



 本文介绍了一种简单有效的检测爬虫IP的方法,通过使用特定URL(如http://2018.ip138.com/ic.asp),可以识别并验证代理IP的有效性。文中提供了Python代码示例,展示了如何抓取网页内容并解析代理IP信息。
本文介绍了一种简单有效的检测爬虫IP的方法,通过使用特定URL(如http://2018.ip138.com/ic.asp),可以识别并验证代理IP的有效性。文中提供了Python代码示例,展示了如何抓取网页内容并解析代理IP信息。
实用爬虫-01-检测爬虫的 IP
- 本篇介绍一个识别爬虫 ip 的小实例(教你一招识破无效的 ip 代理)
【注意事项】:
- 1.url 可能会失效(个人感觉,因为它带了一个2018,下面附上链接获取方法)
- 2.当然使用的时候,只需两步:
- (1)把你的爬虫的 url 换成下面的 url,目前是:http://2018.ip138.com/ic.asp
- (2)把 decode() 方法的参数要设置成 'GBK' (默认的 'utf-8' 是不行的)
- 代码 ipQuery.py 文件:https://xpwi.github.io/py/spider/ipQuery.py
# coding: utf-8
# 测爬虫 ip 工具
from urllib import request,error
if __name__ == '__main__':
# 该地址可能会失效,如果失效,请参照:https://www.cnblogs.com/xpwi/p/9610887.html
url = "http://2018.ip138.com/ic.asp"
rsp = request.urlopen(url)
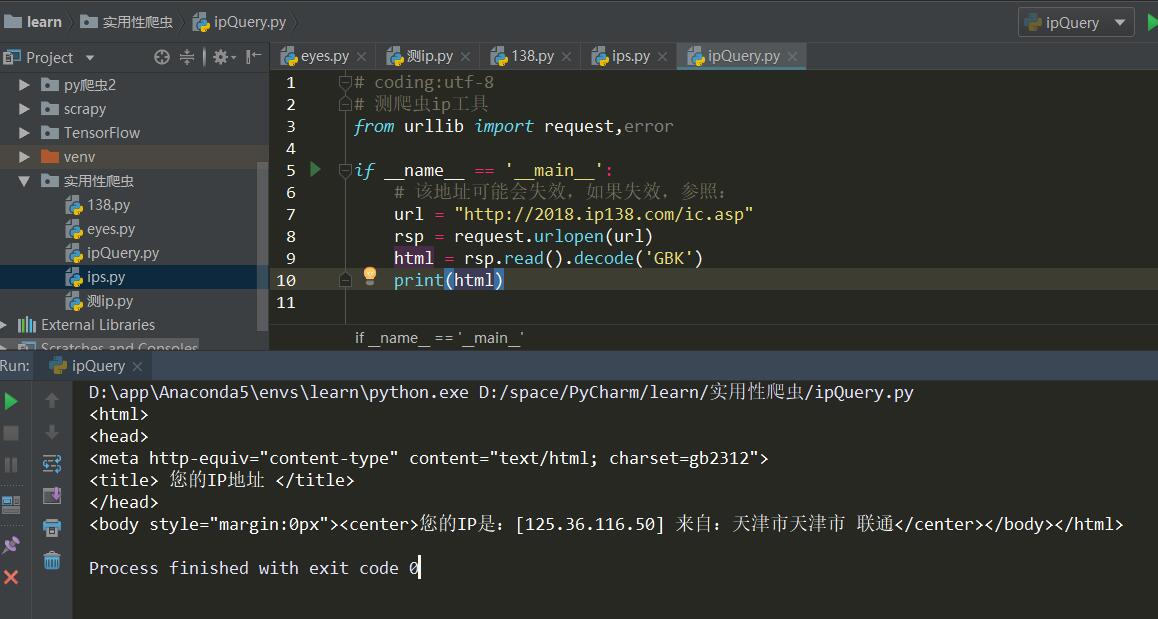
html = rsp.read().decode('GBK')
print(html)运行结果
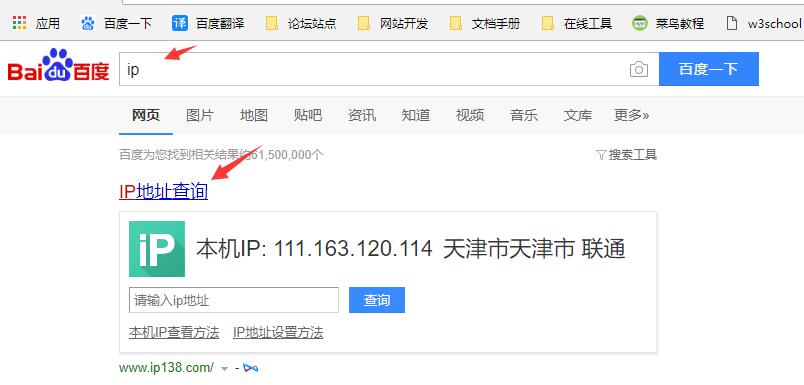
下面介绍怎么获取查询 ip 的地址
- 在百度搜索关键字:ip,点击 IP地址查询
- 或者直接访问:http://www.ip138.com/
- 操作截图:
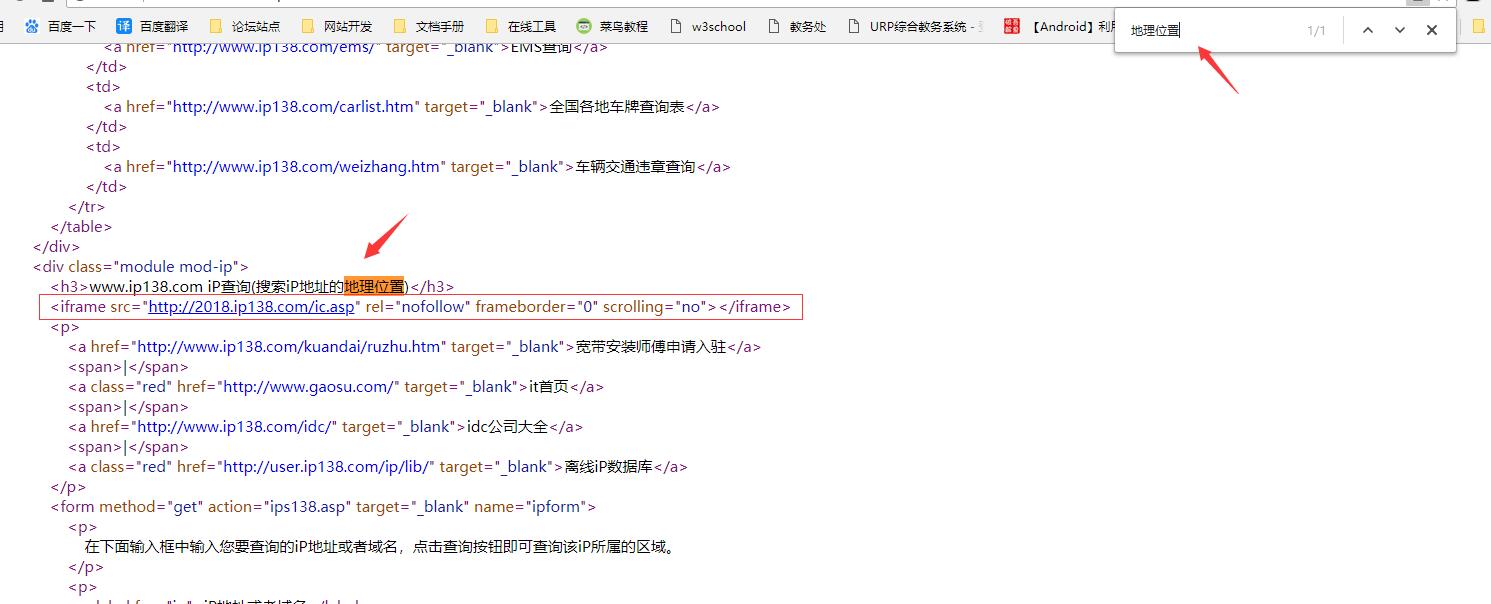
- 右键,点击【查看页面源代码】
- 【搜索】关键字:【地理位置】
- 下面是一个 iframe 标签,地址就在那
更多文章链接:实用爬虫
- 本笔记不允许任何个人和组织转载

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









