



数据库概述
数据库(DataBase,DB):指长期保存在计算机的存储设备上,按照一定规则组织起来,可以被各种用户或应用共享的数据集合;
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中的数据。
常见的数据库管理系统:oracle,DB2,SQL Server,PostgreSQL,MySQL
SQL概述
- SQL:Structure Query Language。(结构化查询语言)
- SQL被美国国家标准局(ANSI)确定为关系型数据库语言的美国标准,后来被国际化标准组织(ISO)采纳为关系数据库语言的国际标准。
SQL语句分类
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等; CREATE、 ALTER、DROP
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据); INSERT、 UPDATE、 DELETE
DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;Show create database mydb2;查看前面创建的mydb2数据库的定义信息
Drop database mydb3; #删除数据库
select database();#查看当前使用的数据库
use mydb2;#切换数据库
```DQL(Data Query Language):数据查询语言,用来查询记录(数据); SELECT
注意:sql语句以;结尾
DDL:操作数据库、表、列等(使用的关键字:CREATE、 ALTER、 DROP)
create database mydb1; #创建数据库 show databases; #查看当前数据库服务器中的所有数据库create table 表名(
字段1 字段类型,
字段2 字段类型,
...
字段n 字段类型
); #创建表```
常用数据类型:
int:整型
double:浮点型,例如double(5,2)表示最多5位,其中必须有2位小数,即最大值为999.99;
char:固定长度字符串类型; char(10) 'abc '
varchar:可变长度字符串类型;varchar(10) 'abc'
text:字符串类型;
blob:字节类型;
date:日期类型,格式为:yyyy-MM-dd;
time:时间类型,格式为:hh:mm:ss
timestamp:时间戳类型 yyyy-MM-dd hh:mm:ss 会自动赋值
datetime:日期时间类型 yyyy-MM-dd hh:mm:ssSHOW TABLES; #显示当前数据库中的所有表 ALTER TABLE employee ADD image blob; #在employee表中增加一个image列 ALTER TABLE employee MODIFY job varchar(60); #修改job列,使其长度为60 ALTER TABLE employee DROP image; #删除image列,一次只能删一列 RENAME TABLE employee TO user; # 表名改为user SHOW CREATE TABLE user; #查看表格的创建细节 ALTER TABLE user CHANGE name username varchar(100); #列名name修改为username DROP TABLE user; #删除表
DML操作(重要)
- DML是对表中的数据进行增、删、改的操作。不要与DDL混淆了
小知识:
在mysql中,字符串类型和日期类型都要用单引号括起来。'tom' '2015-09-04' 空值:nullINSERT INTO 表名(列名1,列名2 ...)VALUES(列值1,列值2...); #向表中插入数据注意:列名与列值的类型、个数、顺序要一一对应。
可以把列名当做java中的形参,把列值当做实参。
值不要超出列定义的长度。
如果插入空值,请使用null
插入的日期和字符一样,都使用引号括起来.INSERT INTO emp VALUES (4,'zs','m','2015-09-01',10000,'2015-09-01',NULL), (5,'li','m','2015-09-01',10000,'2015-09-01',NULL), (6,'ww','m','2015-09-01',10000,'2015-09-01',NULL); #批量插入#将姓名为’aaa’的员工薪水修改为4000元,job改为ccc。 UPDATE emp SET salary=4000,gender='female' WHERE name='lisi';DELETE FROM emp; #删除表中所有记录。 DELETE FROM emp WHERE name=‘zs’ #删除表中名称为’zs’的记录。 TRUNCATE TABLE emp; #使用truncate删除表中记录。 #DELETE 删除表中的数据,表结构还在;删除后的数据可以找回 #TRUNCATE 删除是把表直接DROP掉,然后再创建一个同样的新表。删除的数据不能找回。执行速度比DELETE快。
DQL操作
- DQL数据查询语言 (重要)
数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。查询返回的结果集是一张虚拟表. 语法:
SELECT selection_list 要查询的列名称
FROM table_list 要查询的表名称
WHERE condition 行条件
GROUP BY grouping_columns 对结果分组
HAVING condition 分组后的行条件
ORDER BY sorting_columns 对结果分组
LIMIT offset_start, row_count 结果限定SELECT * FROM stu; #查询所有列 SELECT sid, sname, age FROM stu; #查询指定列条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
=、!=、<>、<、<=、>、>=;
BETWEEN…AND;
IN(set);
IS NULL; IS NOT NULL
AND;
OR;
NOT;SELECT * FROM stu WHERE gender='female' AND ge<50; #查询性别为女,并且年龄50的记录 SELECT * FROM stu WHERE sid ='S_1001' OR sname='liSi'; #查询学号为S_1001,或者姓名为liSi的记录 SELECT * FROM stu WHERE sid IN ('S_1001','S_1002','S_1003');#查询学号为S_1001,S_1002,S_1003的记录 SELECT * FROM tab_student WHERE s_number NOT IN ('S_1001','S_1002','S_1003');#查询学号不是S_1001,S_1002,S_1003的记录 SELECT * FROM stuWHERE age IS NULL; #查询年龄为null的记录 SELECT * FROM stuWHERE age>=20 AND age<=40; SELECT * FROM stu WHERE age BETWEEN 20 AND 40; #查询年龄在20到40之间的学生记录 SELECT * FROM stu WHERE gender!='male';#查询性别非男的学生记录模糊查询
当想查询姓名中包含a字母的学生时就需要使用模糊查询了。模糊查询需要使用关键字LIKE
通配符:
_ 任意一个字符
%:任意0~n个字符SELECT * FROM stu WHERE sname LIKE '_____';#查询姓名由5个字母构成的学生记录 SELECT * FROM stu WHERE sname LIKE '____i';#查询姓名由5个字母构成,并且第5个字母为“i”的学生记录 SELECT * FROM stu WHERE sname LIKE 'z%';#查询姓名以“z”开头的学生记录 SELECT * FROM stu WHERE sname LIKE '_i%';#查询姓名中第2个字母为“i”的学生记录 SELECT * FROM stu WHERE sname LIKE '%a%';#查询姓名中包含“a”字母的学生记录- 字段控制查询
SELECT DISTINCT sal FROM emp; #查询sal不重复的记录 SELECT *,sal+comm FROM emp; #查看雇员的月薪与佣金之和 SELECT *,sal+IFNULL(comm,0) FROM emp;# 把NULL转换成数值0的函数IFNULL SELECT *, sal+IFNULL(comm,0) AS total FROM emp; #给列名添加别名 SELECT *,sal+IFNULL(comm,0) total FROM emp;#给列起别名时,是可以省略AS关键字的 排序 order by 列名 asc(默认) desc
SELECT * FROM stu ORDER BY sage ASC; #查询所有学生记录,按年龄升序排序 SELECT * FROM stu ORDER BY sage; SELECT *FROM stu ORDER BY age DESC;#查询所有学生记录,按年龄降序排序 SELECT * FROM emp ORDER BY sal DESC,empno ASC;#查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序聚合函数 sum avg max min count
聚合函数是用来做纵向运算的函数:
COUNT():统计指定列不为NULL的记录行数;
MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;SELECT COUNT(*) AS cnt FROM emp;#查询emp表中记录数, 得到的列记为cnt SELECT COUNT(comm) cnt FROM emp; #查询emp表中有佣金的人数 SELECT COUNT(*) FROM emp WHERE sal > 2500;# 查询emp表中月薪大于2500的人数 SELECT COUNT(*) AS cnt FROM emp WHERE sal+IFNULL(comm,0) > 2500; #统计月薪与佣金之和大于2500元的人数 SELECT COUNT(comm), COUNT(mgr) FROM emp;#查询有佣金的人数,有领导的人数 SELECT SUM(sal) FROM emp; #查询所有雇员月薪和 SELECT SUM(sal), SUM(comm) FROM emp; # 查询所有雇员月薪和,以及所有雇员佣金和 SELECT SUM(sal+IFNULL(comm,0)) FROM emp; #查询所有雇员月薪+佣金和 SELECT AVG(sal) FROM emp;统计所有员工平均工资 SELECT MAX(sal), MIN(sal) FROM emp;#查询最高工资和最低工资分组查询
当需要分组查询时需要使用GROUP BY子句,例如查询每个部门的工资和,这说明要使用部门来分组。 凡和聚合函数同时出现的列名,一定要写在group by 之后SELECT deptno, SUM(sal)FROM emp GROUP BY deptno; #查询每个部门的部门编号和每个部门的工资和 SELECT deptno,COUNT(*)FROM emp GROUP BY deptno; #查询每个部门的部门编号以及每个部门的人数 SELECT deptno,COUNT(*)FROM emp WHERE sal>1500 GROUP BY deptno; 查询每个部门的部门编号以及每个部门工资大于1500的人数 SELECT deptno, SUM(sal) FROM empGROUP BY deptno HAVING SUM(sal) > 9000; 注:having与where的区别: 1.having是在分组后对数据进行过滤. where是在分组前对数据进行过滤 2.having后面可以使用聚合函数(统计函数) where后面不可以使用聚合函数。 SELECT NAME FROM emp GROUP BY NAME HAVING MIN(score)>=80; #所有科目成绩都大于80的人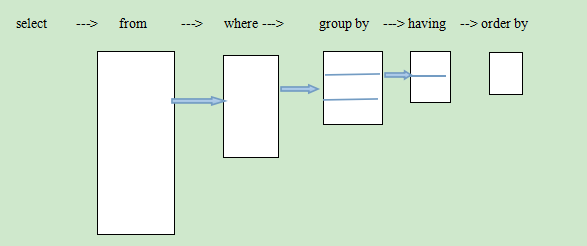
LIMIT 方言
LIMIT用来限定查询结果的起始行,以及总行数SELECT * FROM emp LIMIT 0, 5; #查询5行记录,起始行从0开始,注意,起始行从0开始,即第一行开始! SELECT * FROM emp LIMIT 3, 10;#查询10行记录,起始行从3开始查询代码的书写顺序和执行顺序
查询语句书写顺序:select – from- where- group by- having- order by-limit
查询语句执行顺序:from - where -group by - having - select - order by-limit
数据的完整性
- 作用:保证用户输入的数据保存到数据库中是正确的。
确保数据的完整性 = 在创建表时给表中添加约束;
完整性的分类:实体完整性,域完整性,引用完整性。
实体完整性
- 实体:即表中的一行(一条记录)代表一个实体(entity)
实体完整性的作用:标识每一行数据不重复。
约束类型: 主键约束(primary key) 唯一约束(unique) 自动增长列(auto_increment)
主键约束(primary key)
注:每个表中要有一个主键。
特点:数据唯一,且不能为nullCREATE TABLE student( id int primary key, name varchar(50) );#第一种添加方式CREATE TABLE student( id int, name varchar(50), primary key(id) ); #第二种添加方式,此种方式优势在于,可以创建联合主键 CREATE TABLE student( classid int, stuid int, name varchar(50), primary key(classid,stuid) );CREATE TABLE student( id int, name varchar(50) ); ALTER TABLE student ADD PRIMARY KEY (id);#第三种添加方式唯一约束(unique)特点:数据不能重复
CREATE TABLE student( Id int primary key, Name varchar(50) unique );自动增长列(auto_increment)
CREATE TABLE student( Id int primary key auto_increment, Name varchar(50) ); #给主键添加自动增长的数值,列只能是整数类型
域完整性
- 域完整性的作用:限制此单元格的数据正确,不对照此列的其它单元格比较
域代表当前单元格
域完整性约束:数据类型 非空约束(not null) 默认值约束(default)
check约束(mysql不支持)check(sex='男' or sex='女')
- 数据类型:(数值类型、日期类型、字符串类型)
非空约束:not null
CREATE TABLE student( Id int pirmary key, Name varchar(50) not null, Sex varchar(10) );默认值约束 default
CREATE TABLE student( Id int pirmary key, Name varchar(50) not null, Sex varchar(10) default ‘男’ );
引用完整性
- 实体完整性,外键列的数据类型一定要与主键的类型一致
CREATE TABLE student( sid int pirmary key, name varchar(50) not null, sex varchar(10) default ‘男’ ); create table score( sid int, score int, sid int , # 外键列的数据类型一定要与主键的类型一致 CONSTRAINT fk_score_sid foreign key (sid) references students(sid) );
多表查询(重要)
- 多表查询有如下几种:
合并结果集;UNION 、 UNION ALL
连接查询
内连接 [INNER] JOIN ON
外连接 OUTER JOIN ON
左外连接 LEFT [OUTER] JOIN
右外连接 RIGHT [OUTER] JOIN
全外连接(MySQL不支持)FULL JOIN
自然连接 NATURAL JOIN
子查询

















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









