






 本文详细介绍了如何使用Python的configparser模块进行配置文件的创建、读取、修改和删除,以及random模块的各种随机数生成函数的用法。
本文详细介绍了如何使用Python的configparser模块进行配置文件的创建、读取、修改和删除,以及random模块的各种随机数生成函数的用法。
目录结构:
bin:存放程序入口,程序启动文件。
conf:存放配置文件,配置文件主要是一些全局变量,路径信息等。
core:程序核心文件,不涉及到业务逻辑。
app:存放和系统业务相关的逻辑。
db:存放系统运行所需的数据文件。
lib:存放公共组件。
log:存放日志文件。
README:软件说明文档。
README:
1、软件名称,软件的基本功能,应用范围。
2、软件运行环境,安装方法,启动方式等。
3、软件简要的使用说明(常用操作)。
4、代码目录结构说明,详细介绍各模块的功能及组织关系。
5、用于用户提交BUG,建议的邮箱。
configparser 配置文件:
configparser文件由section组成,每个section下有自己独立的内容。
1、创建配置文件,并写入内容。
import configparser conf = configparser.ConfigParser() # 创建一个配置文件对象 conf["DEFAULT"] = { # 将内容写入conf对象中 "IP":"127.0.0.1", "NETMASK":"255.255.255.0", "PORT:":"8080" } conf["USER"] = { # 将内容写入conf对象中 "IP":"192.168.1.1", "NETMASK":"255.255.255.0", "GATEWAY":"192.168.1.255", "PORT":"8088" } file_write = open("service.ini",mode="a") conf.write(file_write) # 将对象中的内容写入文件 file_write.close()
内容如下:
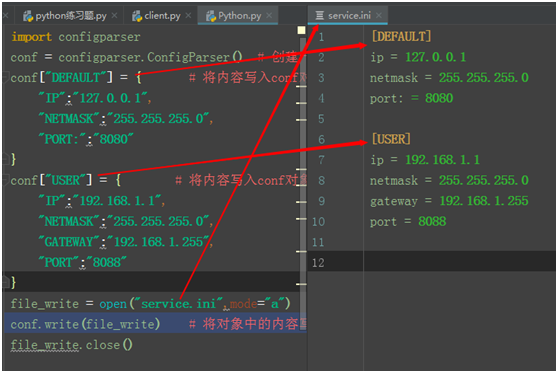
configparse:对象类似于字典,可以向字典一样操作对象。
2、读取配置文件:
import configparser conf = configparser.ConfigParser() # 创建一个配置文件对象 conf.read("service.ini") # 一定要先读出来,然后才能操作 print(conf["DEFAULT"]["IP"], conf["DEFAULT"]["NETMASK"], conf["DEFAULT"]["PORT"]) print(conf["USER"]["IP"], conf["USER"]["NETMASK"], conf["USER"]["PORT"]) # 打印内容如下 127.0.0.1 255.255.255.0 = 8080 192.168.1.1 255.255.255.0 8088
3、使用for循环打印配置文件。
import configparser conf = configparser.ConfigParser() # 创建一个配置文件对象 conf.read("service.ini") # 一定要先读出来,然后才能操作 for k in conf: # 通过循环打印配置文件所有内容 print(k,conf.items(k)) # 打印内容如下 DEFAULT [('ip', '127.0.0.1'), ('netmask', '255.255.255.0'), ('port', '= 8080')] USER [('ip', '192.168.1.1'), ('netmask', '255.255.255.0'), ('port', '8088'), ('gateway', '192.168.1.255')]
4、修改配置文件。
修改配置文件后,一定要重新将数据写入文件,因为此时的数据是在内存当中,并没有写入文件,所以下次打开文件时,文件内容并没有被修改。如下操作:
import configparser conf = configparser.ConfigParser() # 创建一个配置文件对象 conf.read("service.ini") # 一定要先读出来,然后才能操作 conf["DEFAULT"]["IP"] = "192.168.1.110" # 修改DEFAULT节下IP的内容 conf.write(open("service.ini",mode="w"))# 修改内容后一定要重新写入文件 print(conf["DEFAULT"]["IP"]) # 打印内容如下 192.168.1.110
查看文件是否被修改:

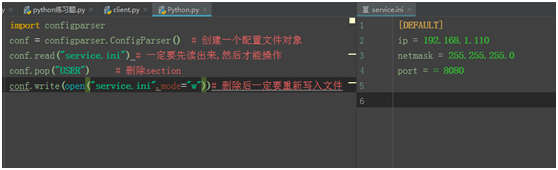
5、删除配置文件内容:默认配置文件DEFAULT是不允许删除的。
import configparser conf = configparser.ConfigParser() # 创建一个配置文件对象 conf.read("service.ini") # 一定要先读出来,然后才能操作 conf.pop("USER") # 删除section conf.write(open("service.ini",mode="w"))# 删除后一定要重新写入文件
删除后的内容如下:USER字节被删除。
random模块:
randrange(start, stop[, step]):
这个函数可以理解是从range(start, stop[, step])范围内随机返回一个数。
randint(a, b):
随机返回一个整数围在a <= N <= b
random.choice(seq):
从一个非空的序列中,随机返回一个元素。
random.choices(seq,k):
从一个非空的序列中,随机返回k个元素的列表
random.shuffle(x[, random]):
对可迭代对象随机排序,前提是可跌对象必须是可以被更改的,如列表,集合等不能是字符串或者是元组等不可变数据类型。
random.sample(population, k):
population参数是一个序列,或者是一个集合,参数k是要返回元素的数目,返回类型列表。
random.random():
返回一个0.0-1.0内的随机小数.
random.uniform(a,b):
随机返回一个a和b之间的小数。

















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









