



 本文介绍如何通过MapReduce程序进行网站日志数据预处理,包括数据过滤、格式转换及生成点击流模型数据,为后续统计分析奠定基础。
本文介绍如何通过MapReduce程序进行网站日志数据预处理,包括数据过滤、格式转换及生成点击流模型数据,为后续统计分析奠定基础。
五、 模块开发----数据预处理
1. 主要目的
过滤“不合规”数据,清洗无意义的数据
格式转换和规整
根据后续的统计需求,过滤分离出各种不同主题(不同栏目path)的基础数据。
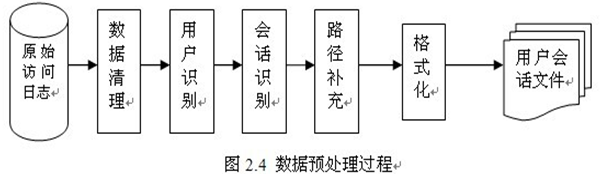
2. 实现方式
开发一个mr程序WeblogPreProcess(内容太长,见工程代码)
1. 点击流模型数据梳理
由于大量的指标统计从点击流模型中更容易得出,所以在预处理阶段,可以使用mr程序来生成点击流模型的数据。
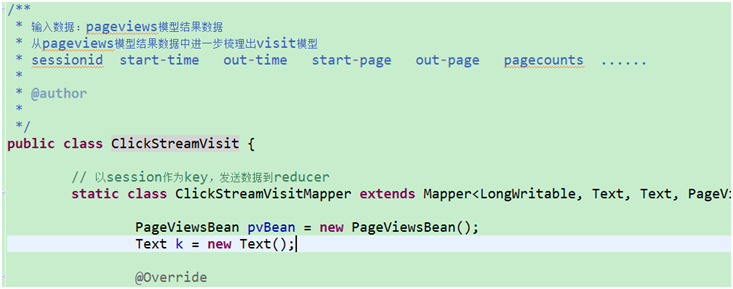
1.1. 点击流模型pageviews表
Pageviews表模型数据生成, 详细见:ClickStreamPageView.java
此时程序的输入数据源就是上一步骤我们预处理完的数据。经过此不处理完成之后的数据格式为:

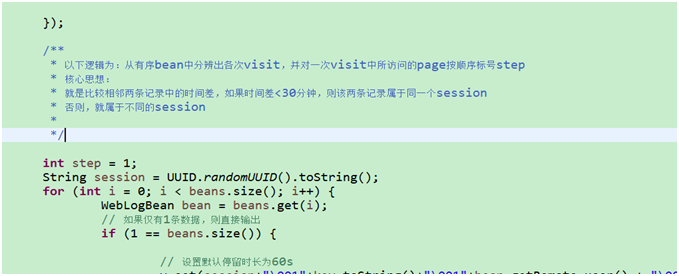
1.2. 点击流模型visit信息表
注:“一次访问”=“N次连续请求”
直接从原始数据中用hql语法得出每个人的“次”访问信息比较困难,可先用mapreduce程序分析原始数据得出“次”信息数据,然后再用hql进行更多维度统计
用MR程序从pageviews数据中,梳理出每一次visit的起止时间、页面信息
详细代码见工程:ClickStreamVisit.java
===================================================================
课程总结:
1、日志采集框架flume
flume是干什么的???采集数据的
flume里面的核心组件:
source:数据源,对接我们的数据源进行获取数据
channel:管道 连接source与sink 主要作为数据组件的连接以及数据的缓冲区
sink:数据下沉的组件,主要是用于定义我们的数据的目的地
event:flume的运行的实例 event里面包含了我们采集到的数据
flume的数据采集:
第一个:采集监控一个文件 搞定
第二个:采集监控一个文件夹 搞定
flume的failover 高可用机制 了解
flume的load_balancer 负载均衡 了解
flume的拦截器 了解
数据的调度:azkaban
two server mode 的模式的安装 搞定
azkaban的调度:调度shell脚本 调度hive任务 调度 mr的任务 执行hdfs的任务 搞定
azkaban的定时任务 搞定
sqoop数据迁移:
数据导入:关系型数据库到大数据平台
数据导出:大数据平台到关系型数据库
导入: 指定数据之间的分隔符,指定数据的导入目的地 搞定
导入:导入到hive表 尽量搞定
导出:导出到mysql 搞定
java 执行shell命令 搞定
网站日志分析:
网站分析的指标
网站的预处理代码 跑通,看懂


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









