






1.引入spark包:spark-assembly-1.4.0-hadoop2.6.0,在spark的lib目录下
File-->project structure
2.用IDEA建立一个scala项目,新建一个WordCount的object
3.WordCount代码如下:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ object WordCount { def main(args: Array[String]) { if (args.length < 1) { System.err.println("Usage: <file>") System.exit(1) } val conf = new SparkConf() val sc = new SparkContext(conf) val line = sc.textFile(args(0)) line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println) sc.stop() } }
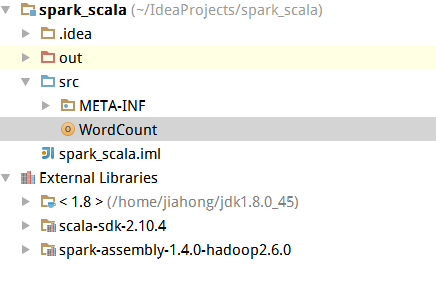
4.打包jar包:IDEA-->Project Structure-->Artifacts-->点击+
注意:点击From modules with dependencies,不是Empty
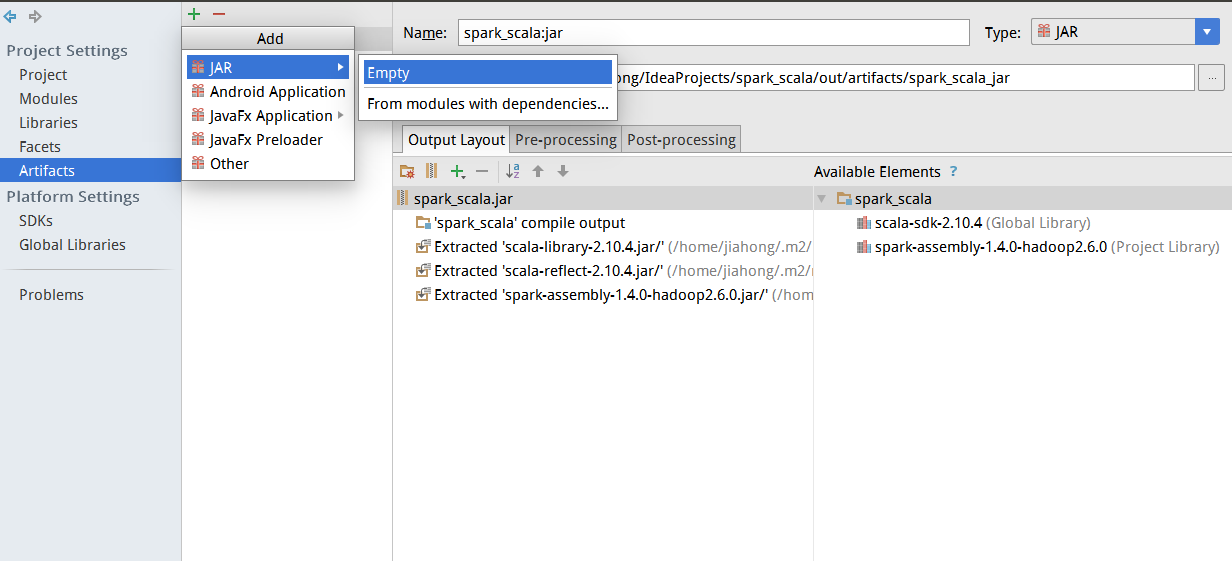
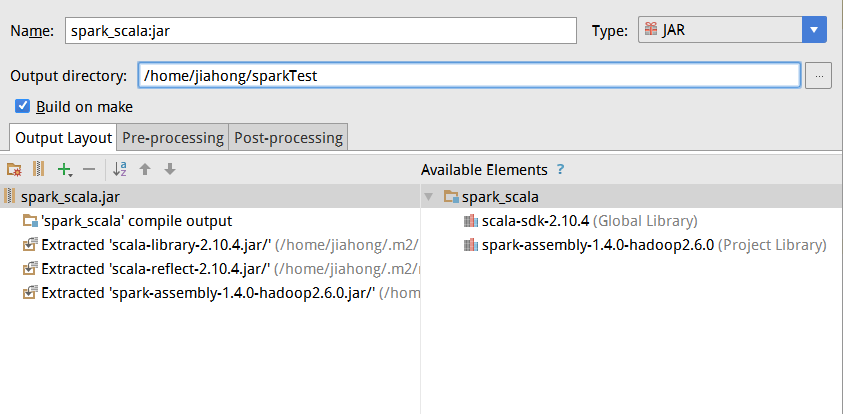
5.填写好导出的路径,我的是放在/home/jiahong/sparkTest目录
6.启动spark集群,到http://localhost:8080/查看spark的主节点地址,我的为:spark://jiahong-OptiPlex-7010:7077

7.在终端上次jar包到spark
jiahong@jiahong-OptiPlex-7010:~/spark-1.4.0-bin-hadoop2.6$ bin/spark-submit --master spark://jiahong-OptiPlex-7010:7077 --name spark_scala --class WordCount --executor-memory 1G --total-executor-cores 2 ~/sparkTest/spark_scala.jar /home/jiahong/jia.txt
进入hadoop,然后用spark-submit命令来提交jar包,如果看不懂上面的命令,则可以用spark-submit --help查看帮助
spark://jiahong-OptiPlex-7010:7077 为主节点的地址
--name spark_scala 为导出的jar包的名字
--class WordCount 为单词计数的object名
--executor-memory 1G --total-executor-cores 2 指定用多少内存执行和,执行的CPU核数是多少
~/sparkTest/spark_scala.jar 为导出的jar包的位置
/home/jiahong/jia.txt 为要WordCount输入的计算统计词频文件位置
9.运行时查看任务状态地址:
http://192.168.22.7:4040

















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









