






 本文探讨了Oracle数据库中共享池(sharedpool)的作用及其大小设置的最佳实践。解释了共享池如何通过缓存SQL语句和执行计划提高数据库效率,并讨论了共享池过大可能带来的负面影响。
本文探讨了Oracle数据库中共享池(sharedpool)的作用及其大小设置的最佳实践。解释了共享池如何通过缓存SQL语句和执行计划提高数据库效率,并讨论了共享池过大可能带来的负面影响。
这篇文章是参考甲骨论老相老师的教学视频:
http://v.youku.com/v_show/id_XMzkyMTg4Njg0.html
所做的学习笔记
前面已经提过shared pool(共享池)的作用和结构了, 详细看这里:
http://nvd11.blog.163.com/blog/static/200018312201301875752730/
总的来讲:
shared pool 就是用来缓存sql语句和对应执行计划的, 当一条sql第二次执行时能找到shared pool的共享sql的执行计划的就避免了硬解析, 大大提高了数据库的运行效率.
而现在内存白菜价, 一般的笔记本都随便上8g内存了, 很多服务器都64g内存起步.
理论上来讲, shared pool越大, 能缓存的sql语句和执行计划就越多, 能避免硬解析的几率就越高,那么是不是shared pool的容量越大越好呢, 其实不是这样的.
1.shared pool设置过大也有缺点:
硬解析在shared pool运作机制可以参考下图啦:
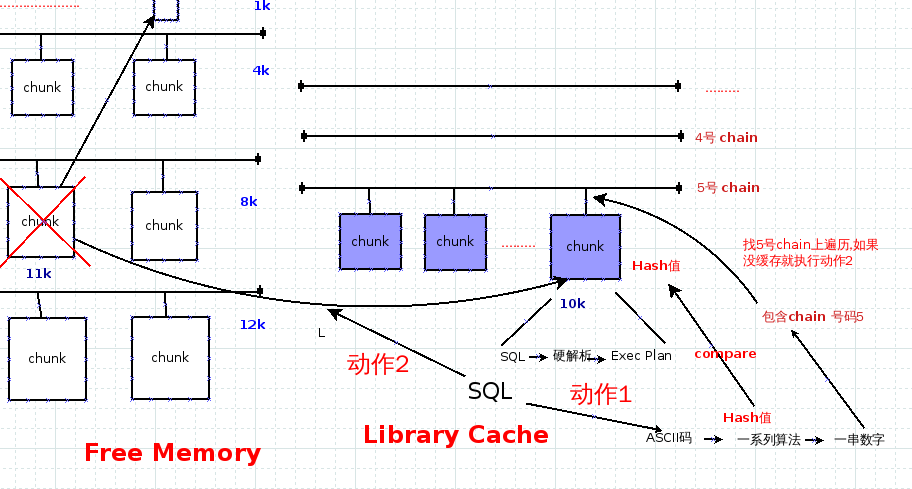
大致上1条sql 硬解析的语句会执行一下步骤:
1. SQL传入shared pool
2. SQL语句 会转换成ASCII码 经过一系列计算算出hash 值和For library cache的chain号码
3. 到library cache 对应chain号码的内存链chain上面根据hash值遍历每个chunk.
4. 找不到hash值相同的chunk啊(找到就是软解析了)
5. 到free memory空间找1个足够大的chunk.
6. 执行硬解析, 并把算出的执行计划放入这个chunk中,
7. 把这个chunk挂到library cache对应链中, 作为缓存,下次执行就能软解析了.
可以观察出,真正执行硬解析所需的只有1,5,6步, 其余都是为了下次软解析服务的.
所以说 ,假如oracle由于总总原因, 每次传入来的sql都不同,都不能共享sql,那么shared pool的这些动作实在是个累赘, 还不如不用shared pool, 当然这种情况几乎不可能,而且oracle也不能禁用shared pool的.
所以程序员做好SQL共享是1个很重要的事情啊.
参考:
http://nvd11.blog.163.com/blog/static/200018312201301945631729/
好了, 假如程序代码写得很规范, 而且都用绑定变量去实现SQL共享, 那么是否shared pool越大越好呢?
其实也不是, 仔细看看第3步, 是1个遍历线性表的动作, 如果shared pool很大, 则library cache也很大,那么library的数据链可能会很长,同时缓存了很多很不常执行的sql语句, 这样的遍历起来可能会变慢.(也不是很慢啦, 比短chain慢而已)
所以Oracle 在9g的时候建议shared pool大小最好不要超过1G
但是Oracle 10g后 应用了新技术, 如果shared pool很大, 则会对其分成1个个小部分, 那么数据链就不会很长了, 所以10g 可以设置大点, 老相老师他说见过生产数据库将shared pool设成10G的.
手动设置shared pool 大小:
其实一般来讲我们只需设置sga-target的大小就可以了, oracle会自动管理shared pool的size.
但是当服务器内存不能增加的时候, 也就是说sga-target被指定的情况下,怎么手动设置shared pool的size
其实oracle有个系统动态视图 v$shared_pool_advice 叫共享池建议..
我们可以借助它算出 大概的shared pool最佳大小(当前sga-target下)
select 'shared pool' component,
shared_pool_size_for_estimate estd_sp_size,
estd_lc_time_saved_factor parse_time_factor,
case when current_parse_time_elapsed_s + adjustment_s < 0
then 0
else current_parse_time_elapsed_s + adjustment_s
end response_time
from ( select a.shared_pool_size_for_estimate,
a.estd_lc_time_saved_factor,
a.estd_lc_time_saved,
e.value/100 current_parse_time_elapsed_s,
c.estd_lc_time_saved - a.estd_lc_time_saved adjustment_s
from v$shared_pool_advice a,
( select * from v$sysstat where name ='parse time elapsed') e,
( select estd_lc_time_saved
from v$shared_pool_advice
where shared_pool_size_factor = 1) c
);
执行试下:

一般来讲, 当PARSE_TIME_FACTOR 为 1, 也就是说shared pool设置为240m是最合理的.
查看当前系统自动管理下的shared pool大小:

的确比较接近这个值了.
手动设置SGA 大小:
当然可用
alter system set sga_target =xxx; 来设置了
注意设置为0 时,是交由ORACLE自动管理大小啦,
但是当手动设置时,如何获得最佳大小值呢,可以借助em管理页面 ,里面有ORACLE的推荐..
首先启动em服务你懂的:

接下来,在防火墙开发1158端口:
修改/etc/sysconfig/iptables

跟住重启防火墙服务:
service restart iptables
就可以在客户端浏览器登陆em了,地址是
https://192.168.0.112:1158/em/
注意服务器ip啦
登陆后,点击首页下方的指导中心:

再点击内存指导:

进入内存指导页面,默认情况下sga_target 是自动设置(sga_target =0), 是看不到建议的, 我们要禁用自动管理,
点击禁用:

这是可以手动设置了, 也可以设置sga里面各大池大小, 如下图 点击建议:

可以见到建议, 640m左右是最佳的,实际上也是oracle系统自动管理那个值啦...

http://v.youku.com/v_show/id_XMzkyMTg4Njg0.html
所做的学习笔记
前面已经提过shared pool(共享池)的作用和结构了, 详细看这里:
http://nvd11.blog.163.com/blog/static/200018312201301875752730/
总的来讲:
shared pool 就是用来缓存sql语句和对应执行计划的, 当一条sql第二次执行时能找到shared pool的共享sql的执行计划的就避免了硬解析, 大大提高了数据库的运行效率.
而现在内存白菜价, 一般的笔记本都随便上8g内存了, 很多服务器都64g内存起步.
理论上来讲, shared pool越大, 能缓存的sql语句和执行计划就越多, 能避免硬解析的几率就越高,那么是不是shared pool的容量越大越好呢, 其实不是这样的.
1.shared pool设置过大也有缺点:
硬解析在shared pool运作机制可以参考下图啦:
大致上1条sql 硬解析的语句会执行一下步骤:
1. SQL传入shared pool
2. SQL语句 会转换成ASCII码 经过一系列计算算出hash 值和For library cache的chain号码
3. 到library cache 对应chain号码的内存链chain上面根据hash值遍历每个chunk.
4. 找不到hash值相同的chunk啊(找到就是软解析了)
5. 到free memory空间找1个足够大的chunk.
6. 执行硬解析, 并把算出的执行计划放入这个chunk中,
7. 把这个chunk挂到library cache对应链中, 作为缓存,下次执行就能软解析了.
可以观察出,真正执行硬解析所需的只有1,5,6步, 其余都是为了下次软解析服务的.
所以说 ,假如oracle由于总总原因, 每次传入来的sql都不同,都不能共享sql,那么shared pool的这些动作实在是个累赘, 还不如不用shared pool, 当然这种情况几乎不可能,而且oracle也不能禁用shared pool的.
所以程序员做好SQL共享是1个很重要的事情啊.
参考:
http://nvd11.blog.163.com/blog/static/200018312201301945631729/
好了, 假如程序代码写得很规范, 而且都用绑定变量去实现SQL共享, 那么是否shared pool越大越好呢?
其实也不是, 仔细看看第3步, 是1个遍历线性表的动作, 如果shared pool很大, 则library cache也很大,那么library的数据链可能会很长,同时缓存了很多很不常执行的sql语句, 这样的遍历起来可能会变慢.(也不是很慢啦, 比短chain慢而已)
所以Oracle 在9g的时候建议shared pool大小最好不要超过1G
但是Oracle 10g后 应用了新技术, 如果shared pool很大, 则会对其分成1个个小部分, 那么数据链就不会很长了, 所以10g 可以设置大点, 老相老师他说见过生产数据库将shared pool设成10G的.
手动设置shared pool 大小:
其实一般来讲我们只需设置sga-target的大小就可以了, oracle会自动管理shared pool的size.
但是当服务器内存不能增加的时候, 也就是说sga-target被指定的情况下,怎么手动设置shared pool的size
其实oracle有个系统动态视图 v$shared_pool_advice 叫共享池建议..
我们可以借助它算出 大概的shared pool最佳大小(当前sga-target下)
select 'shared pool' component,
shared_pool_size_for_estimate estd_sp_size,
estd_lc_time_saved_factor parse_time_factor,
case when current_parse_time_elapsed_s + adjustment_s < 0
then 0
else current_parse_time_elapsed_s + adjustment_s
end response_time
from ( select a.shared_pool_size_for_estimate,
a.estd_lc_time_saved_factor,
a.estd_lc_time_saved,
e.value/100 current_parse_time_elapsed_s,
c.estd_lc_time_saved - a.estd_lc_time_saved adjustment_s
from v$shared_pool_advice a,
( select * from v$sysstat where name ='parse time elapsed') e,
( select estd_lc_time_saved
from v$shared_pool_advice
where shared_pool_size_factor = 1) c
);
执行试下:
一般来讲, 当PARSE_TIME_FACTOR 为 1, 也就是说shared pool设置为240m是最合理的.
的确比较接近这个值了.
手动设置SGA 大小:
当然可用
alter system set sga_target =xxx; 来设置了
注意设置为0 时,是交由ORACLE自动管理大小啦,
但是当手动设置时,如何获得最佳大小值呢,可以借助em管理页面 ,里面有ORACLE的推荐..
首先启动em服务你懂的:
接下来,在防火墙开发1158端口:
修改/etc/sysconfig/iptables
跟住重启防火墙服务:
service restart iptables
就可以在客户端浏览器登陆em了,地址是
https://192.168.0.112:1158/em/
注意服务器ip啦
登陆后,点击首页下方的指导中心:
再点击内存指导:
进入内存指导页面,默认情况下sga_target 是自动设置(sga_target =0), 是看不到建议的, 我们要禁用自动管理,
点击禁用:
这是可以手动设置了, 也可以设置sga里面各大池大小, 如下图 点击建议:
可以见到建议, 640m左右是最佳的,实际上也是oracle系统自动管理那个值啦...

















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









