



 本文介绍了如何使用Python进行身份证信息解析,包括生日、性别和出生地的提取,以及实现文本的凯撒密码加密和解密。此外,还展示了如何统计英文歌词中各单词的出现频率,并提供了文件操作和函数定义的示例。
本文介绍了如何使用Python进行身份证信息解析,包括生日、性别和出生地的提取,以及实现文本的凯撒密码加密和解密。此外,还展示了如何统计英文歌词中各单词的出现频率,并提供了文件操作和函数定义的示例。
本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2684
1.字符串操作:
- 解析身份证号:生日、性别、出生地等。
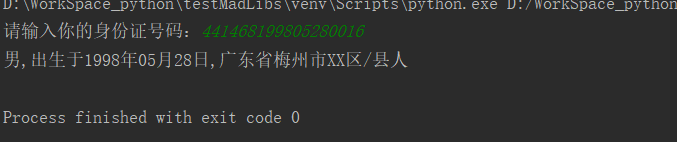
ID=input('请输入你的身份证号码:') sex = '女' if int(ID[16]) % 2 == 0 else '男' province = '广东省' if int(ID[0:2]) == 44 else 'XX省' city = '梅州市' if int(ID[2:4]) == 14 else 'XX市' county = '大山县' if int(ID[0:2]) == 89 else 'XX区/县' print('{},出生于{}年{}月{}日,{}{}{}人'.format(sex,ID[6:10],ID[10:12],ID[12:14],province,city,county))
运行示例:
- 凯撒密码编码与解码
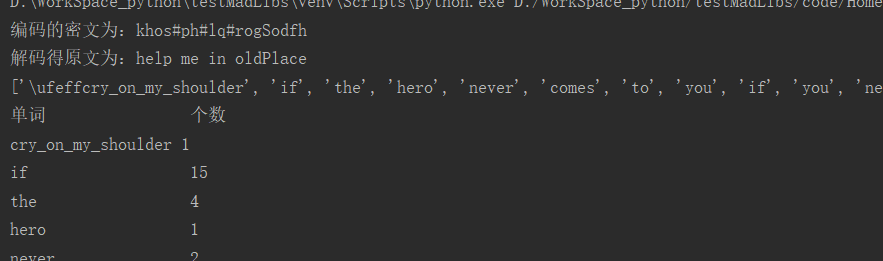
orign=input("请输入一句原文:") pas='' print('编码的密文为:',end='') for i in range(0, len(orign)): if orign[i] in ['x', 'y', 'z']: pas += chr(ord(orign[i])-23) else: pas += chr(ord(orign[i])+3) print(pas,end='') print('\n解码得原文为:',end='') for i in range(0, len(pas)): if pas[i] in ['a', 'b', 'c']: print(chr(ord(pas[i])+23),end='') else: print(chr(ord(pas[i])-3),end='')
运行示例:

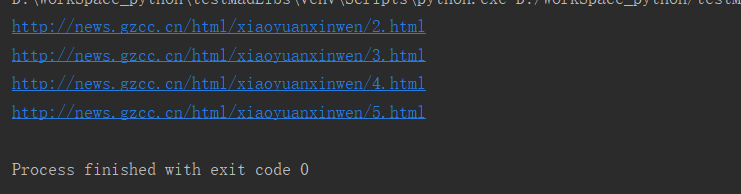
- 网址观察与批量生成
for i in range(2,6): url='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) print(url) import webbrowser as web for i in range(2,6): web.open_new_tab('http://news.gzcc.cn/html/xiaoyuanxinwen/'+ str(i) +'.html')
运行示例:
2.英文词频统计预处理


# 一首歌词 cry_on_my_shoulder = ''' If the hero never comes to you If you need someone you"re feeling blue If you"re away from love and you"re alone If you call your friends and nobody"s home You can run awaybut you can"t hide Through a storm and through a lonely night Then I show you there"s a destiny The best things in life They"re free But if you wanna cry Cry on my shoulder If you need someone who cares for you If you"re feeling sad your heart gets colder Yes I show you what real love can do If your sky is grey oh let me know There"s a place in heaven where we"ll go If heaven is a million years away Oh just call meand I make your day When the nights are getting cold and blue When the days are getting hard for you I will always stay here by your side I promise you I"ll never hide But if you wanna cry Cry on my shoulder If you need someone who cares for you If you"re feeling sad your heart gets colder Yes I show you what real love can do But if you wanna cry Cry on my shoulder If you need someone who cares for you If you"re feeling sad your heart gets colder Yes I show you what real love can do What real love can do What love can do What real love can do What love can do What real love can do ''' # 将所有大写转换为小写 cry_on_my_shoulder = cry_on_my_shoulder.lower() #re表示待替换的符号 re='.?!:\"\'\n' # 将所有其他做分隔符替换为空格 for i in re: cry_on_my_shoulder = cry_on_my_shoulder.replace(i,' ') # 分隔出一个一个的单词 words_list=cry_on_my_shoulder.split() print(words_list) # 统计单词出现的次数 print('单词 个数') total_words_times = 0 #存储不重复的单词 result = [] # 过滤重复的单词 for j in words_list: isRepeat=False for c in result: if j == c: isRepeat=True if isRepeat==False: result.append(j) # 输出统计结果语句 for ch in result: total_words_times += words_list.count(ch) print('{:<10}{:<5}'.format(ch,words_list.count(ch))) print('共有',total_words_times,'个单词')
运行示例:

3.文件操作与函数定义
# 加密函数 def encryption(file): f = open(file,'r',encoding='utf8') orign = f.read() f.close() password='' print('编码的密文为:',end='') for i in range(0, len(orign)): if orign[i] in ['x', 'y', 'z']: password += chr(ord(orign[i])-23) else: password += chr(ord(orign[i])+3) print(password) # 解密函数 def deciphering(file): f = open(file,'r',encoding='utf8') password = f.read() f.close() orign='' print('解码得原文为:', end='') for i in range(0, len(password)): if password[i] in ['a', 'b', 'c']: orign += chr(ord(password[i]) + 23) else: orign += chr(ord(password[i]) - 3) print(orign) # 读文本函数 def get_text(file): f = open(file, 'r', encoding='utf8') text = f.read() f.close() # 将所有大写转换为小写 text = text.lower() #re表示待替换的符号 re='.?!:\"\'\n' # 将所有其他做分隔符替换为空格 for i in re: text = text.replace(i,' ') # 分隔出一个一个的单词 words_list=text.split() print(words_list) # 统计单词出现的次数 print('单词 个数') total_words_times = 0 #存储不重复的单词 result = [] # 过滤重复的单词 for j in words_list: isRepeat=False for c in result: if j == c: isRepeat=True if isRepeat==False: result.append(j) # 输出统计结果语句 for ch in result: total_words_times += words_list.count(ch) print('{:<20}{:<8}'.format(ch,words_list.count(ch))) print('共有',total_words_times,'个单词') # 调用函数 # 同一目录 encryption('orign.txt') # 相对路径 deciphering("../files/password.txt") # 绝对路径 get_text('D:\\学习\\myLoveSong.txt')
运行示例:

















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









