






 本文探讨了在系统重构过程中常见的过度设计问题,分析了一个OA系统的案例,指出过度设计往往脱离实际业务场景,增加了不必要的复杂性和成本。
本文探讨了在系统重构过程中常见的过度设计问题,分析了一个OA系统的案例,指出过度设计往往脱离实际业务场景,增加了不必要的复杂性和成本。
这个系列是 坑 系列,会说一些在系统设计,系统架构上的 坑 ,这些都是我想到哪说到哪,有像这篇一样比较宏观的 坑 ,后面的文章也会有到具体技术细节的(比如某个函数,某个系统调用) 坑 ,总之,到处都是坑,这些坑有些是我经历过的,有些是听说的,你也可以留言说说你遇到的 坑 。 这一篇,我们从 重构 这个场景来看看系统架构的设计中 过度设计 这个坑。 首先,我们这里说的重构,和《重构:改善既有代码的设计》这本书中的重构不太一样,这是本好书,他主要说的是代码级别的重构,这种重构是需要在编码的时候时时刻刻进行的,更多的是一种编程思想的训练,而我们这篇的 重构 主要是说系统设计的 重构 。
0. 关于架构师
在说之前先聊聊架构师这个职位吧,这个职位最近两年特别特别火,哪个公司没个架构师好像都不好意思跟人打招呼,各位架构师打上这个标签后头上就顶了一个光环了,本人也认识各个公司的一些架构师,我认识的架构师分成几种:
-
系统架构师,这种技术能力是最强的,这也是一般人眼中的架构师了,这种架构师一般属于领域架构师,对某个领域的技术有比较深入的了解
-
业务架构师,我只是用了这个名字而已啊,有些地方的业务架构师其实和上面的系统架构师没什么两样,但有些业务架构师有些脱离了技术了,基本上变成了一个项目经理的角色,各种沟通,我觉得不应该算架构师了。
-
PPT架构师,这个顾名思义,这是"最高级"的架构师了,只要PPT做得酷炫就OK了,这是我等达不到的程度,呵呵呵呵。
最近还有一种说法就是架构师到底要不要会写代码?我的理解是 没什么可说的,必须要会写啊 ,你一个架构师,代码都不会写还架构个屁啊,就算你是PPT架构师,没时间写代码,但出问题了抡起袖子来解BUG的能力得有吧,而且很关键的一点,架构师面对的都是一群技术宅,你连个代码都不会写,你觉得下面的技术宅会看得起你么?至少你得显得很会写吧。 为什么说架构师呢?因为大部分架构上的坑都是从一个不好的设计开始的,而现在的各个系统的设计都是由架构师来操刀的。
1. 重构中的过度设计
技术人员最喜欢做的一件事就是 重构 ,因为技术宅们都看不上别人的代码,特别是需要在别人代码上加新功能的工作更是看不上,架构师们是技术宅的升级版,所以更加看不上别人的架构设计,所以 重构 是经常做的事情,小的是功能模块的重构,大的是整个系统的重构,总之,都是 不重构不舒服斯基 。 重构本身并没有问题,但是需要看的是重构的时机,是不是应该重构了? 我们以一个例子来详细说说 重构 中的 过度设计 吧,你也可以想想要是遇到这样的系统,你是架构师,你怎么做?欢迎留言讨论。 假如有个初创公司,是帮企业做OA系统的,最开始的时候是由三个程序员小哥开发出来的,系统架构很简单,是个 AllInOne 的设计,开发语言PHP,就像下图一样。
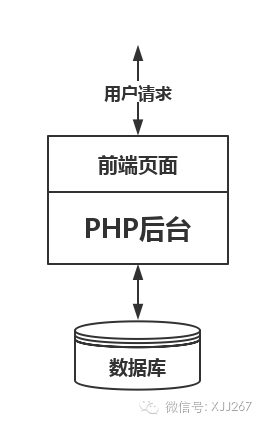
每当客户有新需求,基本的操作就是 加个表 --- 加个逻辑模块 --- 修改一下界面 --- 上线 ,而且一般OA系统是部署在客户内部的,所以每次修改都是针对单独客户进行开发。 公司发展的越来越好,有了一些大公司买了他们的OA,有钱了,请了个架构师过来优化优化技术架构,架构师叫小明(每次都黑小明),小明来了一看现有设计,我去,这怎么行?三天后,给出了他的建议
-
首先,数据层都在一个库里面,以后数据量大的话数据库效率太低了,首先要分库分表,把用户数据表和事件表横向和纵向的拆分一下,哈希到不同的机器上去,减轻单台机器的压力。
-
其次, AllInOne 的设计太臃肿了,要把各个模块 微服务 化,把 权限 模块, 附件管理 模块拆分出去成为一个微服务,提供API给其他模块使用,方便维护,后续添加新功能做一个 微服务 就行了,和其他模块的耦合性急剧降低。
-
在数据层和业务层之间加一个代理层,用个开源的中间件,以后数据端再有分库分表操作,对上层屏蔽细节,业务人员不用关心底层数据库细节,专心写业务逻辑就行了。
-
PHP性能不太行,并且界面做出来不好看,前端分离还不彻底,改成Nodejs+Angularjs来进行前后端分离,前端人员专注页面,做出更绚丽的页面来,后端人员专注业务逻辑,使用 RESTAPI 进行数据交互。
-
docker部署,每个服务启一个docker,对运维人员友好,而且有很多工具可以看各个docker的健康状况。
于是,整个系统变成下面这个样子了。
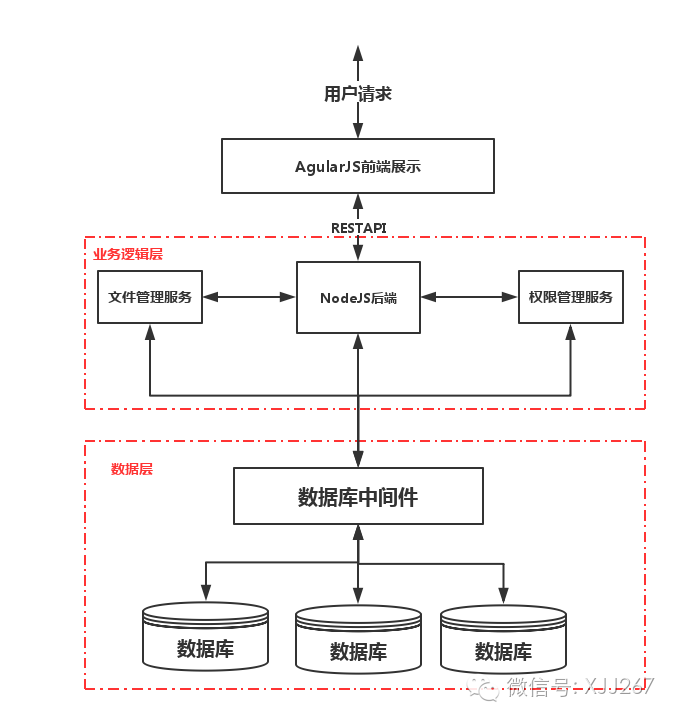
卧槽,好高大上,乍一看,这就是一个目前比较流行的架构图了,有数据层,有中间件层,有业务层,有前端展示层,数据层支持分库分表,可以无限扩展,业务层微服务化,也可以无限扩展,docker部署,一个image搞定部署,简直了!除了消息队列没有用上以外,其他的流行东西用了个遍啊。 那么,开始干吧,把人员分成两拨,一拨继续维护现有系统,接客户新需求,一拨开始重构,一个月时间,把数据和功能模块梳理了一遍,然后开始定各个服务中的接口,又用了小一个月,然后全部人员投入进去开始编码,又忙活了三个月,终于重构完成了,再花一个月时间追上这4个月新来的需求,牛逼的架构上线了! 如果小明够厉害并且开发人员也给力的话,最好的情况就是上线后一切正常,你不是重构么?客户完全感觉不到有变化,继续使用得很high。但这种概率几乎为零,最有可能的情况是什么呢?
-
客户说,卧槽,少了个功能了,卧槽,数不对了,这都是小事,新系统嘛,总归有一些问题,解决这些bug就好了。
-
某天发现登录不上了,如果在之前,跟踪一下代码就知道哪里有问题了,立刻解决了,现在已经微服务了,你说是网络问题还是权限服务问题还是逻辑问题呢?要跟踪可没那么容易。
-
某天发现数据写入和读取都有问题,最后查问题发现是开源的中间件偶尔抽风了,要修改的话,得看中间件的源码了,跪了吧。。。。
-
最关键的是,你会发现,上了这个新的架构以后,是耦合性降低了,但开发一个新功能的工作量比以前多了,效率反而降低了。
这就是一个典型的 过度设计 , 过度设计 特点:
完全脱离了业务场景来进行技术架构的设计就是过度设计 。
这个例子中的业务场景是一个OA系统,OA系统的主要数据是企业的人和人的数据,一个企业能有多少人?一个初创公司,能接入10万人的大公司做OA已经非常不错了吧?即便是10万人的大公司,人的数据也就10万条,我们在成100,算单个表1000万条数据吧,单台MySql完全可以hold得住,所以第一条分库分表的设计在这个场景下就完全没有必要,企业主最关心的是什么?是数据的安全可靠,所以你在这里把MySql换成Orecle,企业主觉得安全也会买单,并且你收入还能更多,而且换成Orecle的话,单个表上亿问题也不大,何必分库分表? 好,就算你数据量巨大,需要分库分表,那你整个中间件干嘛?中间件的作用是屏蔽底层数据没错,但还有个场景是数据读写分离,一般是在大数据量并且有高并发需求的系统使用,你一OA系统,能有多高的并发?需要用中间件这么高端的东西么? 再看看 微服务 ,为了降低系统的耦合度使用了 微服务 ,同样场景也不对,什么时候需要把服务拆分出来呢?只有在当前服务已经耗费了单台机器太多的资源了,单机扛不住了,才会把功能比较独立的模块拆分成微服务出去,因为 微服务 虽然降低了系统的耦合度,但是需要更多的考虑到系统的可用性和网络因素造成的问题,对开发人员的要求更高,一个OA系统,能有多大的计算量? 后面的前后端分离啊,docker部署啊,你想想各自的必要程度如何?一个OA是否需要绚丽的界面?一个OA系统的更新频率有多高?是否需要docker这样的东西来帮助部署?成本如何?再看看是否是 过度设计 ? 最后,我觉得上面这个系统,比较合理的修改设计是:
-
把数据库加上一个主从同步,保证数据的可靠性,别数据库挂了,那客户可会跟你拼命,这是最重要的。
-
把系统的SQL语句梳理一遍,看看有没有什么慢SQL,然后做针对性的优化,比如加索引,改SQL之类的。
-
把后端的服务加上详细的Log信息,这样出了问题也好查问题,并且可以把Log收集起来做分析,看看系统的瓶颈在什么地方,然后再在局部做优化也好重构也好,这样对系统的侵入性最小。
这样下来,系统的性能应该有提升,数据可靠性也增强了,并且也耗费不了多少资源,通过Log分析,一个局部一个局部的优化,直到发现了一个大坑需要拆分服务了,再进行服务的拆分,如果你有更好的建议,欢迎留言讨论啊。
2. 重构的理由
我觉得重构得满足以下几个条件的大部分,才有重构的必要,第一个条件是必须满足的。
-
现有系统的所有功能模块和对外接口都了解得非常清楚了。如果你没把对外接口了解得非常清楚,重构完了以后外部的依赖系统必然要跟着改,那就是个无底洞了。
-
现有系统有明显的重大BUG,并且在现有条件下无法解决或者很难解决。如果仅仅是系统有BUG,那么解决BUG就好了,完全没有必要为了BUG来重构,只有当确实BUG已经无法解决或者解决的成本实在太高了,才有重构的必要。
-
文档缺失或者维护人员大量离职导致目前系统的可维护性降低,很难添加新功能。如果大家都很熟悉现有系统,可以很快的在上面迭代新功能,你重新来一个系统干什么呢?
-
现有系统在可预见的未来无法支撑业务的发展了。只有当业务部门已经跑到了技术部门前面了,可以预见得到业务发展的方向了,再来审视目前的系统,发现已经无法继续支撑了,这时候才需要重构现有系统。
而重构最忌讳的用以下理由来重构系统
-
现有代码太臃肿,实现不完美。难道你重新实现一个就完美了?
-
这个系统的技术栈太陈旧,没有使用最新的技术流,以后肯定会落伍。难道用了新技术就不会落伍?
-
现有系统没有考虑高可用的情况,要是出问题了就是大问题。
-
这个语言就不适合做这个系统,得用XXX语言来实现。虽然说每个语言都有他擅长的场景,但是一个既有系统更换实现语言,是一件成本非常高的事情。
总而言之,重构一个系统最需要考虑的就一个词: 成本 ,需要衡量各方面的成本后,再考虑是否需要重构,这样的重构才是有意义的重构。 OK,这一篇简单的说了一下重构场景下的过度设计的问题,后面还会有和过度设计相关的,你也可以说说你遇到的过度设计,欢迎留言给我哈。

















 170万+
170万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









