 鸢尾花数据集处理
鸢尾花数据集处理




 本文详细介绍使用Python的scipy、numpy和sklearn库对鸢尾花数据集进行的多种数据处理操作,包括数据集的加载、数据类型的检查、特征与类别的提取、特定属性的选择以及数据的分类整理。
本文详细介绍使用Python的scipy、numpy和sklearn库对鸢尾花数据集进行的多种数据处理操作,包括数据集的加载、数据类型的检查、特征与类别的提取、特定属性的选择以及数据的分类整理。
|
1
2
3
4
5
6
|
<br><br># 1. 安装scipy,numpy,sklearn包import numpyfrom sklearn.datasets import load_iris# 2. 从sklearn包自带的数据集中读出鸢尾花数据集dataprint(data.data) |

|
1
2
3
|
# 3.查看data类型,包含哪些数据data = load_iris()print(data.keys()) |

|
1
2
3
4
|
# 4.取出鸢尾花特征和鸢尾花类别数据,查看其形状及数据类型print(data.target_names)print(data.target)type(data.target) |

|
1
2
|
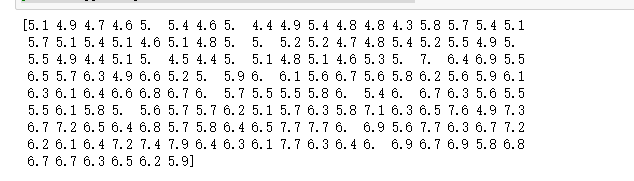
# 5.取出所有花的花萼长度(cm)的数据print(numpy.array(list(len[0] for len in data['data']))) |
|
1
2
3
|
# 6.取出所有花的花瓣长度(cm)+花瓣宽度(cm)的数据print(numpy.array(list(len[2] for len in data['data'])) )print(numpy.array(list(len[3] for len in data['data']))) |

|
1
2
3
|
# 7.取出某朵花的四个特征及其类别。print(data.data[0])print(data.target_names[0]) |

|
1
2
3
4
|
# 8.将所有花的特征和类别分成三组,每组50个setosa_data = []versicolor_data = []virginica_data = [] |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 9.生成新的数组,每个元素包含四个特征+类别for i in range(0,150): #生成为setosa类的鸢尾花花数据 if data.target[i] == 0: data1 = data.data[i].tolist() data1.append('setosa') setosa_data.append(data1) #生成为versicolor类的鸢尾花数据 elif data.target[i] == 1: data1 = data.data[i].tolist() data1.append('versicolor') versicolor_data.append(data1) #剩下的为virginica类的鸢尾花数据 else: data1 = data.data[i].tolist() data1.append('virginica') virginica_data.append(data1)#生成新的数组,每个元素包含四个特征+类别newdata=(setosa_data ,versicolor_data,virginica_data)print(newdata) |


















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









