



 本文深入探讨了在复杂网络结构中进行网络攻击的策略与计算方法,包括如何通过摧毁特定通道来分裂网络,并计算出成功攻击的方案数量。文章详细介绍了DFS建树、桥边与非桥边的识别,以及在不同情况下如何计算可行的攻击方案,适用于计算机网络安全领域的研究与实践。
本文深入探讨了在复杂网络结构中进行网络攻击的策略与计算方法,包括如何通过摧毁特定通道来分裂网络,并计算出成功攻击的方案数量。文章详细介绍了DFS建树、桥边与非桥边的识别,以及在不同情况下如何计算可行的攻击方案,适用于计算机网络安全领域的研究与实践。
http://acm.timus.ru/problem.aspx?space=1&num=1557
1557. Network Attack
Time limit: 2.0 second
Memory limit: 64 MB
Memory limit: 64 MB
In some computer company, Mouse Inc., there is very complicated network structure. There are a lot of branches in different countries, so the only way to communicate with each other is the Internet. And it's worth to say that interaction is the key to the popularity and success of the Mouse Inc.
The CEO of this company is interested now to figure out whether there is a way to attack and devastate whole structure. Only two hackers are capable to perpetrate such an outrage — Vasya and Petya, who can destroy any two channels. If after that there are at least two servers without connection between them, then they succeed.
In other words, the company is a set of servers, some of them connected with bidirectional channels. It's guaranteed that all the servers are connected directly or indirectly. The hackers' goal is to divide network into at least two parts without any connection between them. Each hacker can destroy exactly one channel. And they can't destroy the same channel together. You are asked to count the number of ways for hackers to win.
Input
There are two integer numbers (
N,
M) in the first line of input: the number of servers and channels respectively (1 ≤
N ≤ 2000; 0 ≤
M ≤ 100000). In the each of the next
M lines there are exactly two numbers — the indices of servers connected by channel. Channels can connect a server to itself. There can be multiple channels between one pair of servers. The servers are numbered from 1 to
N.
Output
There must be exactly one integer — the answer to the question described in the problem.
Sample
| input | output |
|---|---|
3 3 1 2 2 3 3 1 | 3 |
Problem Source: Novosibirsk SU Contest. Petrozavodsk training camp, September 2007
思路:
首先dfs建树,这个时候图就只分为树边和回边,自边(回边+自边=非树边),(没有横边),分隔方案有三种
1:拆除的一条边是桥,另外一条随便,这个用tarjian算法解决,设桥的数量为nb,总边数m,则第一类方案数为(m-nb)*nb+nb*(nb-1)/2
2:拆除两条边后分离出了一棵子树,这时候一定一条边是树边(肯定不是桥边),另外一条是回边,只需要统计一下,设b[s]存储以s为顶点的子树到s的祖先的边数,b[s]==2就有一种方案
3:拆除两条边后分离出了子树的一部分,如图:
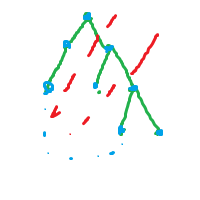 分出中间那部分,剩下两部分可以相连,
分出中间那部分,剩下两部分可以相连,
这就要求中间部分到上面部分(祖先)和下面部分(分出来的子树)间都没有边相连,
明显,毁坏的必须是两条树边,而且不是桥边(需要b[s]>1,b[son]>1)
记录深度数组dfn[],分出来的子树的回边所能到达的最低深度为high[]数组,那么当我们确定要毁坏的是s和父亲的树边时,需要搜寻s有没有满足条件的配对点son来破坏son和其父亲间的树边使得中间部分脱离,此时必须有high[son]<dfn[s],使得上面部分到中间部分没有边,下面部分到中间部分也没有边.
但是注意,中间部分可能有内部的回边,所以要控制b[s]==b[son],使得b[son]和b[s]之间没有未被接收的回边
感想:这题思路似乎很简单,但是一开始考虑的是,设由祖先向节点s的子树连所连的最浅子节点深度为high[s](通过非树边),则第三类点一定在这个点上面,但是这样做的话,无法规避这种情况
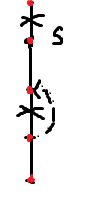
于是,再设一个条件,第三类合格点要满足其深度大于"深度大于s节点的祖先"(s的儿子,合格点的祖先)所能连到的最深深度,不过还是不能过Test#16
最后还是直接使用了上交红书的方法
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <stack>
using namespace std;
typedef long long ll;
const int maxn=2002,maxm=200002;//ATTENTION,undirect
int n,m;
ll ans,nb;
int b[maxn];
int c[maxn];//edge to its father,select and acceed
int first[maxn];
int next[maxm];
bool tree[maxm];
int to[maxm];
int brg[maxm];//bridge
int dfn[maxn],high[maxn],depth;
bool up[maxn][maxn];
void dfs(int s,int aim){
for(int p=first[s];p!=-1;p=next[p]){
if(tree[p]){
dfs(to[p],aim);
}
}
if(c[s]==1&&b[s]==b[aim]&&high[s]<dfn[aim]){
// printf("b:%d %d\n",aim,s);
ans++;
}
// return ans;
}
void addedge(int f,int t,int ind){
next[ind]=first[f];
first[f]=ind;
to[ind]=t;
swap(f,t);ind++;
next[ind]=first[f];
first[f]=ind;
to[ind]=t;
}
void tarjan(int s,int pf){
dfn[s]=++depth;
for(int p=first[s];p!=-1;p=next[p]){
if(s==to[p]){continue;}
if(pf>=0&&to[p]==to[pf^1])c[s]++;
if((p|1)==(pf|1)){b[s]++;continue;}
if(dfn[to[p]]==0){
tree[p]=true;
tarjan(to[p],p);
if(b[to[p]]==1){
brg[nb++]=p;
}
b[s]+=b[to[p]]-1;
for(int i=1;i<=dfn[s];i++){
if(up[to[p]][i])up[s][i]=true;
}
}
else {
if(dfn[to[p]]>dfn[s]){
b[s]--;
}
else {
up[s][dfn[to[p]]]=true;
b[s]++;
}
}
}
high[s]=dfn[to[pf^1]];
for(int i=dfn[to[pf^1]];i>=0;i--){
if(up[s][i]){high[s]=i;break;}
}
if(b[s]==2)ans++;
if(c[s]==1&&b[s]>1){
for(int p=first[s];p!=-1;p=next[p]){
if(tree[p]){
dfs(to[p],s);
}
}
}
}
int main(){
scanf("%d%d",&n,&m);
memset(first,-1,sizeof(first));
for(int i=0;i<m;i++){
int f,t;
scanf("%d%d",&f,&t);
addedge(f,t,2*i);
}
tarjan(1,-1);
ans+=(m-nb)*nb+nb*(nb-1)/2;
printf("%I64d\n",ans);
return 0;
}

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









