 C语言编程实践
C语言编程实践




 本文分享了C语言编程中八个常见问题的解决方案,包括字符串处理、成绩统计与排序等实际应用场景,通过具体实例介绍了如何使用指针、数组及结构体。
本文分享了C语言编程中八个常见问题的解决方案,包括字符串处理、成绩统计与排序等实际应用场景,通过具体实例介绍了如何使用指针、数组及结构体。
第二次作业
一.请将pta作业编程题目的解题思路和调试过程记录在博客中
1.删除字符串中数字字符
a.代码
void delnum(char *s)
{
char a[80];
int i=0,j=0;
for(j=0,j=0;*(s+i)!='\0';i++)
{
if(s[i]>'9'||s[i]<'0')
{
a[j]=s[i];
j++;
}
}
a[j]='\0';
strcpy(s,a);
}b.设计思路
本题的要求是删除给出的一行字符串中的数字字符,先定义两个变量ij然后用if循环遍历数组中元素判断数字字符并将其删除,之后将字符向前移动
c.问题
错误原因:本题中的且的符号||最开始我用的并的符号&&
2.统计子串在母串出现的次数
a.代码
int fun(char *str,char *substr)
{
int i,j,k,n;
for(i=0;str[i]!='\0';i++)
{
for(j=i,k=0;substr[k]==str[j];k++,j++)
{
if(substr[k+1]=='\0')
{
n++;
break;
}
}
}
return n;
}b.思路
定义指针函数,利用双层for循环判断字符串出现的次数,将最后的n值返回主函数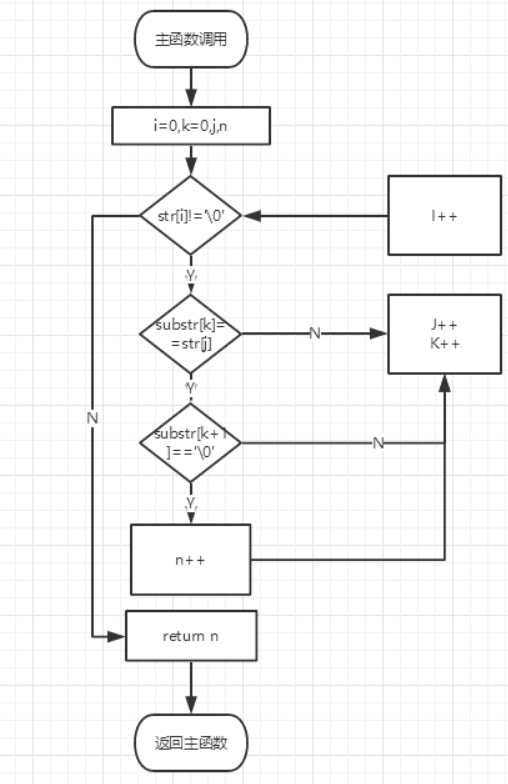
c.错误
错误原因:无法停止
改正方法:在n++后加brake
3.字符串中除首尾字符外的其余字符按降序排列
a.代码
int fun(char *s,int num){
int i,j,k,t;
for(i=1;i<num-2;i++){
k=i;
for(j=i+1;j<num-1;j++){
if((int)(*(s+k))<(int)(*(s+j))){
k=j;
}
}
if(k!=i){
t=*(s+i);*(s+i)=*(s+k);*(s+k)=t;
}
}
return 0;
}b.思路
定义指针函数。利用双层for循环(冒泡排序法)找到字符串的首尾字符的位置,将除首尾外的字符降序排序
c.错误
错误原因:排序混乱 冒泡排序时超出范围
改正方法:规定范围
4.输出学生成绩
a.代码
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main()
{
int n,i;
double *p;
double a[100],sum=0;
double max,min;
scanf("%d",&n);
if((p=(double*)malloc(n*sizeof(double)))==NULL)
{
exit(1);
}
for(i=0;i<n;i++)
{
scanf("%lf",p+i);
}
max=*p;
min=*p;
for(i=0;i<n;i++)
{
if(max<*(p+i))
{
max=*(p+i);
}
if(min>*(p+i))
{
min=*(p+i);
}
sum=sum+*(p+i);
}
printf("average = %.2lf\n",sum/n);
printf("max = %.2lf\n",max);
printf("min = %.2lf\n",min);
free(p);
return 0;
}b.思路
定义一个指向数组的指针变量,将数组的第一个元素赋值给最大值和最小值,并依次求出最大值和最小值和平均值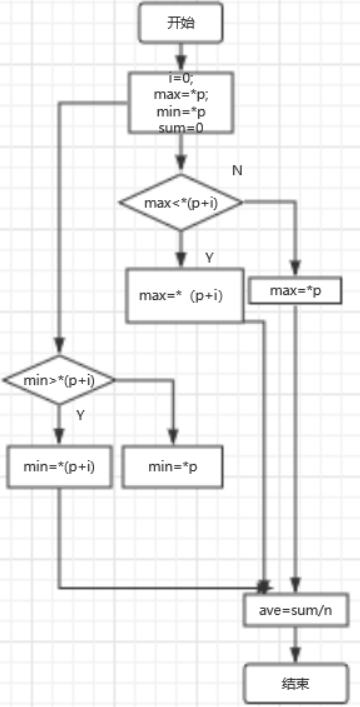
5.计算职工工资
a.代码
#include<stdio.h>
#include<stdlib.h>
struct xinxi
{
char name[10];
float jizi;
float fuzi;
float zhichu;
float shizi;
};
int main()
{
int N,i;
scanf("%d",&N);
struct xinxi a[N];
for(i=0;i<N;i++)
{
scanf("%s%f%f%f",a[i].name,&a[i].jizi,&a[i].fuzi,&a[i].zhichu);
}
for(i=0;i<N;i++)
{
a[i].shizi=a[i].jizi+a[i].fuzi-a[i].zhichu;
}
for(i=0;i<N;i++)
{
printf("%s %.2f\n",a[i].name,a[i].shizi);
}
system("pause");
return 0;
} b.思路
定义结构体变量,输入信息,利用for循环记录,利用for循环计算实资,利用for循环输出名字和实资
6.计算平均成绩
a.代码
#include<stdio.h>
#include<stdlib.h>
struct students
{
char xuhao[6];
char name[11];
int chengji;
};
int main()
{
int N,i;
int sum;
sum=0;
float average;
scanf("%d",&N);
struct students s[N];
for(i=0;i<N;i++){
scanf("%s %s %d",s[i].xuhao,s[i].name,&s[i].chengji);
}
for(i=0;i<N;i++)
{
sum=sum+s[i].chengji;
}
average=sum/N;
printf("%.2f\n",average);
for(i=0;i<N;i++)
{
if(s[i].chengji<average)
{
printf("%s %s\n",s[i].name,s[i].xuhao);
}
}
system("pause");
return 0;
}b.思路
定义结构体变量,将元素输入至结构变量,计算平均成绩,遍历结构变量中的成绩,并与平均成绩比较。如果成绩小于平均成绩,则输出信息。
c.错误
改正方法:将 printf("%.2f\n",average);放到for循环之上
7.按等级统计学生成绩
a.代码
int set_grade( struct student *p, int n )
{
int count=0;
int i;
for(i=0; i<n; i++)
{
if((p->score) >= 85 && (p->score) <= 100)
(p->grade) = 'A';
else if((p->score) >= 70 && (p->score)<= 84)
(p->grade) = 'B';
else if((p->score) >= 60 && (p->score) <= 69)
(p->grade) = 'C';
else if((p->score) >= 0 && (p->score) <= 59)
{
(p->grade) = 'D';
count ++;
}
p++;
}
return count;
}b.思路
用for循环来遍历,在for里嵌套if语句,用if语句来判断成绩的等级,在D等级中用count++来记有多少人不及格
c.错误
错误原因:将p指向了num,而没有指向score,指向错误
改正方法:p->score
8.结构体数组按总分排序
a.代码
void calc(struct student *p,int n)
{
int i;
for(i=0; i<n; i++)
{
(p+i)->sum = (p+i)->score[0] + (p+i)->score[1] +(p+i)->score[2];
}
}
void sort(struct student *p,int n)
{
struct student t;
int i,j;
for(i=0; i<n-1; i++)
{
for(j=0; j<n-i-1; j++)
{
if((p+j) -> sum < (p+j+1) -> sum)//((p+j)->sum < (p+j+1)->sum)
{
t = *(p+j);
*(p+j) = *(p+j+1);
*(p+j+1) = t;
}
}
}
}b.思路
用for循环求出每个人的总分,用冒泡排序法对每个人的总成绩进行降序排序
c.错误
错误原因:没有改变p的地址
改正方法:p+i,p+j
二.学习总结和进度
1.知识总结
我们这两次课学了struct 的构建,进一步加强指针的运用
2.评论
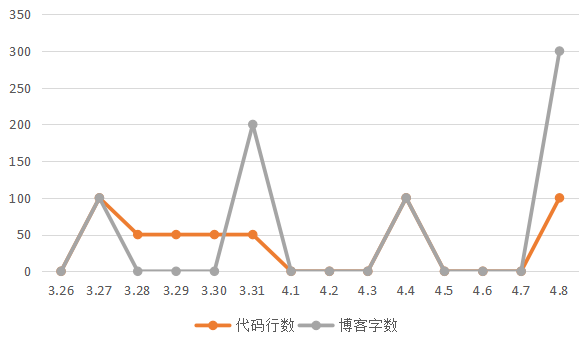
3.图表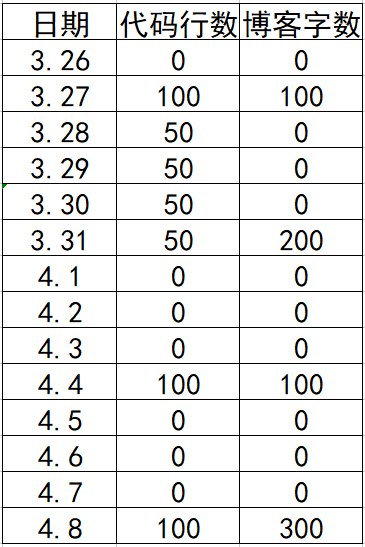

















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









