 大型网站架构演进
大型网站架构演进




1 大型网站定义
- 海量的数据;
- 高并发的访问量。
3 演进
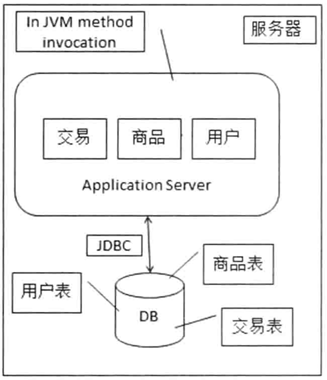
3.1 单机网站
各功能模块之间通过JVM内部的方法调用进行交互,应用和数据库之间通过JDBC进行访问。
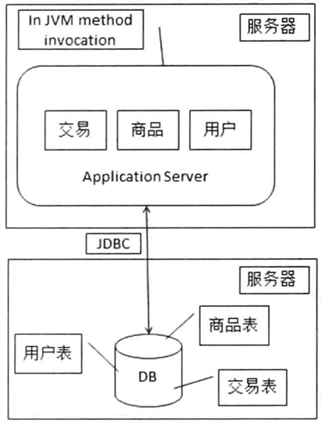
3.2 数据库与应用分离
使用单独的数据库服务器,仍使用JDBC访问数据库。
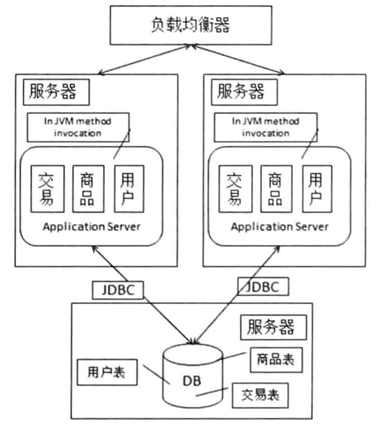
3.3 应用服务器集群
使用DNS或者负载均衡器给服务器分配请求。
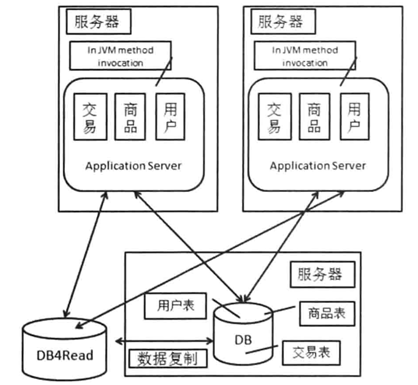
3.4 数据库读写分离
使用主库负责写,读库负责读。问题:
- 数据复制(延迟);
- 应用对于数据源的选择。
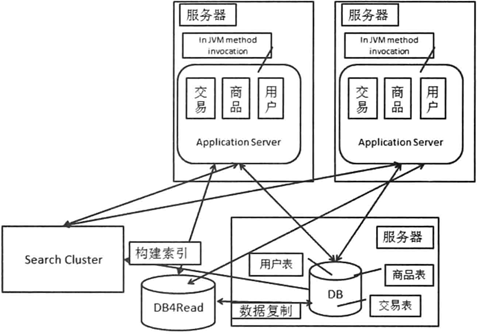
3.5 使用搜索引擎进行全文检索
大型网站常需要进行站内搜索,因此需要实现搜索引擎。要根据被搜索的数据建立索引,使用搜索集群存放索引。
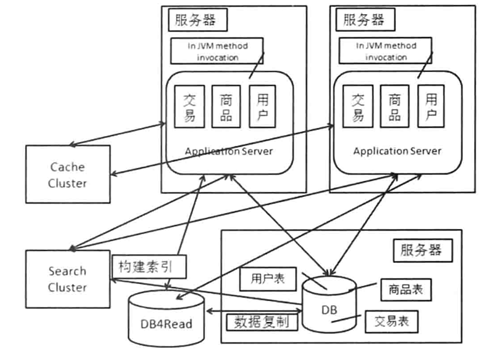
3.6 缓存
-
数据缓存
缓存常用数据,加快响应。
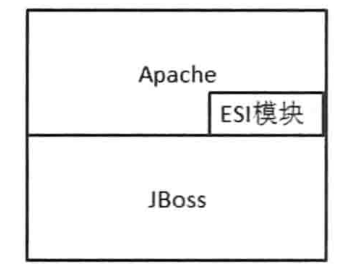
-
页面缓存
缓存常用页面,使用ESI规范。
3.7 使用分布式存储
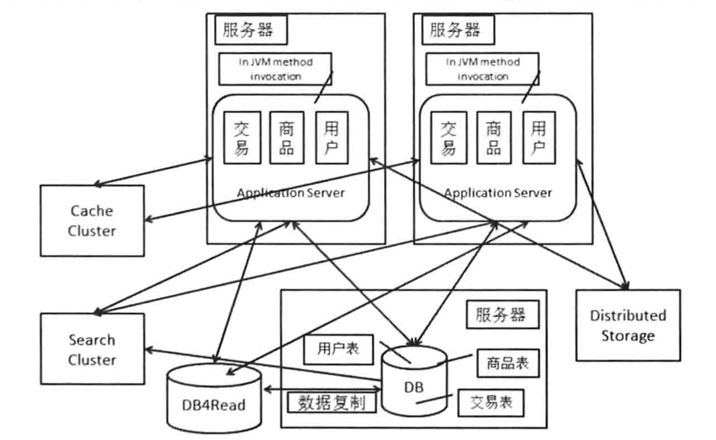
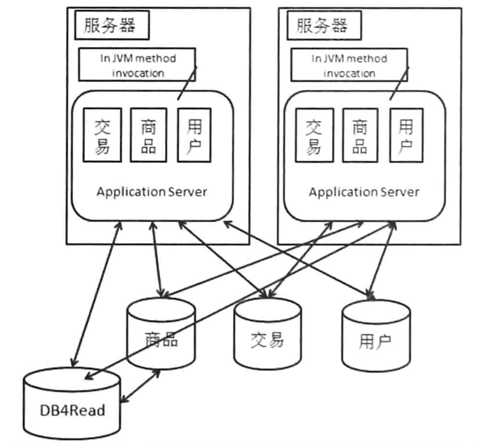
3.8 拆分数据库
-
垂直拆分
根据数据库中不用的业务数据拆分到不同的数据库中。需要使用分布式事务,或者减少事务的使用。
-
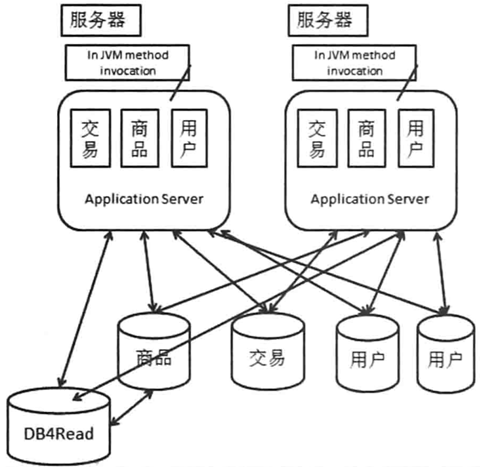
水平拆分
当某个表的数据量过大时,把同一个表的数据拆到两个数据库中。
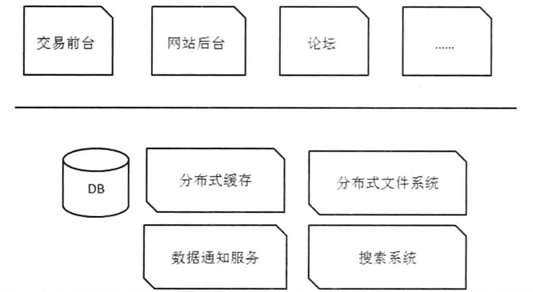
3.9 拆分应用
根据业务拆分应用。
3.10 服务化
分成三层:
- 完成不同业务功能的Web系统;
- 处于中间的服务中心;
- 处于下层的数据库。
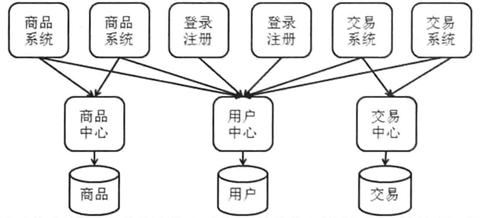
变化:
- 业务功能之间的访问需要使用远程的服务调用;
- 共享的代码集中在服务中心;
- 上层业务服务器负责与浏览器交互,中层服务中心负责业务逻辑、与数据库交互;
- 可以让不同的团队专门负责不同层的服务器。
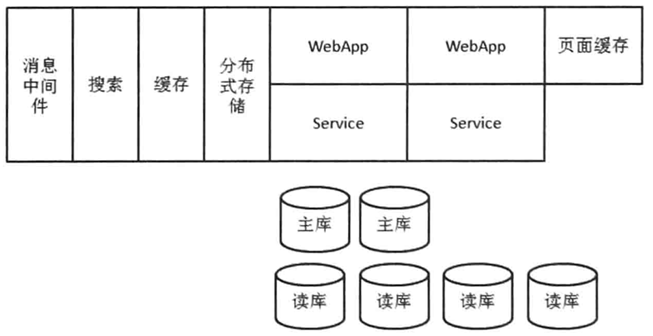
3.11 总结
2 分布式系统的Session管理
2.1 Session Sticky
负债均衡器根据每次请求的会话标志选择服务器,保证同一会话由同一个服务器来处理。
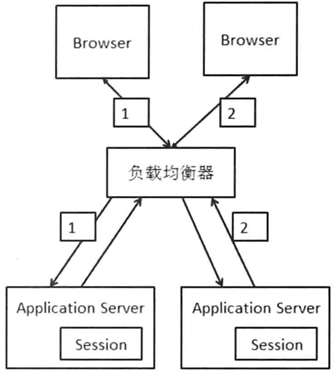
问题:
- 如果服务器宕机或重启,那么这台机器上的会话数据会消失;
- 会话标志是应用层信息,需要进行应用层(第7层)的解析,这个开销比第4层大;
- 负载均衡器需要保存会话映射,内存消耗较大。
2.2 Session Replication
在服务器之间增加会话数据的同步,通过同步保证不同web服务器之间的session数据的一致。
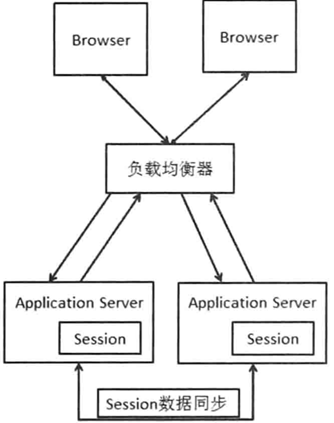
问题:
- 同步session数据造成网络带宽的开销;
- 每台服务器都要保存session数据。
2.3 Session数据集中存储
集中存储session数据,每台服务器都从集中存储获取session数据,再将修改写会集中存储。
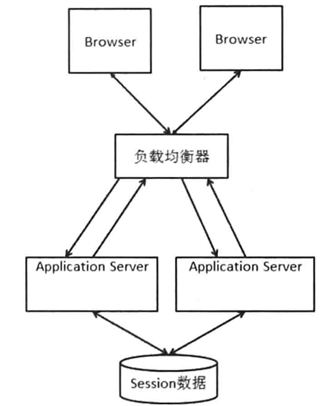
问题:
- 读写session数据引入了网络操作,存在时延和不稳定性;
- 集中存储可能出现问题。
2.4 Cookie Based
使用cookie保存会话数据。
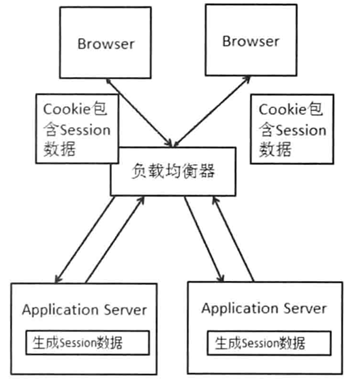
问题:
- cookie长度有限;
- cookie传数据不安全;
- 带宽消耗,请求数据量变大;
- 性能影响,响应的数据越大,响应越慢。

















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









