



 本文介绍了一种使用Python的requests和json库从特定网站抓取已提交作业信息的方法,包括学生学号、姓名、作业标题、提交时间和作业链接,最终将信息整理成CSV格式保存。
本文介绍了一种使用Python的requests和json库从特定网站抓取已提交作业信息的方法,包括学生学号、姓名、作业标题、提交时间和作业链接,最终将信息整理成CSV格式保存。
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:
hwlist.csv 。
文件内容范例如下形式:
学号,姓名,作业标题,作业提交时间,作业URL
20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,
http://www.cnblogs.com/sninius/p/12345678.html
20194010102,李四,羊车门,2018-11-14 9:38:27.03,
http://www.cnblogs.com/sninius/p/87654321.html
*注1:如制作定期爬去作业爬虫,请注意爬取频次不易太过密集;
*注2:本部分作业用到部分库如下所示:
(1)requests —— 第3方库
(2)json —— 内置库
参考了各个大佬的代码后,我终于写完了。。。。。
import requests import json url='https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543986889827' r=requests.get(url) if r.status_code==200: date=json.loads(r.text)['data'] people='' for i in date: people+=str(i.get('StudentNo'))+','+str(i.get('RealName'))+','+str(i.get('Title'))+','+str(i.get('DateAdded').replace('T',' '))+','+str(i.get('Url')) +'\n' with open('hwlist.csv','w') as b : b.write(people) else: print('wrong')
运行后的结果为
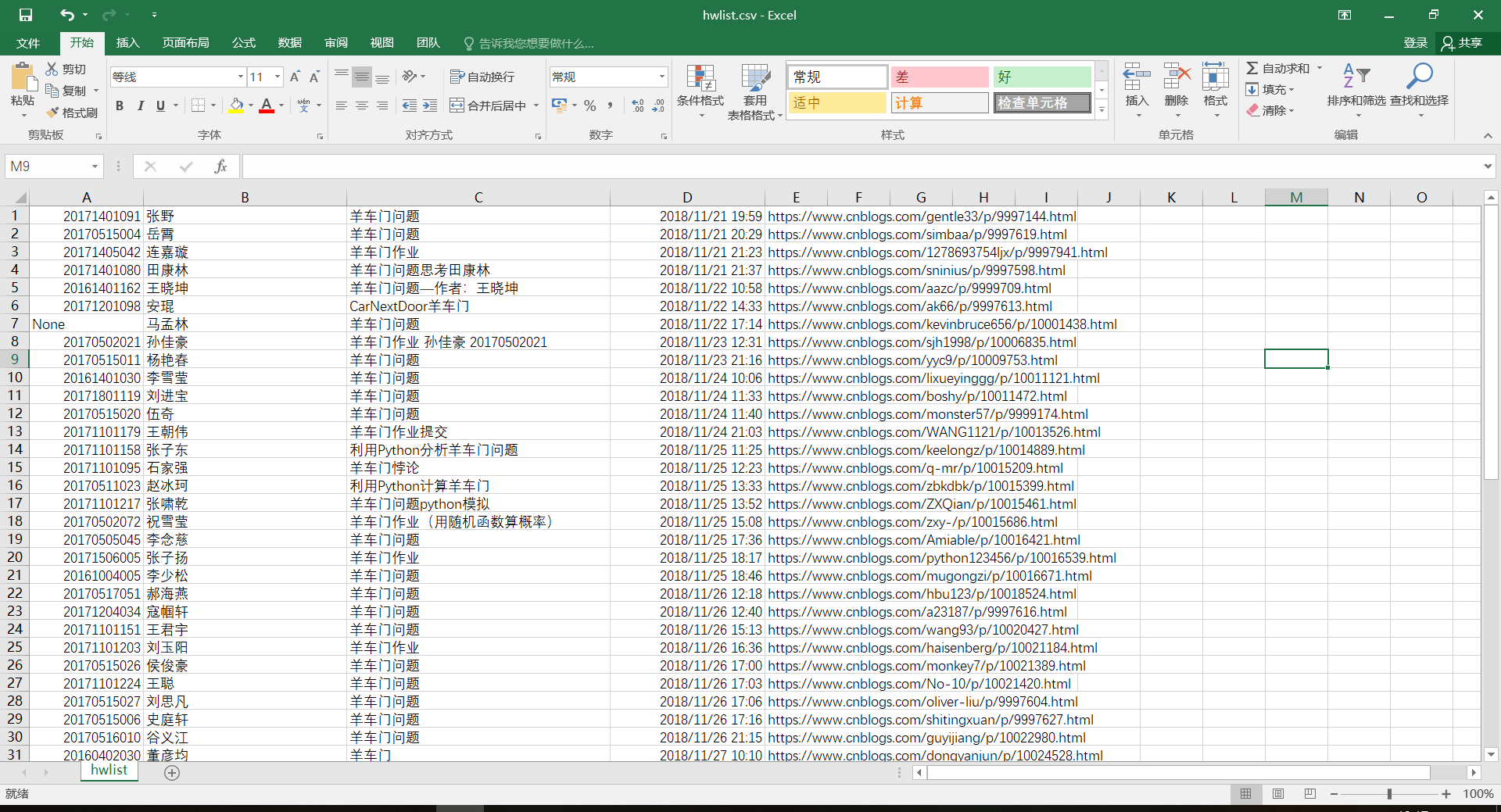

















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









