






 本文介绍了解决在Oracle数据库中遇到ORA-00392错误的方法,该错误通常发生在尝试使用alter database open resetlogs或upgrade命令时。文章详细说明了错误的背景及一系列解决步骤。
本文介绍了解决在Oracle数据库中遇到ORA-00392错误的方法,该错误通常发生在尝试使用alter database open resetlogs或upgrade命令时。文章详细说明了错误的背景及一系列解决步骤。
alter database open resetlogs或者 alter database open resetlogs upgrade报错:ORA-00392
在rman restore 还原数据文件和recover 恢复数据文件之后,此时数据库处于mounted状态,需要open并resetlogs 。此时resetlogs相当于数据库根据控制文件的redo信息,创建新的redo文件。但是有时open resetlogs报错。
解决步骤:
1:报错查看
2:查看当前日志组状态
3:clear 日志组
4:验证是否报错
5:日志组合日志文件之间的关系
6:日志管理(常用)
解决步骤:
-
报错查看
SQL> alter database open resetlogs upgrade;
alter database open resetlogs upgrade
*
ERROR at line 1:
ORA-00392: log 3 of thread 1 is being cleared, operation not allowed
ORA-00312: online log 3 thread 1: '/u01/oradata/orcl/redo03.log'

-
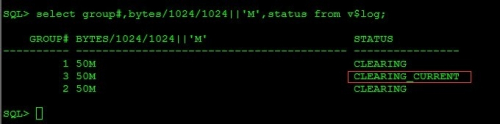
查看当前日志组状态
SQL> select group#,bytes/1024/1024||'M',status from v$log;
GROUP# BYTES/1024/1024||'M' STATUS
---------- ----------------------------------------- ----------------
1 50M CLEARING
3 50M CLEARING_CURRENT
2 50M CLEARING
-
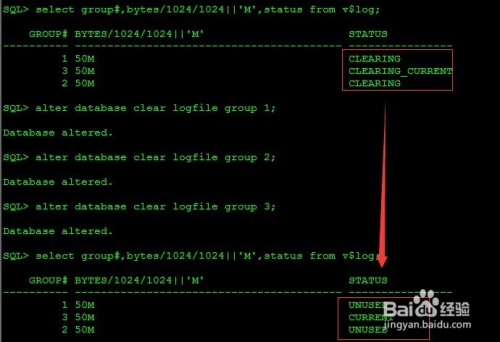
clear 日志组
SQL> alter database clear logfile group 1;
Database altered.
SQL> alter database clear logfile group 2;
Database altered.
SQL> alter database clear logfile group 3;
Database altered.
SQL> select group#,bytes/1024/1024||'M',status from v$log;
GROUP# BYTES/1024/1024||'M' STATUS
---------- ----------------------------------------- ----------------
1 50M UNUSED
3 50M CURRENT
2 50M UNUSED
-
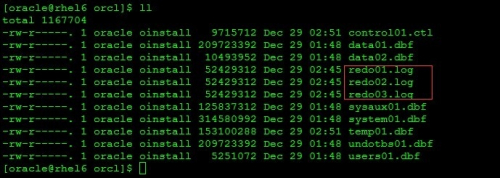
验证是否报错
alter database open resetlogs upgrade;
注意:
执行这条sql的日志文件的物理变化,那就是执行之前目录中还没有日志文件,执行之后,日志文件自动创建

-
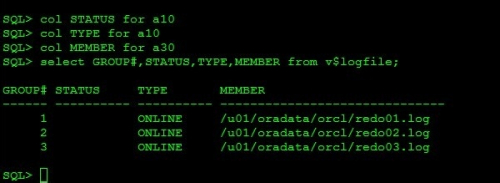
日志组合日志文件之间的关系
SQL> select GROUP#,STATUS,TYPE,MEMBER from v$logfile;
GROUP# STATUS TYPE MEMBER
------ ---------- ---------- ------------------------------
1 ONLINE /u01/oradata/orcl/redo01.log
2 ONLINE /u01/oradata/orcl/redo02.log
3 ONLINE /u01/oradata/orcl/redo03.log
此时每个group组中都有一个member成员
1:每个日志组至少有一个成员,成员之间的关系是镜像关系
2:每个数据库中至少有两个组来回switch切换
-
日志管理(常用)
1:切换日志:alter system switch logfile
2:添加一个日志组
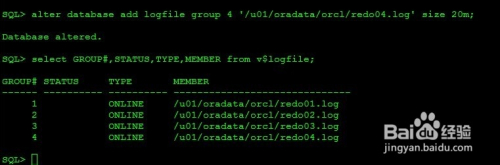
SQL> alter database add logfile group 4 '/u01/oradata/orcl/redo04.log' size 20m;
SQL> select GROUP#,STATUS,TYPE,MEMBER from v$logfile;
GROUP# STATUS TYPE MEMBER
------ ---------- ---------- ------------------------------
1 ONLINE /u01/oradata/orcl/redo01.log
2 ONLINE /u01/oradata/orcl/redo02.log
3 ONLINE /u01/oradata/orcl/redo03.log
4 ONLINE /u01/oradata/orcl/redo04.log
注意:如果没有制定组号,数据库会在创建时自动添加当前最大组号加1
3:添加一个成员
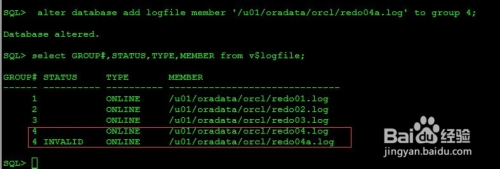
SQL> alter database add logfile member '/u01/oradata/orcl/redo04a.log' to group 4;
SQL> select GROUP#,STATUS,TYPE,MEMBER from v$logfile;
GROUP# STATUS TYPE MEMBER
------ ---------- ---------- ------------------------------
1 ONLINE /u01/oradata/orcl/redo01.log
2 ONLINE /u01/oradata/orcl/redo02.log
3 ONLINE /u01/oradata/orcl/redo03.log
4 ONLINE /u01/oradata/orcl/redo04.log
4 INVALID ONLINE /u01/oradata/orcl/redo04a.log
注意:
1)添加成员不指定大小,镜像关系会自动设置相同大小
2)添加之后处于invalid非正常状态,需要不停的切换日志才能变成正常状态
4:删除一个成员
SQL> alter database drop logfile member '/u01/oradata/orcl/redo04.log';
注意:
1)CURRENT状态不能删除,先切换再删除 alter system switch logfile;
2)ACTIVE有时候能删,有时候不能删,如果删除报错,只能等
5:删除一个日志组
SQL> alter database drop logfile group 3;
注意:
1)CURRENT状态不能删除,先切换再删除 alter system switch logfile;
2)ACTIVE有时候能删,有时候不能删,如果删除报错,只能等
6:清楚报废日志
SQL> alter database clear logfile group 4;
注意:
如果redo04.log文件报废,而且处于非CURRENT状态
 END
END

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









