






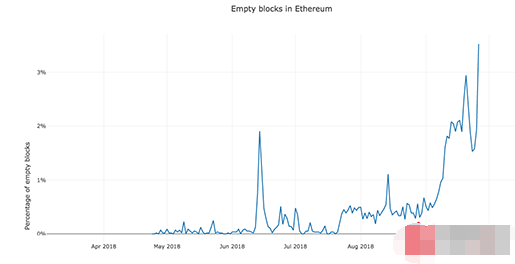
 近期,以太坊网络出现大量“空块”,矿工在未处理任何交易的情况下获得奖励,这种现象对以太坊安全构成威胁。空块的产生源于矿池使用“间谍挖矿”技术,试图在不广播空块的情况下寻找下一个区块,以获得先机。这种自私的挖矿方式导致交易时间增加,Gas费用上涨,可能迫使诚实矿工转向其他代币,严重影响以太坊网络安全性。
近期,以太坊网络出现大量“空块”,矿工在未处理任何交易的情况下获得奖励,这种现象对以太坊安全构成威胁。空块的产生源于矿池使用“间谍挖矿”技术,试图在不广播空块的情况下寻找下一个区块,以获得先机。这种自私的挖矿方式导致交易时间增加,Gas费用上涨,可能迫使诚实矿工转向其他代币,严重影响以太坊网络安全性。
根据相关报道,在过去三个月中,以太坊的“空块”数量激增,这会有什么后果呢?相关专业人士表示,这可能会对以太坊的安全造成巨大威胁。

“空块”威胁以太坊安全
根据CoinFi首席数据科学家Alex Svanevik的说法,非法矿池使用的“间谍挖矿”技术使得矿工在不实际处理区块上的任何交易的情况下获得挖矿奖励。在这种情况下,就形成了“空块”。与此同时,这种自私的挖矿方式也越来越受欢迎,很多矿工试图在不将空块广播到网络的情况下寻找下一个区块,从而使他们获得先机。
AMBcrypto报道称,经过详细搜索,发现这种做法大量存在于两个矿池中: F2Pool(鱼池,目前是世界第二大采矿池)以及Etherdig。
自9月以来,开采的空区数量增加了637%|资料来源:Decryptmedia
加密爱好者Ansel Lindner在推特上说:
“以太坊营销的成功只部分与交易数量相关。需要有足够的交易量来支持这种说法,但不要太多,那样会难以保持同步。”
他进一步观察到,在君士坦丁堡硬分叉之前,以太坊开发人员最近决定将区块奖励减少到2 ETH,这让矿工开始追逐数量。
AMBcrypto的文章中称,为了尽可能扩大利润,鱼池和Etherdig开始挖掘区块而不验证任何交易(即生产空块),对以太坊造成了前所未有的威胁。数据显示空块的传播速度比正常区块链快15%,这意味着间谍矿工的总收入也增加了15%。
如果许多矿工采取这种做法,以太坊的交易时间可能会增加,并导致Gas急剧增加。此外,如果这种情况持续下去,更多诚实的矿工会停止以太坊挖矿业务并专注于其他代币,从而对以太坊的安全造成很大影响。
为何会出现“空块” ?
理解这一做法的先决条件是知道区块链中的每个区块包含不同数量的数据。矿工不一定要准确地保存那些要验证并添加到区块链中的数据。
当矿工编码一个区块的所有数据(称为哈希)时,验证发生,然后关闭区块并广播区块。此代码对于下一个区块是必不可少的。但是,在广播之前,一些矿池开始私下挖掘区块。虽然在没有先读取区块数据的情况下不可能创建哈希,但是可以在交易发生之前从已存在的哈希创建新区块。
此新区块中没有交易,但是由于交易数据中没有不规则性,不能使该区块无效。矿工们通过矿池获得哈希。
为了抢先一步,一些矿工找到了一个新的区块并试图在不向矿池广播的情况下找到下一个区块。
然而,由于以太坊还处于早期阶段,一行代码足以防止恶意蔓延,因此很快就得到了纠正。对网络核心代码进行了升级,就能使矿工停止这一行为。
由于以太坊的开发人员基数很大[接近250,000],这是一项艰巨的任务。情况可能由于以太坊巨大的开发人员数量而变得更糟,或者利用大型社区的优势来纠正系统。

















 2313
2313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









