



 本文探讨了近邻搜索中的维数灾难问题,并介绍了使用局部敏感哈希(LSH)来加速搜索的方法。通过将高维数据映射到多个哈希桶中,可以有效地进行精确搜索。此外,还讨论了不同类型的哈希函数及其对召回率和精确度的影响。
本文探讨了近邻搜索中的维数灾难问题,并介绍了使用局部敏感哈希(LSH)来加速搜索的方法。通过将高维数据映射到多个哈希桶中,可以有效地进行精确搜索。此外,还讨论了不同类型的哈希函数及其对召回率和精确度的影响。
对于nearest neighbor search,一个很重要的问题是维数灾难(curse of dimensionality)。 ANN算法是提高搜索速度的一种方法。LSH 是最有名的ANN算法之一。
假设原空间数据$x$是$d$维,常见的做法是用hash函数,$g_i(x)\to\{0,1\}^{d*}$,总共有l个hash函数$g_1..g_l$,因此我们把输入x映射到了${g_1(x),...g_l(x)}$。用此种方法把数据库中的每个元素$x$,映射到$g_1(x)...g_l(x)$ 这 $l$个数值(或向量),就像分别掉到了$l$个桶中一样。每个桶中的数值的规模就比较小。
对于查询数据$q$,我们要从数据库中找到与 $q$最近的元素,于是因为每个桶中的规模小,因此可以用exact search。对数据库中的数据$x$,只要$x$与$q$在一个桶中的值相同,那么$x$是我们要找的点。对于这种查找方法,如果$l$越大,hash函数就越多,那么recall就越高;如果$d*$越大,元素被hash函数映射到的01串的长度越大,precision就越高。
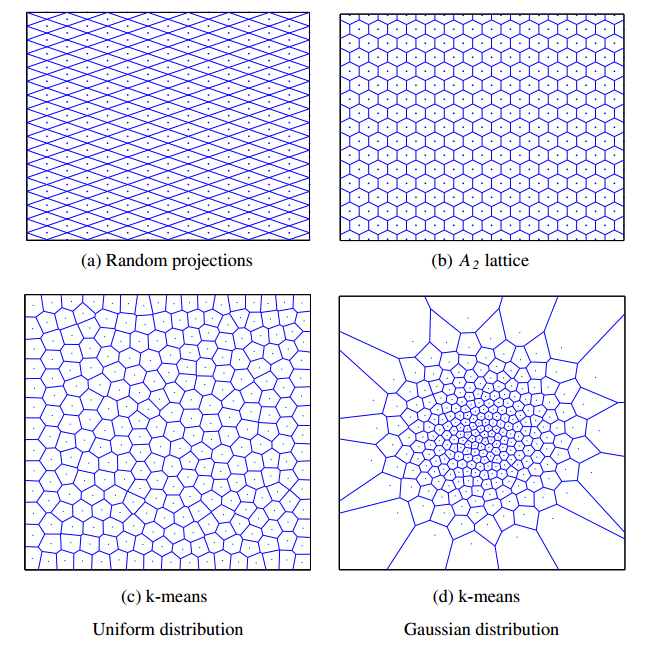
对于hash函数$g_i(x)$的选择有若干种。 上图展示了hash函数为random projection(a), lattice A2(b)和k-means quantizer(c,d)形成的Voronoi regions,每个区域中的所有点的hash后的值都相同。 (a),(b)是structured quantizer,从图中可看出,数据空间的划分是有规律的,这没有考虑数据的分布,因此在数据密的地方,这种划分太大了,在数据稀疏的地方,这种划分太小了。 unstructured quantizer(c),(d)因为考虑了数据的统计,所以从这角度说,这种划分比structured quantizer好。

















 6514
6514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









