



 本文围绕Python展开,介绍了yield实现状态保存与并发假象,指出其局限性。阐述了协程的定义、作用及实现单线程并发的目标,还介绍了greenlet和gevent模块。此外,提及用非阻塞IO模型解决阻塞IO,对比了进程、线程、协程的应用场景,以及select、poll和epoll的区别。
本文围绕Python展开,介绍了yield实现状态保存与并发假象,指出其局限性。阐述了协程的定义、作用及实现单线程并发的目标,还介绍了greenlet和gevent模块。此外,提及用非阻塞IO模型解决阻塞IO,对比了进程、线程、协程的应用场景,以及select、poll和epoll的区别。
主要内容:
1. yeild 实现状态保存
import time
def func():
sum = 0
yield sum
sum = 0
yield sum
sum = 0
yield sum
def fff():
g = func() # 获得一个生成器函数, 并不会执行函数
print('这是在fff函数中')
print(next(g)) # 执行
time.sleep(1)
print('这是在fff函数中')
print(next(g))
time.sleep(1)
print('这是在fff函数中')
print(next(g))
fff()
2 . yield 实现并发的假象
在单线程中, 如果存在多个函数, 如果某个函数存在i/o操作, 想让程序马上切换到另一个函数去执行,以此实现一个假的并发现象.
总结 : yield 只能实现单纯的切换函数和保存函数状态的功能
不能实现: 当某一个函数遇到i/o操作时, 自动的切换到另一个函数去执行, 如果能实现这个功能, 那么每个函数都是一个协程.
但是协程的本质还是主要依靠yield实现的
如果只是拿yield去单纯的实现一个切换的现象, 根本没有程序串行执行效率高.
def consumer():
while 1:
x = yield
# print(x)
def producer():
g = consumer()
next(g)
for i in range(100000000):
g.send(i)
start = time.time()
producer()
print('yield:',time.time() - start)
串行代码:
def consumer(l):
# for i in l:
# print(i)
pass
def producer():
l = []
for i in range(100000000):
l.append(i)
return l
start = time.time()
l = producer()
consumer(l)
print(time.time() - start)
3 . 协程
a : 协程的定义 : 是一个比线程更加轻量级的单位, 是组成线程的各个函数,(单线程下的并发, 又称)
b : 为什么要有协程 因为想要在单线程内实现并发的效果(因为cpython有GIL锁,限制了在同一个时间点,只能执行一个线程. 所以想要在执行一个线程的期间, 充分利用cpu的性能, 所以想在单线程内实现并发的效果)
c : 并发 : 切换 + 保存状态
d : cpu为什么要切换: 1.因为某个程序阻塞了. 2. 因为某个程序用完了时间片(该任务计算的时间过长)
e : 目标 : 所以想要实现单线程的并发, 就要解决在单线程内,多个任务函数中,某个任务函数遇到i/o操作, 马上自动切换到其他任务函数中去执行
协程是用户自己去调度的
3 . greenlet模块
a :定义 能简单的实现函数与函数的切换, 但是遇到i/o操作, 不能自动切换.
b :模块的使用 : 该模块是一个类, switch是类中的一个方法.
注册一下函数func, 将函数注册成一个对象f1 f1 = greenlet(func)
调用func, 使用f1.switch(), 如果函数需要传参, 就在switch这里传参即可.
from greenlet import greenlet
import time
def eat(name):
print('%s吃炸鸡' % name)
time.sleep(1)
f2.switch('lili')
print('%s吃雪糕' % name)
f2.switch()
def drink(name):
print('%s喝啤酒' % name)
time.sleep(1)
f1.switch()
print('%s喝可乐' % name)
f1 = greenlet(eat)
f2 = greenlet(drink)
f1.switch('丽丽')
4. gevent 模块
a : 定义 可以实现在某函数内部遇到io操作,就自动的切换到其他函数内部去执行
b : 模块的使用 : g = gevent.spawn(func,参数) 注册一下函数func,返回一个对象g
gevent.join(g) #等待g指向的函数func执行完毕,如果在执行过程中,遇到IO,就切换
gevent.joinall([g1,g2,g3])#等待g1 g2 g3指向的函数func执行完毕
import gevent
def func1():
print(1)
gevent.sleep(0.5)
print(2)
def func2():
print(3)
gevent.sleep(0.5) #gevent不能识别其他的io操作,只能识别自己的
print(4)
g = gevent.spawn(func1)
g2 = gevent.spawn(func2)
g.join()
g2.join()
解决gevent不能识别其他io操作的问题
import gevent
from gevent import monkey
monkey.patch_all()# 可以让gevent识别大部分常用的IO操作
import time
def func1():
print('1 2 3 4')
time.sleep(1)
print('3 2 3 4')
# gevent.sleep(1)
def func2():
print('2 2 3 4')
time.sleep(1)
print('再来一次')
g1 = gevent.spawn(func1)
g2 = gevent.spawn(func2)
g1.join()# 等待g1指向的任务执行结束
g2.join()
串行与并发的效率对比:
from gevent import monkey
monkey.patch_all()
import gevent
import time
def func(num):
time.sleep(1)
print(num)
start = time.time()
for i in range(10):
func(i)
print('时间', time.time() - start) #10s
if __name__ == '__main__':
li = []
start = time.time()
for i in range(10):
g = gevent.spawn(func, i)
li.append(g)
gevent.joinall(li) # 等待g指向的函数执行完毕.
print('时间',time.time() - start) #1s
爬虫事例 :
from gevent import monkey
import time
import requests
import gevent
def func(url):
re = requests.get(url)
print(url, re.status_code, len(re.text))
url_l = ['http://www.baidu.com',
'https://www.jd.com',
'http://www.taobao.com',
'http://www.qq.com',
'http://www.mi.com',
'http://www.cnblogs.com']
def sync_func(url_l):
for url in url_l:
func(url) #串行执行函数
def async_func(url_l):
li = []
for url in url_l:
g = gevent.spawn(func, url) #使用gevent协程并发去执行任务函数
#当遇到每个网页请求比较大的网络延迟时,自动切换到其他的任务函数.
li.append(g)
gevent.joinall(li) #等待g指向的任务函数执行完.
start = time.time()
sync_func(url_l)
print('使用串行消耗的时间为', time.time() - start)
start = time.time()
async_func(url_l)
print('使用并发消耗的时间为', time.time() - start)
5 . i/o多路复用
a : 用非阻塞io模型去解决阻塞io
import socket
sk = socket.socket()
sk.setblocking(False)
sk.bind(('127.0.0.1',8080))
sk.listen()
l = []
del_l = []
while 1:
try:
conn,addr = sk.accept()# 如果是阻塞IO模型,在这里程序会一直等待。
l.append(conn)# 将每个请求连接的客户端的conn添加到列表中
except BlockingIOError:
for conn in l:# 去遍历所有客户端的conn,看看有没有客户端给我发送数据了
try:
info = conn.recv(1024).decode('utf-8')# 尝试接收,看看有没有客户端给我发数据
if not info:# 如果客户端正常执行了close,服务器会接收到一个空
del_l.append(conn)# 将已经结束的客户端的conn,添加到要删除的列表中
print('客户端正常退出了!')
conn.close()# 因为客户端已经主动close,所以服务器端的conn也要close
else:
print(info)
conn.send(info.upper().encode('utf-8'))
except BlockingIOError:
continue# 是没有接受到客户端发来的数据而报错
except ConnectionResetError:
pass# 是因为客户端强制退出而报错
if del_l:
for conn in del_l:
l.remove(conn)
del_l = []# 在删除完主动关闭的客户端的连接之后,应该把此列表清空,否则报错
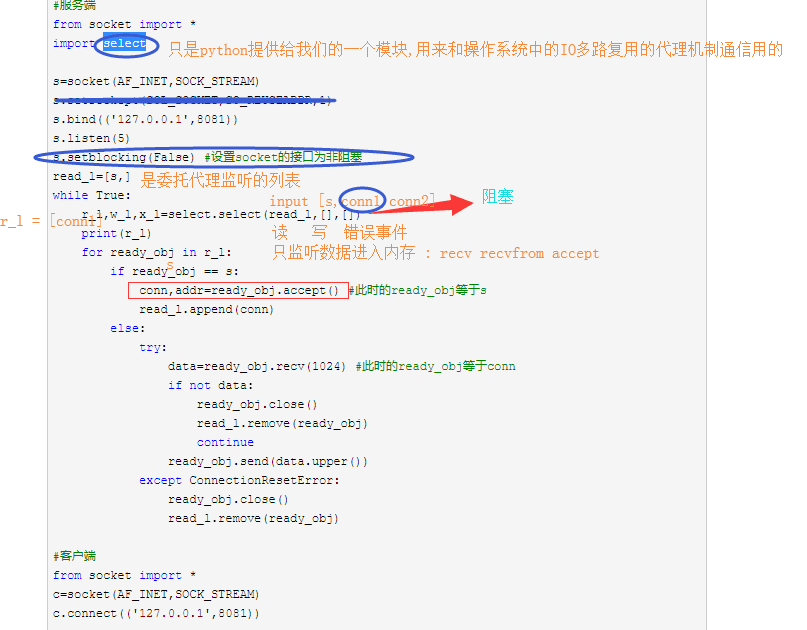
基于select的网络io模型:
import select
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8080))
sk.listen()
del_l = []
rlist = [sk]# 是用来让select帮忙监听的 所有 接口
# select:windows/linux是监听事件有没有数据到来
# poll: linux 也可以做select的工作
# epoll: linux 也可以做类似的工作
while 1:
r,w,x = select.select(rlist,[],[])# 传参给select,当rlist列表中哪个接口有反应,就返回给r这个列表
if r:
for i in r:# 循环遍历r,看看有反应的接口到底是sk 还是conn
if i == sk:
# 如果是sk,那就表示有客户端的连接请求
'''sk有数据要接收,代表着有客户端要来连接'''
conn,addr = i.accept()
rlist.append(conn)# 把新的客户端的连接,添加到rlist,继续让select帮忙监听
else:
# 如果是conn,就表示有客户端给我发数据了
'''conn有数据要接收,代表要使用recv'''
try:
msg_r = i.recv(1024).decode('utf-8')
if not msg_r:
'''客户端执行了close,客户端主动正常关闭连接'''
del_l.append(i)
i.close()
else:
print(msg_r)
i.send(msg_r.upper().encode('utf-8'))
except ConnectionResetError:
pass
if del_l:# 删除那些主动断开连接的客户端的conn
for conn in del_l:
rlist.remove(conn)
del_l.clear()
i/o 多路复用 : 阻塞i/o ; 非阻塞i/o ; 多路复用i/o ; 异步i/o : python实现不了, 但是有tornado框架,天生自带异步.
6 . 知识点总结
1 ) 进程 , 线程, 协程的区别及各自的应用场景
计算密集用多进程, 可以充分利用多核cpu的性能
i/o密集用多线程(注意 , 协程是在单线程的)
多线程和协程的区别:线程由操作系统调度控制的; 协程是由程序员自己调度控制.
2 ) select 和 poll 和epoll 的区别
select和poll有一个共同的机制, 都是采用轮训的方式去询问内核,有没有数据准备好了;
select有一个最大监听事件的限制, 32位机制1024, 6位机制2048
poll 没有 , 理论上poll可以开启无限大, 1G内存大概可以开10w个事件去监听
epoll是最好的, 采用的是回调机制, 解决了select和poll共同存在的问题而且poll可以开启无限多个监听事件.

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









