



 本文介绍了一个Python实现的CNNVD漏洞爬虫程序,通过该程序可以批量爬取指定时间段内的漏洞信息,并将数据整理输出到Excel文件中。文章详细展示了爬虫的各个功能模块,包括代理设置、漏洞链接抓取、数据解析及存储等。
本文介绍了一个Python实现的CNNVD漏洞爬虫程序,通过该程序可以批量爬取指定时间段内的漏洞信息,并将数据整理输出到Excel文件中。文章详细展示了爬虫的各个功能模块,包括代理设置、漏洞链接抓取、数据解析及存储等。
2018年1月26日 16:04:06 更新代码。
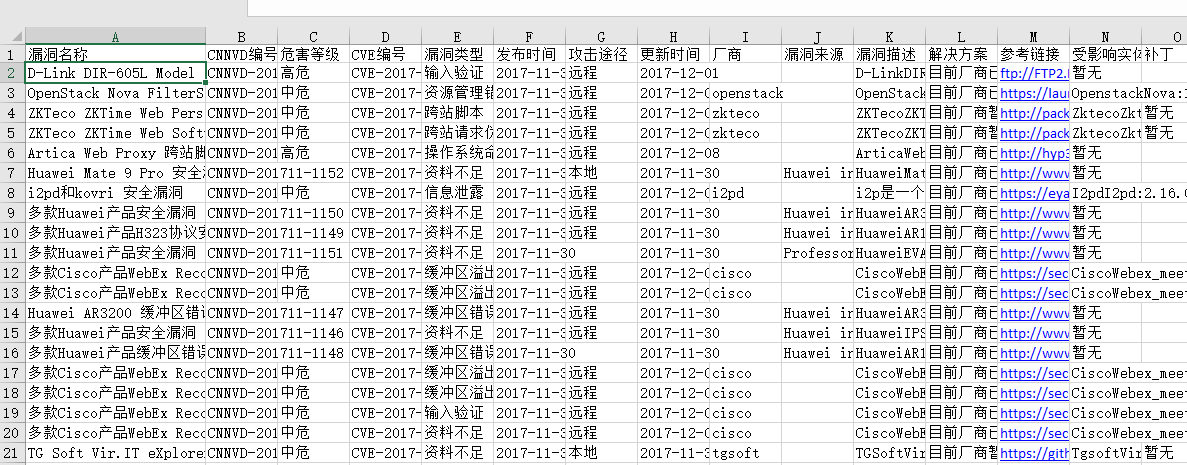
excel结果:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # by 默不知然 # 2017年12月18日 10:01:30 import requests from urllib import parse from bs4 import BeautifulSoup import xlwt import zlib import re import time import xlsxwriter import sys import datetime import random import threadpool ''' 运行方法: python spider_cnnvd.py 2017-10-01 2017-10-31 178 第一个为开始时间,第二个为结束时间,第三个为总页数。 ''' #获取代理,并写入列表agent_lists def agent_list(url): header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'} r = requests.get(url,headers=header) agent_info = BeautifulSoup(r.content,'lxml').find(id="ip_list").find_all('tr')[1:] for i in range(len(agent_info)): info = agent_info[i].find_all('td') agents = {info[5].string : 'http://' + info[1].string} agent_lists.append(agents) #获得漏洞详情链接列表 def vulnerabilities_url_list(url,start_time,end_time): header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0', 'Content-Type': 'application/x-www-form-urlencoded' } data ={ 'qstartdate':'2018-02-01', 'qenddate':'2018-02-01' } data['qstartdate'] = start_time data['qenddate'] = end_time proxy = random.sample(agent_lists,1)[0] vulnerabilities_url_html = requests.post(url,headers=header,proxies=proxy,data=data) vulnerabilities_url_html = vulnerabilities_url_html.content.decode() #提取漏洞详情链接 response = r'href="(.+?)" target="_blank" class="a_title2"' vulnerabilities_link_list = re.compile(response).findall(vulnerabilities_url_html) #添加http前序 i = 0 for link in vulnerabilities_link_list: vulnerabilities_lists.append('http://cnnvd.org.cn'+vulnerabilities_link_list[i]) i+=1 print("已完成爬行第%d个漏洞链接"%i) #漏洞信息爬取函数 def vulnerabilities_data(url): header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'} #proxy = random.sample(agent_lists,1)[0] vulnerabilities_data_html = requests.get(url,headers=header) #,proxies=proxy) vulnerabilities_data_html = vulnerabilities_data_html.content.decode() #global vulnerabilities_result_list vulnerabilities_result_list_eve=[] #抓取信息列表命名 #添加漏洞信息详情 vulnerabilities_detainled_soup1 = BeautifulSoup(vulnerabilities_data_html,'html.parser') vulnerabilities_detainled_data = vulnerabilities_detainled_soup1.find('div',attrs={'class':'detail_xq w770'}) ##定义 漏洞信息详情 块的soup vulnerabilities_detainled_data = vulnerabilities_detainled_data.encode().decode() vulnerabilities_detainled_soup = BeautifulSoup(vulnerabilities_detainled_data,'html.parser') #二次匹配 vulnerabilities_detainled_data_list = vulnerabilities_detainled_soup.find_all('li') #标签a信息汇总 try: vulnerabilities_name = vulnerabilities_detainled_soup.h2.string #漏洞名称 except: vulnerabilities_name = '' vulnerabilities_result_list_eve.append(vulnerabilities_name) try: vulnerabilities_cnnvd_num = vulnerabilities_detainled_soup.span.string #cnnvd编号 vulnerabilities_cnnvd_num = re.findall(r"\:([\s\S]*)",vulnerabilities_cnnvd_num)[0] except: vulnerabilities_cnnvd_num = '' vulnerabilities_result_list_eve.append(vulnerabilities_cnnvd_num) try: #漏洞等级 vulnerabilities_rank = vulnerabilities_detainled_soup.a.decode() vulnerabilities_rank = re.search(u'([\u4e00-\u9fa5]+)',vulnerabilities_rank).group(0) except: vulnerabilities_rank = '' vulnerabilities_result_list_eve.append(vulnerabilities_rank) vulnerabilities_cve_html = vulnerabilities_detainled_data_list[2].encode().decode() #漏洞cve编号 vulnerabilities_cve_soup = BeautifulSoup(vulnerabilities_cve_html,'html.parser') try: vulnerabilities_cve = vulnerabilities_cve_soup.a.string vulnerabilities_cve = vulnerabilities_cve.replace("\r","").replace("\t","").replace("\n","").replace(" ","") except: vulnerabilities_cve = '' vulnerabilities_result_list_eve.append(vulnerabilities_cve) vulnerabilities_type_html = vulnerabilities_detainled_data_list[3].encode().decode() #漏洞类型 vulnerabilities_type_soup = BeautifulSoup(vulnerabilities_type_html,'html.parser') try: vulnerabilities_type = vulnerabilities_type_soup.a.string vulnerabilities_type = vulnerabilities_type.replace("\r","").replace("\t","").replace("\n","").replace(" ","") except: vulnerabilities_type = '' vulnerabilities_result_list_eve.append(vulnerabilities_type) vulnerabilities_time_html = vulnerabilities_detainled_data_list[4].encode().decode() #发布时间 vulnerabilities_time_soup = BeautifulSoup(vulnerabilities_time_html,'html.parser') try: vulnerabilities_time = vulnerabilities_time_soup.a.string vulnerabilities_time = vulnerabilities_time.replace("\r","").replace("\t","").replace("\n","") except: vulnerabilities_time = '' vulnerabilities_result_list_eve.append(vulnerabilities_time) vulnerabilities_attack_html = vulnerabilities_detainled_data_list[5].encode().decode() #威胁类型 vulnerabilities_attack_soup = BeautifulSoup(vulnerabilities_attack_html,'html.parser') try: vulnerabilities_attack = vulnerabilities_attack_soup.a.string vulnerabilities_attack = vulnerabilities_attack.replace("\r","").replace("\t","").replace("\n","") except: vulnerabilities_attack = '' vulnerabilities_result_list_eve.append(vulnerabilities_attack) vulnerabilities_update_html = vulnerabilities_detainled_data_list[6].encode().decode() #更新时间 vulnerabilities_update_soup = BeautifulSoup(vulnerabilities_update_html,'html.parser') try: vulnerabilities_update = vulnerabilities_update_soup.a.string vulnerabilities_update = vulnerabilities_update.replace("\r","").replace("\t","").replace("\n","") except: vulnerabilities_update = '' vulnerabilities_result_list_eve.append(vulnerabilities_update) vulnerabilities_firm_html = vulnerabilities_detainled_data_list[7].encode().decode() #厂商 vulnerabilities_firm_soup = BeautifulSoup(vulnerabilities_firm_html,'html.parser') try: vulnerabilities_firm = vulnerabilities_firm_soup.a.string vulnerabilities_firm = vulnerabilities_firm.replace("\r","").replace("\t","").replace("\n","") except: vulnerabilities_firm = '' vulnerabilities_result_list_eve.append(vulnerabilities_firm) vulnerabilities_source_html = vulnerabilities_detainled_data_list[8].encode().decode() #漏洞来源 vulnerabilities_source_soup = BeautifulSoup(vulnerabilities_source_html,'html.parser') try: vulnerabilities_source = vulnerabilities_source_soup.a.string vulnerabilities_source = vulnerabilities_source.replace("\r","").replace("\t","").replace("\n","") except: vulnerabilities_source = '' vulnerabilities_result_list_eve.append(vulnerabilities_source) #添加漏洞简介详情 vulnerabilities_title_html = vulnerabilities_detainled_soup1.find('div',attrs={'class':'d_ldjj'}) #定义 漏洞简介 块的soup vulnerabilities_title_html = vulnerabilities_title_html.encode().decode() vulnerabilities_title_soup2 = BeautifulSoup(vulnerabilities_title_html,'html.parser') try: vulnerabilities_titles1 = vulnerabilities_title_soup2.find_all(name='p')[0].string vulnerabilities_titles2 = vulnerabilities_title_soup2.find_all(name='p')[1].string vulnerabilities_titles = vulnerabilities_titles1 + vulnerabilities_titles2 vulnerabilities_titles = vulnerabilities_titles.replace(' ','').replace('\t','').replace('\r','').replace('\n','') except: vulnerabilities_titles = '' vulnerabilities_result_list_eve.append(vulnerabilities_titles) #漏洞公告 vulnerabilities_notice_html = vulnerabilities_detainled_soup1.find('div',attrs={'class':'d_ldjj m_t_20'}) #定义 漏洞公告 块的soup vulnerabilities_notice_html = vulnerabilities_notice_html.encode().decode() vulnerabilities_notice_soup2 = BeautifulSoup(vulnerabilities_notice_html,'html.parser') try: vulnerabilities_notice1 = vulnerabilities_notice_soup2.find_all(name='p')[0].string vulnerabilities_notice2 = vulnerabilities_notice_soup2.find_all(name='p')[1].string vulnerabilities_notice = vulnerabilities_notice1+vulnerabilities_notice2 vulnerabilities_notice = vulnerabilities_notice.replace('\n','').replace('\r','').replace('\t','') except: vulnerabilities_notice = '' vulnerabilities_result_list_eve.append(vulnerabilities_notice) #参考网址 vulnerabilities_reference_html = vulnerabilities_detainled_soup1.find_all('div',attrs={'class':'d_ldjj m_t_20'})[1] #定义 参考网址 块的soup vulnerabilities_reference_html = vulnerabilities_reference_html.encode().decode() vulnerabilities_reference_soup2 = BeautifulSoup(vulnerabilities_reference_html,'html.parser') try: vulnerabilities_reference = vulnerabilities_reference_soup2.find_all(name='p')[1].string vulnerabilities_reference = vulnerabilities_reference.replace('\n','').replace('\r','').replace('\t','').replace('链接:','') except: vulnerabilities_reference = '' vulnerabilities_result_list_eve.append(vulnerabilities_reference) #受影响实体 vulnerabilities_effect_html = vulnerabilities_detainled_soup1.find_all('div',attrs={'class':'d_ldjj m_t_20'})[2] #定义 受影响实体 块的soup vulnerabilities_effect_html = vulnerabilities_effect_html.encode().decode() vulnerabilities_effect_soup2 = BeautifulSoup(vulnerabilities_effect_html,'html.parser') try: vulnerabilities_effect = vulnerabilities_effect_soup2.find_all(name='p')[0].string vulnerabilities_effect = vulnerabilities_effect.replace('\n','').replace('\r','').replace('\t','').replace(' ','') except: try: vulnerabilities_effect = vulnerabilities_effect_soup2.find_all(name='a')[0].string vulnerabilities_effect = vulnerabilities_effect.replace('\n','').replace('\r','').replace('\t','').replace(' ','') except: vulnerabilities_effect = '' vulnerabilities_result_list_eve.append(vulnerabilities_effect) #补丁 vulnerabilities_patch_html = vulnerabilities_detainled_soup1.find_all('div',attrs={'class':'d_ldjj m_t_20'})[3] #定义 补丁 块的soup vulnerabilities_patch_html = vulnerabilities_patch_html.encode().decode() vulnerabilities_patch_soup2 = BeautifulSoup(vulnerabilities_patch_html,'html.parser') try: vulnerabilities_patch = vulnerabilities_patch_soup2.find_all(name='p')[0].string vulnerabilities_patch = vulnerabilities_patch.replace('\n','').replace('\r','').replace('\t','').replace(' ','') except: vulnerabilities_patch = '' vulnerabilities_result_list_eve.append(vulnerabilities_patch) for i in vulnerabilities_result_list_eve: vulnerabilities_result_list.append(i) print (re.findall(r'CNNVD-[\s+\S+]+',url)[0]) #漏洞信息写入excel def vulnerabilities_excel(excel): workbook = xlsxwriter.Workbook('spider_cnnvd.xlsx') worksheet = workbook.add_worksheet() row = 0 col = 0 worksheet.write(row,0,'漏洞名称') worksheet.write(row,1,'CNNVD编号') worksheet.write(row,2,'危害等级') worksheet.write(row,3,'CVE编号') worksheet.write(row,4,'漏洞类型') worksheet.write(row,5,'发布时间') worksheet.write(row,6,'攻击途径') worksheet.write(row,7,'更新时间') worksheet.write(row,8,'厂商') worksheet.write(row,9,'漏洞来源') worksheet.write(row,10,'漏洞描述') worksheet.write(row,11,'解决方案') worksheet.write(row,12,'参考链接') worksheet.write(row,13,'受影响实体') worksheet.write(row,14,'补丁') row = 1 n = 0 while n < len(excel): worksheet.write(row,col,excel[n]) worksheet.write(row,col+1,excel[n+1]) worksheet.write(row,col+2,excel[n+2]) worksheet.write(row,col+3,excel[n+3]) worksheet.write(row,col+4,excel[n+4]) worksheet.write(row,col+5,excel[n+5]) worksheet.write(row,col+6,excel[n+6]) worksheet.write(row,col+7,excel[n+7]) worksheet.write(row,col+8,excel[n+8]) worksheet.write(row,col+9,excel[n+9]) worksheet.write(row,col+10,excel[n+10]) worksheet.write(row,col+11,excel[n+11]) worksheet.write(row,col+12,excel[n+12]) worksheet.write(row,col+13,excel[n+13]) worksheet.write(row,col+14,excel[n+14]) row += 1 n += 15 workbook.close()def main():
agent_lists=[]
vulnerabilities_lists=[]
vulnerabilities_result_list = [] #获取代理 for i in range(1,2): url='http://www.xicidaili.com/nn/'+str(i) agent_list(url) #调用漏洞列表函数并获得漏洞链接列表 begin = datetime.datetime.now() page_count = sys.argv[3] j = 1 page_count = int(page_count) start_time = sys.argv[1] end_time = sys.argv[2] while j<=page_count: try: holes_url = 'http://cnnvd.org.cn/web/vulnerability/queryLds.tag?pageno=%d&repairLd='%j vulnerabilities_url_list(holes_url,start_time,end_time) print("已完成爬行第%d页"%j) print('\n') j+=1 except: print('爬取失败,更换代理重新爬取。') time.sleep(10) global bi bi = 0 pool = threadpool.ThreadPool(5) requests = threadpool.makeRequests(vulnerabilities_data,vulnerabilities_lists) [pool.putRequest(req) for req in requests] pool.wait() #漏洞信息写入excel vulnerabilities_excel(vulnerabilities_result_list) #爬行结束 end = datetime.datetime.now() total_time = end - begin print ('漏洞信息爬取结束') print ('爬行漏洞数量: ',len(vulnerabilities_lists)) print ('爬行时间: ',total_time) if __name__ == '__main__': main()

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









