






 本文探讨了AI团队中数据处理工程师的重要性,介绍了从顶层设计数据处理框架的方法,以及Apache Spark和Apache Beam的设计原理。深入分析了Google T6级别的设计思路,前后端处理分离解耦策略,以及在大数据处理中如何实现批处理与流处理的统一。
本文探讨了AI团队中数据处理工程师的重要性,介绍了从顶层设计数据处理框架的方法,以及Apache Spark和Apache Beam的设计原理。深入分析了Google T6级别的设计思路,前后端处理分离解耦策略,以及在大数据处理中如何实现批处理与流处理的统一。
Jesse Anderson 曾做过一项研究,一个人工智能团队的合理组织架构,需要 4/5的数据处理工程师。很不幸,很多团队没有认识到这一点。为什么爱上数据处理
学会如何使用MR 从顶层设计数据处理框架
Apache Spark 和 Apache Beam 为什么这么设计
Google T6 级别设计

前后端处理分离解耦,前批处理+有向图编译,后端为有向图优化+自动资源分配+自动监控/错误跟踪
寻找集群中的tok(K) 销量任务
首先我们忘掉所有的框架,我们想做的业务设计其实是就是一个count() 一个topK()google 处理框架 - Google Level Platform
衡量指标很简单是sla
工程一致性模型,强一致性,弱一致性,最终一致性
Cloud Spanner 就是强一致性,业务级的数据引擎workflow 设计模式
'''
复制 过滤 分离 合并
'''
数据处理非实时响应
可以使用发布订阅,进行解耦 削峰cap
c 线性一致性 分布式系统操作就像单机一样
a 可用性 只要不是所有节点都挂了,数据一定要返回响应
p 分区容错 ,就是数据不能仅仅存在一个节点上
存储架构使用的cp 系统 Google BigTable, Hbase, MongoDB
Ap 系统 amazon dynamo 数据系统
kafka 属于ca 系统
大数据之 lamdba architecture 架构
批处理层 速度处理层 服务层
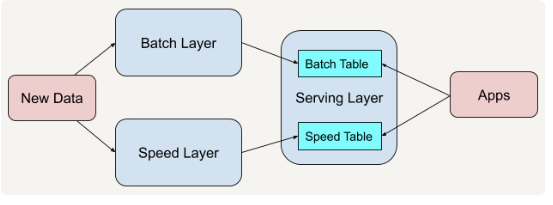大数据之 kappa 架构

spark
spark 不只能依赖于hadoop 才能使用,还可以运行在apache mesos ,kubernetes ,standalone
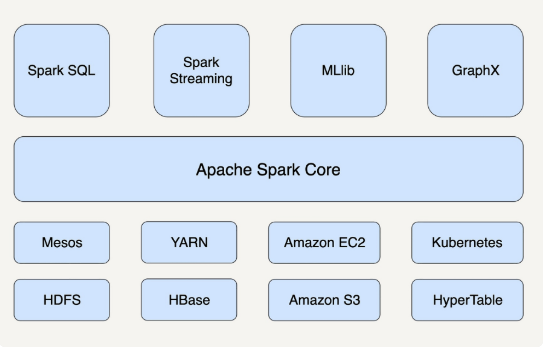
平行等级设备 spark storm presto impalaflink
flink 数据结构是 stream ,基于条数据进行使用的数据这个技术打破那些痛点

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









