



 本文介绍了 XPathExtractor 如何使用 XPath 表达式在 XML 文档中查找特定元素的方法。通过示例展示了如何利用 XPath 的过滤符如 ‘//’ 来定位任意位置的节点,并结合 getSupportProvinceResult 和 string 节点进行具体操作。
本文介绍了 XPathExtractor 如何使用 XPath 表达式在 XML 文档中查找特定元素的方法。通过示例展示了如何利用 XPath 的过滤符如 ‘//’ 来定位任意位置的节点,并结合 getSupportProvinceResult 和 string 节点进行具体操作。
使用场景:Xpath Extractor 利用Xpath在xml中查找元素
如何查找:xpath query中的表达式即是过滤符,‘//’表示选择任意位置的某个节点,其次是getSupportProvinceResult节点,再者是string节点
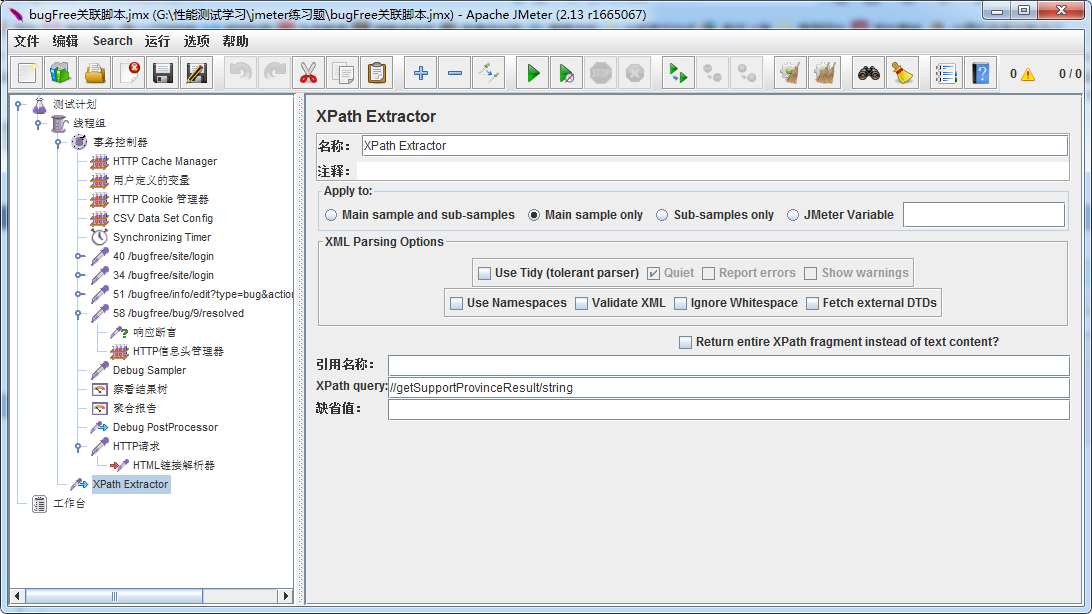
使用场景:Xpath Extractor 利用Xpath在xml中查找元素
如何查找:xpath query中的表达式即是过滤符,‘//’表示选择任意位置的某个节点,其次是getSupportProvinceResult节点,再者是string节点
转载于:https://www.cnblogs.com/lcosima/p/7203391.html
 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























