






 本文介绍了作者在视频分割领域的实践经验,包括使用Canny算法、GrabCut算法等方法进行边缘检测的效果对比,最终选择了GraphCut算法,并详细阐述了如何通过深度阈值来区分前景与背景。
本文介绍了作者在视频分割领域的实践经验,包括使用Canny算法、GrabCut算法等方法进行边缘检测的效果对比,最终选择了GraphCut算法,并详细阐述了如何通过深度阈值来区分前景与背景。
Recently, I started learning about video segmentation (kinect + openni + opencv). The purpose is to extract foreground from video.
And I have experimented with several ways to make the edges more accurate.
Firstly, I tried to make use of the results of Canny algorithm. However, it is not a very effectual way for the following reasons.
1. The edges are not always continuous;
2. There are some other edges that can disturb the main edges.
Then, I attempted to process the results of Canny, but the efficiency is too low to process video.
So, I turned to use GrabCut algorithm. It has a good effect in image processing, but it is too slow for video processing.
After that, I tried to take advantage of the difference between two adjacent pixels’ color, but result was not good.
Finally, I decided to use GraphCut algorithm, which is faster than GrabCut, and can produce a good result.
Smaller depths are set as foreground, larger depths are set as background, and black areas can be set as background or uncertain areas.
I use depth threshold to distinguish foreground and background.

Figure 1. Calculate threshold (red point), using weighted average
When background area is larger enough, threshold will be larger. And some background will be considered as foreground. So I changed another way to find the subsequent point of the first concentration.
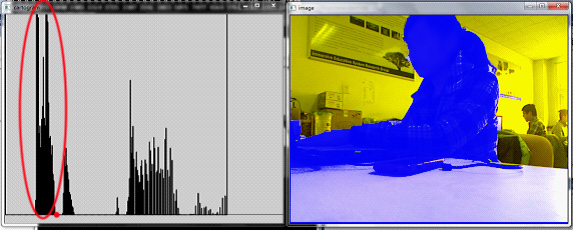
Figure 2. find the subsequent point
If the color of background is similar with foreground at boundaries, background areas will be considered as foreground when black areas are set as uncertain areas, as shown in figure 4.
And when black areas are set as background, there may be some missing part of foreground (as shown in figure 3).
However, if there is a appropriate distance, kinect can capture a more accurate depth images, which will decrease the black area, and produce a better result.
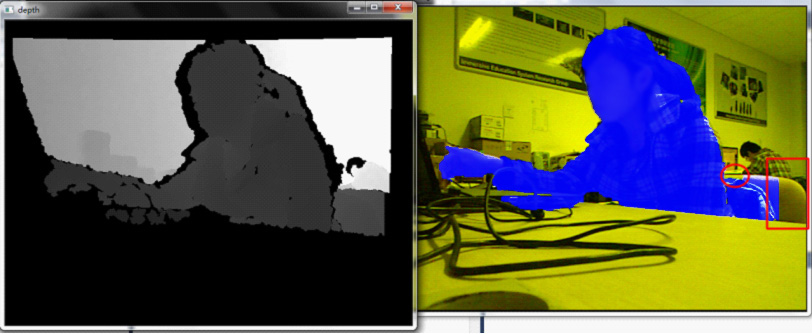
Figure 3. Black areas in depth image are set as background.
(Blue stands for foreground, yellow stands for background)
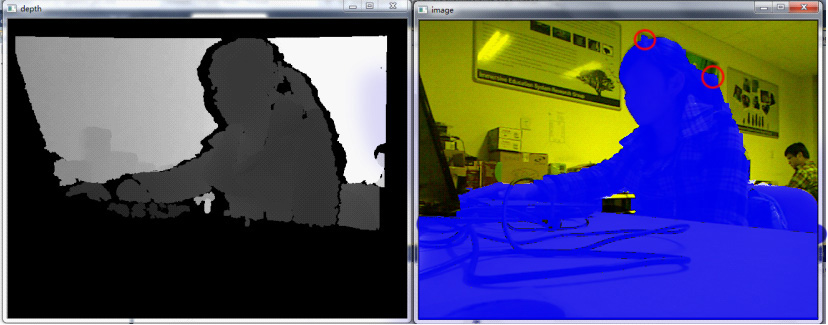
Figure 4. Black areas in depth image are set as uncertain areas.
(Blue stands for foreground, yellow stands for background)
In this way, I can extract the object that is closest to the camera. And then, I will focuse on extracting person.

















 5646
5646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









