



 这篇博客主要介绍了数据分析中处理数据缺失值和异常值的方法,包括用均值填充数值型缺失值、使用pd.cut和pd.qcut进行数据分箱,以及如何转换类别变量。还探讨了不同类型的DataFrame数据、NAN处理、筛选特定数据的方法,以及分位数计算。此外,讨论了groupby操作和数据拼接的多种方式。
这篇博客主要介绍了数据分析中处理数据缺失值和异常值的方法,包括用均值填充数值型缺失值、使用pd.cut和pd.qcut进行数据分箱,以及如何转换类别变量。还探讨了不同类型的DataFrame数据、NAN处理、筛选特定数据的方法,以及分位数计算。此外,讨论了groupby操作和数据拼接的多种方式。
学习到了数据缺失值、异常值的处理
例子中Age列为数值型,可以考虑用均值填充。Cabin缺失值较多应该填充,Embarked缺失值只有2个,可以考虑dropna删除掉。
几种填充的做法
df[df['Age']==None]=0
df[df['Age'].isnull()] = 0
df[df['Age'] == np.nan] = 0
特征可以被分为数值(离散型、连续型)、文本(类别、描述字符串),数值型一般可以直接用来训练,但进行分箱操作可以离散化会更稳定。文本型往往需要转换成数值型特征。
分箱用pd.cut()可以做到按照值均分或者自定义数值区间来区分,用pd.qcut()可以做到用百分数来区分
用value_counts可以很方便地查看类别变量名的种类以及数量
df['Sex'].unique()看种类名称,df['Sex'].nunique()看种类数量
类别文本转换可以用replace或者map,写法略有区别。
df['Sex_num'] = df['Sex'].replace(['male','female'] ,[1,2])可以用参数inplace=True则替换原来的值
df['Sex_num'] = df['Sex'].map({'male':1},{'female':2})
‘Cabin’有147种,我写了个比较长的
df['Cabin_num'] = df['Cabin'].replace(df['Cabin'].dropna().unique().tolist(),[i for i in range(1,df['Cabin'].dropna().nunique()+1,1)])
还可以调包运用sklearn.processing中的LabelEncoder,其给各种标签非配一个可数的连续编号
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Ticket']:
lbl = LabelEncoder()
label_dict = dict(zip(df[feat].unique(), range(df[feat].nunique())))
df[feat + '_labelEncode'] = df[feat].map(label_dict)
df[feat + '_labelEncode1'] = lbl.fit_transform(df[feat].astype(str))两种是不一样的,map这种会从0开始,fit_transform好像有其他的变换规则
其中dict(zip())可以把两个列表合并成字典,例如
>>> keys = ['a', 'b', 'c']
>>> values = [1, 2, 3]
>>> dictionary = dict(zip(keys, values))
>>> print(dictionary)
{'a': 1, 'b': 2, 'c': 3}------
阶段性提问:
1. 观察DataFrame数据类型,可以分为哪些类型?
object、int、float、str、category、bool datatime64
2. 数据文件的NAN/NULL数据读取为DataFrame后最终会变为哪种数据?
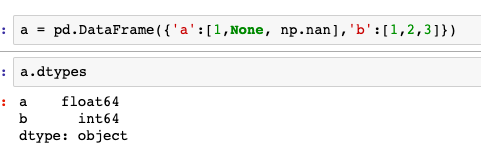
3. 如何筛选姓名中含有"Mr."的数据出来?
Series.str.extract(),括号中写正则表达式
如果只是筛选包含mr.的数据可以用str.contains
4. 如何查看数据中的95%分位数?
可以用pandas中的quantile(0.95) 或者numpy中的np.percentile(· ,0.95)
或者用.describe(percentiles=[.95]) 后面学到分组聚合的时候跟这个内容也可以结合
5. 关于缺失值部分:
df[df['Age']==None]=0 # 不推荐
df[df['Age'] == np.nan] = 0 # 不推荐
df[df['Age'].isnull()] = 0 # 还好
df['Age'] = df['Age'].fillna(0) # 推荐
你能说说原因吗?
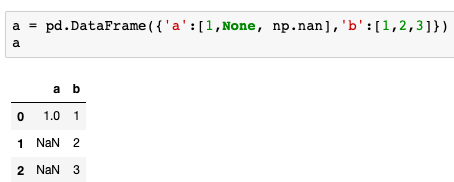
a['a']==None 和 a['a']==np.nan都是False,而isnull可以查出来,比较稳妥。
6.对DataFrame进行groupby操作的时候,如果groupby的某列里有空值,结果会默认删除空值,故要先进行异常值处理。
二.拼接数据的时候,可以用concat、Dataframe自带的join、append以及pandas的merge办法。
用join和append例子:join是左右连接
result_up = text_left_up.join(text_right_up)
result_down = text_left_down.join(text_right_down)
用merge的例子
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result = resul_up.append(result_down)
result.head()
stack()可以将dataframe转换成series类型的数据。
三.
无论你准备拿groupby做什么,都有可能会用到GroupBy的size方法
任何分组关键词中的缺失值,都会被从结果中除去。groupby之后得到的对象包含了所有后续进一步处理所需要的信息,mean(), sum()都可以用agg()来做,agg()还可以传入自定义的函数
https://finthon.com/pandas-agg/
.copy()是深拷贝,改变原dataframe不会改变深拷贝对象的数据。
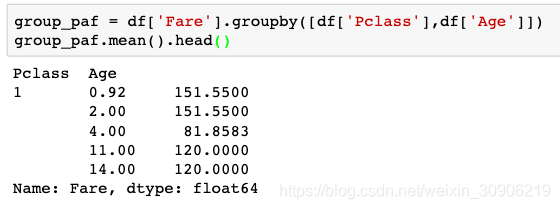
为什么年龄也看起来被求平均了?

这个报错了,都把我报饿了。
group_ss = df['Survived'].groupby(df['Sex'])
#group_ss = df.grouby('Sex‘)['Survived']
我想得也太复杂了,明明一行就能整出来的事儿
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
groupby中的count()和value_counts()区别,前者返回非空值行数、后者统计种类数量
https://blog.youkuaiyun.com/u011675334/article/details/102368626
第二单元的第四节可视化的任务5,6,7可以多做几次。

















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









