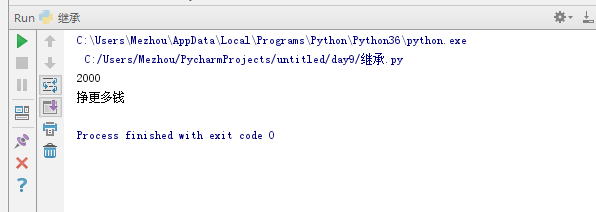
1 #继承的目的就是简化代码 2 import pymongo 3 class Ln: #父类 4 money = '2000' 5 def make_money(self): 6 print('挣钱') 7 class Me(Ln):#子类 8 # def make_money(self): 9 pass 10 # print('挣更多钱') 11 print(Me.money)#引用父类的类变量 12 nhy = Me()#实例化 13 nhy.make_money()#用父类的方法
结果:
子类继承后重写方法,会先在自己的类里找,再找父类,例子如下:
1 #继承的目的就是简化代码 2 import pymongo 3 class Ln: #父类 4 money = '2000' 5 def make_money(self): 6 print('挣钱') 7 class Me(Ln):#子类 8 def make_money(self):#方法已重写 9 pass 10 print('挣更多钱') 11 print(Me.money) 12 nhy = Me() 13 nhy.make_money()
1 class Base:#基类 2 def __init__(self,ip,port): 3 self.ip=ip 4 self.port=port 5 class MongoDb(Base): 6 def __init__(self,ip,port):#直接重写方法会报错,因为方法名相同就只运行类里的这一个方法,而这个方法里没有ip和端口号 7 9 self.client = pymongo.MongoClient(host=self.ip, port=self.port)#放在构造函数里只执行一遍 10 def save(self,data): 11 self.client['db']['table'].insert(data)
m=MongoDb('ip',27017)
修改:
1 class Base:#基类 2 def __init__(self,ip,port): 3 self.ip=ip 4 self.port=port 5 class MongoDb(Base): 6 def __init__(self,ip,port):#直接重写方法会报错,因为方法名相同就只运行类里的这一个方法,而这个方法里没有ip和端口号 7 # Base.__init__(self,ip,port)#两种方法,这一句和下面那一句同样的作用,这样就可以获取到父类的方法 8 super().__init__(ip,port)#调用父类方法 9 self.client = pymongo.MongoClient(host=self.ip, port=self.port) 10 def save(self,data): 11 self.client['db']['table'].insert(data) 12 13 m=MongoDb('ip',27017) 14 m.save({'name':'zjr','msg':'好好学习'})
1 class My: 2 def say(self): 3 print('说话') 4 # m=My() 5 # m.say() 6 # My.say(m) 7 My().say()
#
My().say()
等同于
m=My()
m.say()
等同于
m=My()
My.say(m)
super用来寻找父类
1 class Base:#基类 2 def __init__(self,ip,port): 3 self.ip=ip 4 self.port=port 5 def play(self): 6 print('football') 7 class MongoDb(Base): 8 def __init__(self,ip,port):#直接重写方法会报错,因为方法名相同就只运行类里的这一个方法,而这个方法里没有ip和端口号 9 # Base.__init__(self,ip,port)#两种方法 10 super().__init__(ip,port)#调用父类方法 11 12 self.client = pymongo.MongoClient(host=self.ip, port=self.port) 13 def save(self,data): 14 self.client['db']['table'].insert(data) 15 def play(self): 16 super().play() 17 print('basketball') 18 19 m=MongoDb('ip',27017) 20 # m.save({'name':'zjr','msg':'好好学习'}) 21 m.play()
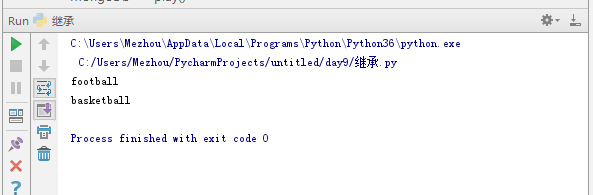
多线程、多进程
进程:一个进程就是一个程序。
线程:线程就是进程里面最小的执行单元。
线程是在进程里面的,干活的还是线程。
一个进程里面最少有一个线程,可以有多个线程
每个线程之间都是互相独立的
没有真正意义上的并发,你的电脑的cpu是几核的,那么最多只能同时运行几个任务。
串行:
1 import threading,time 2 def run(): 3 time.sleep(5) 4 print('哈哈哈哈') 7 for i in range(5):#串行 8 run()
多线程怎么用:
1 import threading,time 3 def run(name): 4 time.sleep(5) 5 print('【%s】哈哈哈哈'%name) 6 for i in range(10): 7 t=threading.Thread(target=run,args=(i,))#args要传元组,如果只有一个参数必须加一个逗号 8 t.start()
获取不到返回值怎么办?return回来的返回值获取不到
import threading,time all_res =[]#想要获取返回值就用一个字典或者列表。这是用来存储函数结果的。 def run(name): time.sleep(5) print('【%s】哈哈哈哈'%name) name ='hhj'+name all_res.append(name) print(all_res) for i in range(10): t=threading.Thread(target=run,args=(str(i),))#args要传元组,如果只有一个参数必须加一个逗号 t.start()


等待子线程都执行完成再计时和返回字典:
方法1:
import threading,time all_res =[]#想要获取返回值就用一个字典或者列表。这是用来存储函数结果的。 def run(name): time.sleep(5) print('【%s】哈哈哈哈'%name) name ='hhj'+name all_res.append(name) for i in range(10): t=threading.Thread(target=run,args=(str(i),))#args要传元组,如果只有一个参数必须加一个逗号 t.start() #主线程,线程之间是相互独立的 while threading.active_count()!=1:#判断当前活动的线程是几个,如果是1的话,说明子线程已经执行完成了 pass end = time.time() print(end-start) print('sleep之后的。。',all_res)

还有一种方法:
# t.join()#等待
1 import threading,time 2 all_res =[]#想要获取返回值就用一个字典或者列表。这是用来存储函数结果的。 3 def run(name): 4 time.sleep(5) 5 print('【%s】哈哈哈哈'%name) 6 name ='hhj'+name 7 all_res.append(name) 8 9 for i in range(10): 10 t=threading.Thread(target=run,args=(str(i),))#args要传元组,如果只有一个参数必须加一个逗号 11 threads.append(t) 12 t.start() 13 for t in threads:#再统一去等待子线程执行结束 14 t.join()#等待 15 end = time.time() 16 print(end-start) 17 print('sleep之后的。。',all_res)

查看线程的id
1 import threading,time 2 all_res =[]#想要获取返回值就用一个字典或者列表。这是用来存储函数结果的。 3 def run(name): 4 print('子线程执行的。。',threading.current_thread()) 5 time.sleep(5) 6 print('【%s】哈哈哈哈'%name) 7 name ='hhj'+name 8 all_res.append(name) 9 10 for i in range(3): 11 t=threading.Thread(target=run,args=(str(i),))#args要传元组,如果只有一个参数必须加一个逗号 12 threads.append(t) 13 t.start() 14 for t in threads:#再统一去等待子线程执行结束 15 t.join()#等待 16 17 print('主线程执行的。。', threading.current_thread()) 18 19 end = time.time() 20 print(end-start) 21 print('sleep之后的。。',all_res)

守护线程:
1 #守护线程 2 #守护线程就是和秦始皇陪葬的人一样 3 #主线程就是秦始皇 4 #子线程就是陪葬的人 5 import threading 6 import time 7 def run(): 8 time.sleep(9) 9 print('run...') 10 for i in range(10): 11 t = threading.Thread(target=run) 12 t.setDaemon(True)#设置子线程成为一个守护线程 13 t.start() 14 print('over.')

注释掉守护线程:
1 import threading 2 import time 3 def run(): 4 time.sleep(9) 5 print('run...') 6 for i in range(10): 7 t = threading.Thread(target=run) 8 # t.setDaemon(True)#设置子线程成为一个守护线程 9 t.start() 10 print('over.')

没有真正意义上的并发,你的电脑的cpu是几核的,那么最多只能同时运行几个任务。
python里面的多线程,是利用不了多核cpu的,只能利用一个核心的cpu
有些情况下,你用多线程的时候会发现它比单线程速度还慢。
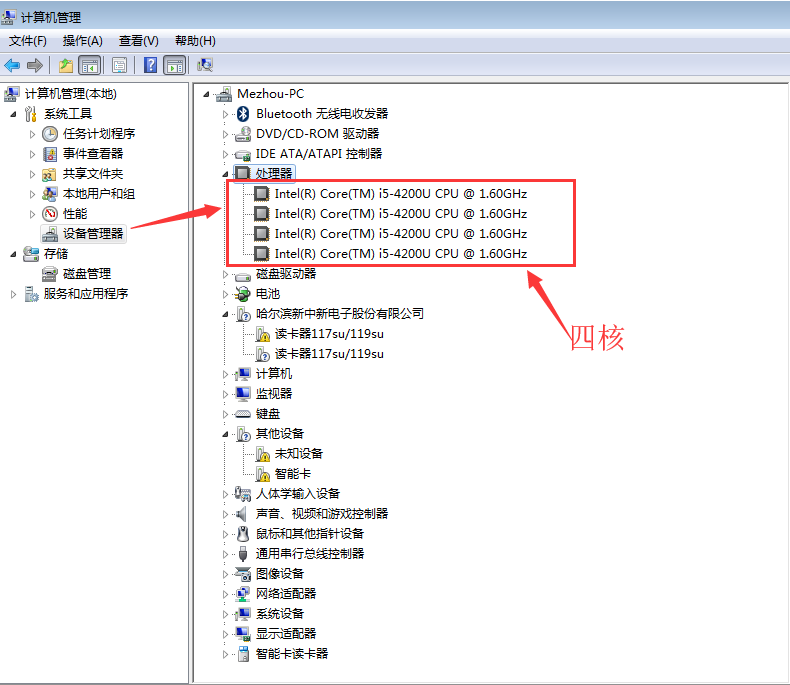
查看电脑的cpu是几核的:
python2里需要加锁,python3里自动加锁
1 import threading 2 from threading import Lock 3 4 num = 0 5 lock =Lock()#实例化一把锁 6 def run(): 7 global num 8 # lock.acquire()#加锁 9 # num+=1 10 # lock.release()#解锁 11 with lock:#自动加锁解锁 12 num+=1 13 for i in range(100): 14 t = threading.Thread(target=run) 15 t.start() 16 print(num)
线程池
安装threadpool模块(pip install threadpool)
import threadpool,requests,pymongo client = pymongo.MongoClient(host='ip',port=27017) table = client['likun']['qq_group_likun'] all_qq = [i.get('qq') for i in table.find()] url = 'http://q4.qlogo.cn/g?b=qq&nk=%s&s=140' def down_img(qq_num): res = requests.get(url%qq_num).content with open('%s.jpg'%qq_num,'wb') as fw: fw.write(res) pool = threadpool.ThreadPool(200)#线程池的大小 all_requests = threadpool.makeRequests(down_img,all_qq)#分配数据 for r in all_requests: pool.putRequest(r)#发请求 #[pool.putRequest(r) for r in all_requests]#同上两行 pool.wait()#等待所有的线程运行完 print('done,下载完成!')
进程和进程池(进程里可以启动线程)
1 from multiprocessing import Process, Pool, active_children 2 import pymongo,requests 3 client = pymongo.MongoClient(host='118.24.3.40',port=27017) 4 table = client['likun']['qq_group_likun'] 5 all_qq = [i.get('qq') for i in table.find()] 6 7 url = 'http://q4.qlogo.cn/g?b=qq&nk=%s&s=140' 8 def down_img(qq_num): 9 res = requests.get(url%qq_num).content 10 with open('%s.jpg'%qq_num,'wb') as fw: 11 fw.write(res) 12 if __name__=='__main__':#必须写,否则多进程用不了 13 for qq in all_qq: 14 # p = Process(target=down_img,args=(qq,)) 15 # p.start() 16 # print(active_children())#打印活动的进程数 17 pool = Pool(5)#指定进程池的大小 18 list(pool.map(down_img,all_qq))#运行,使用进程池 19 #map是个生成器
什么时候用多线程,什么时候用多进程?
多线程适用于io密集型任务
磁盘io iuput out
网络io
多进程适用于cpu密集型任务
eg:排序、计算


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









