




 本文是STM32H7初学者的重要教程,重点介绍了STM32H7的Cache机制及其对性能的影响。内容涵盖Cache配置、读写操作流程、安全隐患及解决办法,并详细解析了相关函数的使用。了解和熟练运用Cache是提升STM32H7性能的关键。
本文是STM32H7初学者的重要教程,重点介绍了STM32H7的Cache机制及其对性能的影响。内容涵盖Cache配置、读写操作流程、安全隐患及解决办法,并详细解析了相关函数的使用。了解和熟练运用Cache是提升STM32H7性能的关键。
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980
第24章 STM32H7的Cache解读(非常重要)
本章教程为大家讲解STM32H7初学过程中最重要的一个知识点Cache。Cache在STM32H7的高性能发挥中占着举足轻重的作用。所以掌握好Cache是提升STM32H7性能的关键一步。
24.1 初学者重要提示
24.2 引出问题
24.3 支持的Cache配置
24.4 四种Cache(MPU)配置的读写操作流程
24.5 面对繁冗复杂的Cache配置,推荐方式和安全隐患解决办法
24.6 Cache的相关函数
24.7 总结
24.1 初学者重要提示
- 学习本章节前,务必保证已经学习了第23章的MPU知识。
- 本章是半年的实践经验总结,非常具有参考价值,而且是入门STM32H7的必学章节。
- Cache的熟练运用需要不断的经验积累。对于初学者来说,可能无法一下子理解所有知识点,但是一定要的花时间多读几遍,随着后面章节的不断运用,认识会不断的深入。
24.2 引出问题
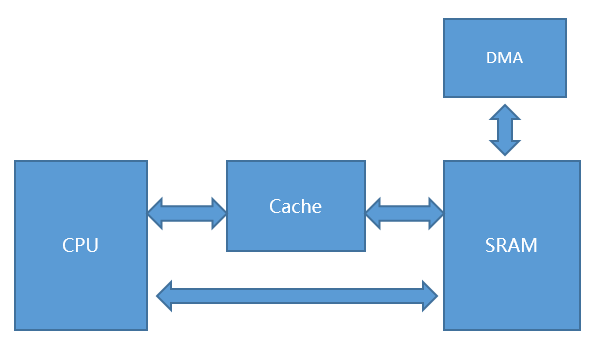
当前芯片厂商出的M7内核芯片基本都做了一级Cache支持,Cache又分数据缓存D-Cache和指令缓冲I-Cache,STM32H7的数据缓存和指令缓存大小都是16KB。对于指令缓冲,用户不用管,这里主要说的是数据缓存D-Cache。以STM32H7为例,主频是400MHz,除了TCM和Cache以400MHz工作,其它AXI SRAM,SRAM1,SRAM2等都是以200MHz工作。数据缓存D-Cache就是解决CPU加速访问SRAM。
如果每次CPU要读写SRAM区的数据,都能够在Cache里面进行,自然是最好的,实现了200MHz到400MHz的飞跃,实际是做不到的,因为数据Cache只有16KB大小,总有用完的时候。
对于使能了Cache的SRAM区,要分读写两种情况考虑。
- 读操作:
如果CPU要读取的SRAM区数据在Cache中已经加载好,这就叫读命中(Cache hit),如果Cache里面没有怎么办,这就是所谓的读Cache Miss。
- 写操作:
如果CPU要写的SRAM区数据在Cache中已经开辟了对应的区域(专业词汇叫Cache Line,以32字节为单位),这就叫写命中(Cache hit),如果Cache里面没有开辟对应的区域怎么办,这就是所谓的写Cache Miss。
24.3 支持的Cache配置
(这个知识点在上一章节进行了详细说明,这里再简述下核心内容)
Cache的配置是通过MPU来设置的,通常只用到下几种方式。
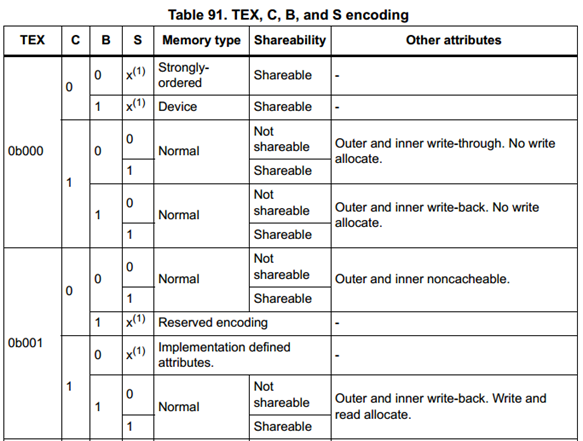
其中的TEX是用来设置Cache策略的,C是Cache,B是缓冲用来配合Cache设置的,而S是共享,用来解决多总线或者多核访问时的同步问题。MPU配置的时候,最主要的也是配置这几个参数。
Cache支持的策略有如下四种:
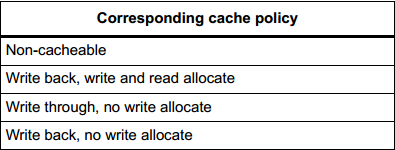
有了这四种方式,就可以正式进入本章的主题,Cache的读写操作是如何工作的,下面分这四种情况做介绍。
24.4 四种Cache(MPU)配置的读写操作流程
24.4.1 配置Non-cacheable
这个最好理解,就是正常的读写操作,无Cache。
对应四种MPU配置如下:
- TEX = 000 C=0 B=0 S=忽略此位,强制为共享
- TEX = 000 C=0 B=1 S=忽略此位,强制为共享
- TEX = 001 C=0 B=0 S=0
- TEX = 001 C=0 B=0 S=1
24.4.2 配置Write through,read allocate,no write allocate
注意,M7内核只要开启了Cache,read allocate就是开启的。
- 使能了此配置的SRAM缓冲区写操作
如果CPU要写的SRAM区数据在Cache中已经开辟了对应的区域,那么会同时写到Cache里面和SRAM里面;如果没有,就用到配置no write allocate了,意思就是CPU会直接往SRAM里面写数据,而不再需要在Cache里面开辟空间了。
在写Cache命中的情况下,这个方式的优点是Cache和SRAM的数据同步更新了,没有多总线访问造成的数据一致性问题。缺点也明显,Cache在写操作上无法有效发挥性能。
- 使能了此配置的SRAM缓冲区读操作
如果CPU要读取的SRAM区数据在Cache中已经加载好,就可以直接从Cache里面读取。如果没有,就用到配置read allocate了,意思就是在Cache里面开辟区域,将SRAM区数据加载进来,后续的操作,CPU可以直接从Cache里面读取,从而时间加速。
安全隐患,如果Cache命中的情况下,DMA写操作也更新了SRAM区的数据,CPU直接从Cache里面读取的数据就是错误的。
- 对应的两种MPU配置如下:
TEX = 000 C=1 B=0 S=1
TEX = 000 C=1 B=0 S=0
24.4.3 配置Write back,read allocate,no write allocate
注意,M7内核只要开启了Cache,read allocate就是开启的。
- 使能了此配置的SRAM缓冲区写操作
如果CPU要写的SRAM区数据在Cache中已经开辟了对应的区域,那么会写到Cache里面,而不会立即更新SRAM;如果没有,就用到配置no write allocate了,意思就是CPU会直接往SRAM里面写数据,而不再需要在Cache里面开辟空间了。
安全隐患,如果Cache命中的情况下,此时仅Cache更新了,而SRAM没有更新,那么DMA直接从SRAM里面读出来的就是错误的。
- 使能了此配置的SRAM缓冲区读操作
如果CPU要读取的SRAM区数据在Cache中已经加载好,就可以直接从Cache里面读取。如果没有,就用到配置read allocate了,意思就是在Cache里面开辟区域,将SRAM区数据加载进来,后续的操作,CPU可以直接从Cache里面读取,从而时间加速。
安全隐患,如果Cache命中的情况下,DMA写操作也更新了SRAM区的数据,CPU直接从Cache里面读取的数据就是错误的。
- 对应两种MPU配置如下:
TEX = 000 C=1 B=1 S=1
TEX = 000 C=1 B=1 S=0
24.4.4 配置Write back,read allocate,write allocate
注意,M7内核只要开启了Cache,read allocate就是开启的。
- 使能了此配置的SRAM缓冲区写操作
如果CPU要写的SRAM区数据在Cache中已经开辟了对应的区域,那么会写到Cache里面,而不会立即更新SRAM;如果没有,就用到配置write allocate了,意思就是CPU写到往SRAM里面的数据,会同步在Cache里面开辟一个空间将SRAM中写入的数据加载进来,如果此时立即读此SRAM区,那么就会有很大的速度优势。
安全隐患,如果Cache命中的情况下,此时仅Cache更新了,而SRAM没有更新,那么DMA直接从SRAM里面读出来的就是错误的。
- 使能了此配置的SRAM缓冲区读操作
如果CPU要读取的SRAM区数据在Cache中已经加载好,就可以直接从Cache里面读取。如果没有,就用到配置read allocate了,意思就是在Cache里面开辟区域,将SRAM区数据加载进来,后续的操作,CPU可以直接从Cache里面读取,从而时间加速。
安全隐患,如果Cache命中的情况下,DMA写操作也更新了SRAM区的数据,CPU直接从Cache里面读取的数据就是错误的。
这个配置被誉为可以最大程度发挥Cache性能,不过具体应用仍需具体分析。
- 对应两种MPU配置如下:
TEX = 001 C=1 B=1 S=1
TEX = 001 C=1 B=1 S=0
24.4.5 共享配置是个隐形的大坑
STM32H7编程手册对其的描述是多核共享。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1591
1591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









